

1. 서 론
2. 기계학습 알고리즘
2.1 의사결정트리
2.2 앙상블 기법: 배깅
2.3 앙상블 기법: 부스팅
2.4 서포트벡터머신
3. 기계학습 모델의 데이터세트 구성
3.1 현장 개요 및 지반 정보
3.2 데이터세트 구성
4. 분석 결과
4.1 성능평가와 하이퍼파라미터 결정
4.2 학습 결과
4.3 학습 결과를 활용한 예측
5. 결 론
1. 서 론
쉴드 TBM (Tunnel Boring Machine)은 굴착 안정성과 소음 및 진동감소 등의 장점으로 인해, 전 세계적으로 도심지 터널과 하․해저터널에서 널리 사용되고 있다. 쉴드 TBM은 굴진에서 세그먼트 설치에 이르기까지 유기적인 기계장치의 연결이 이루어지는 장비로서, 자동화에 대한 요구가 크며 이미 부분적인 자동화가 진행되고 있다. 특히, 최근 기계 기술의 발달, 컴퓨팅 파워의 향상, AI기술의 적용확대 등에 따라 다양한 분야의 연구가 진행되고 있다. 대표적으로 안정성과 경제성을 향상시키기 위해 굴진 시 획득한 데이터를 다양한 인공지능 기법으로 분석하여 토압식 쉴드 TBM의 굴진성능을 예측한 연구(Armaghani et al., 2017, Kang et al., 2020, Mokhtari and Mooney, 2020)들을 들 수 있다. 또한 다양한 기계학습 모델을 활용하여 TBM의 기계데이터에 암석의 일축압축강도, RQD, RMR 등을 활용한 암반특성 분류 연구(Ayawah et al., 2022, Kang et al., 2021)와 토사 지반의 N값을 활용한 쉴드 TBM 굴진 대상 지반분류에 대한 연구가 이루어졌다(Kang et al., 2022b, Kang et al., 2023, Yang et al., 2022). 이외에도 지반 조건별로 디스크커터의 마모와 교체시기를 예측하기 위해 서포트 벡터 머신(Support Vector Machine, SVM), 최근접 이웃(Nearest Neighbors) 알고리즘, 의사결정트리(Decision Tree) 알고리즘 등의 다양한 머신러닝 분류기법을 적용한 연구(La et al., 2019, Kim et al., 2020, Kang et al., 2022a)와 쉴드 TBM 굴진에 따른 침하 예측에 관한 연구(Chen et al., 2019, Kim et al., 2022)들이 수행되었다.
쉴드 TBM에 의한 터널 공사 중에 높은 안전성을 확보하면서 공사기간과 공사비용을 최적화하기 위해서는 공사 전에 적용 대상 지반에 적합한 장비를 선택하고 시공조건에 따라 장비 운전을 최적화하는 것이 필요하다. 이를 위해 쉴드 TBM의 운전 매개변수들을 선택하고 조절하는 것이 매우 중요한 작업이나, 이에 대한 관련 연구는 부족한 것이 현실이다. 지금까지 실제 현장에서는 운전자(operator)가 개인적인 경험과 판단에 따라 운전 매개변수를 제어하고 있는 것이 현실이다. 최근 들어 TBM의 굴진 성능을 향상시키기 위해 운전자를 대상으로 한 사전 교육과 훈련에 대한 중요성이 지적되고 있고(McClellan, 2020), 운영 매개변수 간의 상관관계와 다중회귀분석을 활용하여 토압식 쉴드 TBM 시뮬레이터의 운영 모델을 제시한 연구(Park et al., 2021)가 수행되었으나 분석 대상 운전 매개변수와 관련 데이터의 개수에 한계가 있다.
따라서 본 연구에서는 TBM 시뮬레이터 운영 모델의 개선과 향후 쉴드 TBM의 자동 운전을 위한 기초연구로서, 이수식 쉴드 TBM 굴진 현장의 지반 조건과 굴진 데이터 간의 영향 분석을 실시하고 굴진 중에 생성된 기계 데이터와 지반 데이터를 대상으로 최근 다양한 분야에 널리 활용되고 있는 기계학습 회귀 모델들을 적용하여, 이수식 쉴드 TBM의 대표적인 운전 변수인 총 추력(total thrust force), 커터헤드 토크(cutterhead torque), 막장압(face pressure), 배니유량(slurry discharge)에 대한 예측 모델을 제시하고자 하였다.
2. 기계학습 알고리즘
본 연구에서는 쉴드 TBM에서 얻어진 기계 데이터와 지반 데이터를 분석하기 위하여, 목표변수(target)를 레이블(label)지정하고 훈련 데이터(training dataset)를 이용해 학습을 진행하는 지도학습(supervised learning) 기반의 알고리즘을 사용하였다. 특히, 이수식 쉴드 TBM 장비의 운영 변수를 예측하기 위하여 회귀 기법을 사용하였다. 기계학습 기법에는 많은 알고리즘이 있지만, 기본적인 알고리즘인 의사결정트리 기법, 알고리즘의 결합을 통해 학습결과를 향상시킨 앙상블 기법인랜덤 포레스트(Random Forest)와 그래디언트 부스팅(Gradient Boosting Machine, GBM), 그리고 마진(margin)의 최대화를 통해 구조적으로 위험을 최소화하는 기법인 서포트 벡터 머신을 사용하여 학습을 수행하였다. 이상의 각 기법들을 정리하면 다음과 같다.
2.1 의사결정트리
의사결정트리(Decision Tree Analysis)는 주어진 데이터를 분류하고 규칙을 찾는 방법이다. 트리 기반으로 가지를 분리하여 변수를 구분하고 영역 만들어 클래스 값을 구한다. 의사결정트리 기법은 연속형 또는 범주형 변수에 모두 사용 가능하고 차원 축소나 변수 선택 등 의사결정 생성과정을 통해 많은 변수 중에서 종속변수에 미치는 상대적인 영향을 파악 할 수 있다(Breiman et al., 1984). 트리기법은 그룹별로 특징을 발견하거나 어느 집단에 속하는지 여부를 파악하여 세분화하는 데 효과적인 기법이다. 변수의 정규화나 표준화 같은 전처리가 필요하지 않으며, 특정 변수의 값이 누락되어도 사용이 가능하나, 학습데이터에 과대 적합되는 특징 때문에 새로운 데이터에 적용하면 예측 성능이 좋지 않아 일반화가 어렵다는 단점이 있다.
2.2 앙상블 기법: 배깅
의사결정트리 모델의 단점을 해결하고 더 좋은 예측 성능을 위해서 개발된 알고리즘이 앙상블 모델(Ensemble Learning Method)이다. 앙상블 모델은 의사결정트리를 기반으로 서로 다른 분류 알고리즘 모델을 생성하고 결합하여 새로운 규칙을 만들어 최적의 결과로 분류하는 방향으로 진행하는 방법으로서, 대표적인 앙상블 기법에는 부스팅(Boosting)과 배깅(Bagging 또는 Bootstrap Aggregating) 모델이 있다. Breiman(1996)에 의해 제안된 배깅은 중복 샘플을 활용하여 다양하게 학습하여 단일 혹은 여러 모델을 병렬적으로 사용하는 모델로서 대표적으로 랜덤 포레스트를 들 수 있다.
2.3 앙상블 기법: 부스팅
배깅 모델과는 다르게 Kearns and Valiant(1994)가 처음으로 제안한 부스팅기법은 단일 모델을 활용하여 순차적으로 학습하고 발생하는 오차를 보완하기 위해 다음 분류기에 가중치를 부여하고 다시 학습을 진행하는 방식이다. Friedman(2001)이 소개한 그래디언트 부스팅(GBM)은 경사하강법으로 가중치를 구해서 최적화된 결과를 얻는 대표적인 부스팅 기법이며, Light GBM은 그래디언트 부스팅 알고리즘의 일종으로서 히스토그램 기반의 알고리즘을 사용하여 학습속도가 빠르고 효율성이 높으며 알고리즘의 수직 확장 방식을 사용하여 복잡한 모델을 만들고 정확도를 향상시킬 수 있다는 장점을 가지고 있다(Ke et al., 2017).
2.4 서포트벡터머신
패턴 인식과 자료 분석 등에서 자주 활용되는 서포트 벡터 머신(Support Vector Machine, SVM)은 기계학습 모델로서 Vapnik(1995)이 처음 제안하였다. 학습자료 특성이 변수들로 표현된다고 할 때, 학습 샘플 자료들을 n차원의 데이터 공간에 분포시키고 이를 구분하는 최적의 경계를 찾아내는 알고리즘이다. 서포트 벡터의 원리는 데이터들이 가장 가까운 포인트로 이루어진 결정경계 사이의 거리를 의미하는 마진을 가지게 되는데, 그중에서 최대 마진을 갖는 결정경계를 찾는 것이다. 서포트 벡터 머신의 분류는 일정한 마진 오류 안에서 데이터 클래스를 구분하는 폭이 가장 최대가 되도록 하는 경계를 찾는 것이 목표이다.
3. 기계학습 모델의 데이터세트 구성
3.1 현장 개요 및 지반 정보
본 연구에서 기계학습의 데이터 구성에 활용된 정보는 터널 대상 구간의 지반정보, 노선정보 및 쉴드 TBM의 기계 데이터이다. 본 연구에서는 한강 하저를 관통하는 이수식 쉴드 TBM 터널 현장에서 굴진자료를 수집하였고, 터널 설계 시에 작성된 지반조사보고서와 터널 종단면도를 수집하여 지반정보를 분석하였다.
이상의 현장에서 기계 데이터를 획득한 이수식 쉴드 TBM 장비의 주요 제원은 Table 1과 같다. 쉴드 TBM의 직경은 7.3 m이고, 최대 추력, 최대 커터헤드 토크 및 커터헤드 최대 회전속도는 각각 56.0 MN, 5.33 MN·m 및 3.60 rev/min이다. 굴진 데이터의 분석 결과, 해당 현장에서 사용된 추력과 커터헤드 토크의 평균은 각각 21.20 MN 및 1.26 MN·m으로서 최대 사양의 약 37.9% 및 23.7 %에 해당함을 확인하였다. 쉴드 TBM의 평균 및 최대 굴진속도는 15.1 mm/min 및 22.0 mm/min이었으며, 굴진 중에 사용된 쉴드잭은 평균 약 24개이며 커터헤드의 평균 회전속도는 3.15 rev/min로 분석되었다.
Table 1.
Summary of Slurry TBM specification
설계 시에 시행된 지반조사에서 쉴드 TBM 터널 구간에 대해 총 72공의 시추가 이루어졌으며, 본 연구에서는 시추 시료에 대해 수행된 암석 물성 시험 결과를 활용하여 분석을 실시하였다. 연구 대상 쉴드 터널 구간의 암반 구성은 연암파쇄대가 12%, 연암이 23%, 경암이 65%이었으며, RQD는 25 이하가 24%, 25~50가 30%, 50 이상이 46%로 나타났다. 암석 시험 결과, 암석의 일축압축강도는 22.0~116.0 MPa로서 대체로 양호한 암반이 분포하는 것으로 분석되었다(Fig. 1). 본 연구에서는 암반의 특성을 나타내는 지반정보로서, 심도별 특성을 확인할 수 있는 RQD, TCR, 평균 절리 간격, 그리고 굴진 대상 암석의 강도특성으로서 일축압축강도와 탄성파속도를 학습을 위한 지반정보로 사용하였다(Table 2).
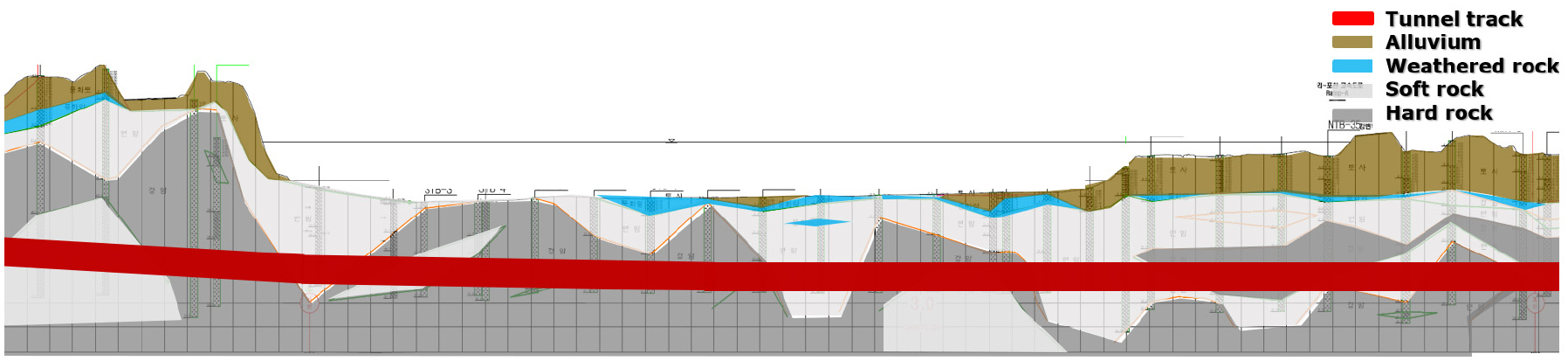
Table 2.
Statistical description of the database
3.2 데이터세트 구성
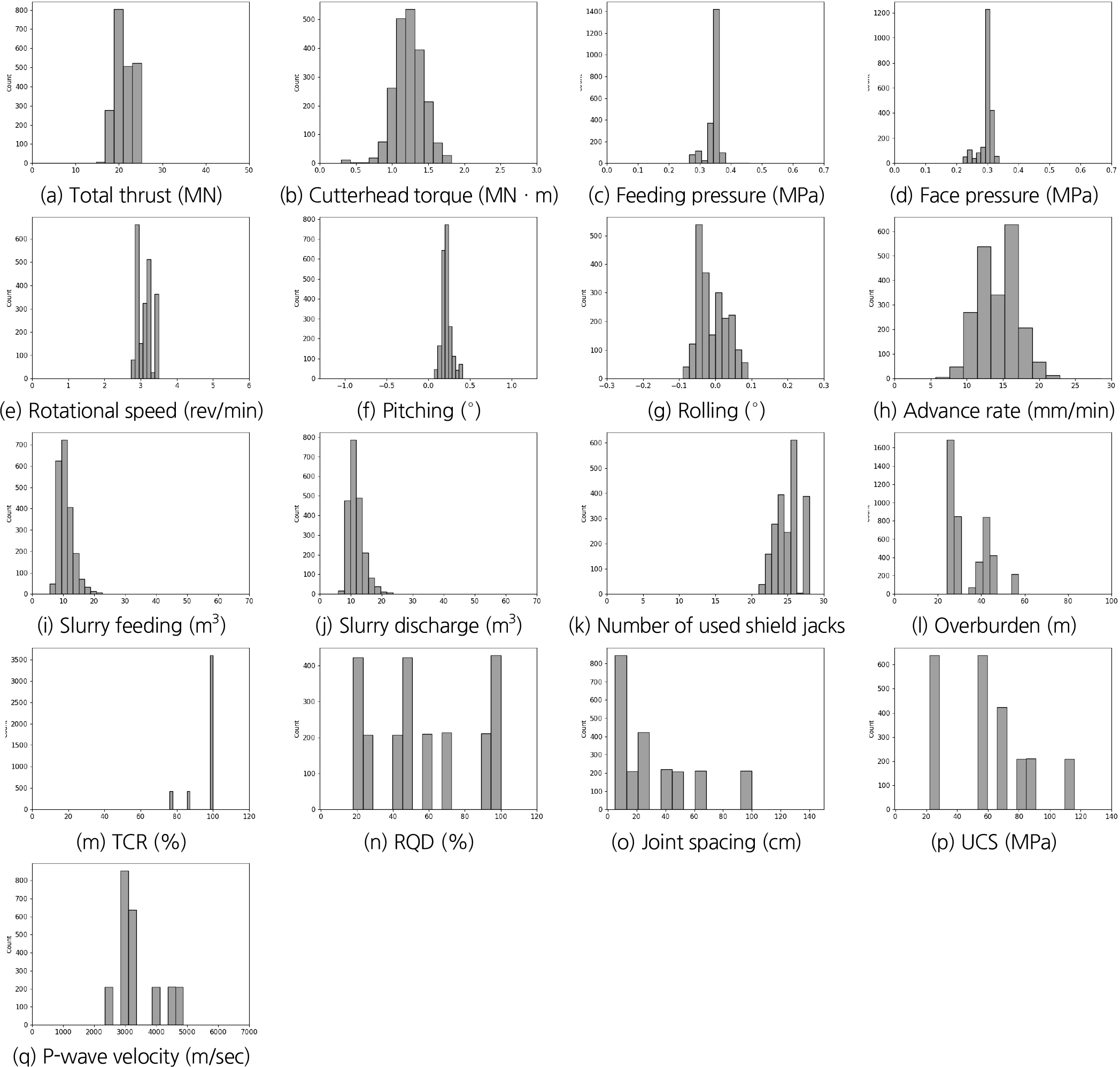
본 연구에서 기계학습 데이터의 분석에 사용된 주요 데이터의 통계학적 특성과 데이터 항목 별 분포 특성을 정리하면 Fig. 2 및 Table 2와 같다.
본 연구에서 수집된 이수식 쉴드 TBM의 장비 상세정보, 굴진/기계 데이터 및 지반조사결과를 분류하면 크게 장비제어 항목(총 추력, 커터헤드 토크, 커터헤드 회전속도, 굴진속도, 이수압, 막장압, 송ㆍ배니 유량), 위치제어 항목(피칭, 롤링, 카피커터 위치, 좌표정보 등), 지반정보(RQD, TCR, 일축압축강도, 평균 절리간격 등) 및 기타항목(첨가제, 폼제, 폴리머, 뒷채움재료, 벤토나이트, 세그먼트 타입, 굴진거리, 그리스)으로 구분된다.
이수식 쉴드 TBM에서는 압력 관련 변수, 속도 관련 변수, 온도 관련 변수, 위치/방향 관련 변수, 굴진 시간 이력 관련 변수 등 광범위한 기계 데이터가 수천~수만 개 생성될 수 있기 때문에, TBM의 굴진 데이터를 기반으로 정확하고 효과적인 기계학습 예측을 위해서는 목표에 적합한 특성 변수를 선택하고 선택된 데이터를 처리하는 것이 무엇보다 중요하다.
따라서 본 연구에서는 굴진 데이터에서 이수식 쉴드 TBM의 운전 변수와 무관한 다양한 전압 측정값, 계측 온도, 위치 및 자세 정보와 같은 특성 변수들을 분석에서 제외하였다. 그리고, 이수식 쉴드 TBM의 주요 운전 변수에서 설정값 및 입력 변수인 커터헤드 회전속도, 이수압, 이수밀도, 송니유량, 사용 쉴드잭수 등을 제외하고 이수식 쉴드 TBM의 주요 출력변수인 총추력, 커터헤드 토크, 송니압, 막장압를 목표 변수로 선정하였다. 그 다음에 쉴드 TBM의 운전 변수를 예측하기 위하여 주요 기계데이터인 총 추력, 커터헤드 토크, 송니압, 막장압, 커터헤드 회전속도, 피칭, 롤링, 굴진속도, 송니유량, 배니유량, 쉴드잭 사용 개수, 그리고 대상 지반정보인 토피고, RQD, TCR,절리간격, 일축압축강도 및 P파속도를 분석 대상 특성변수로 선정하였다.
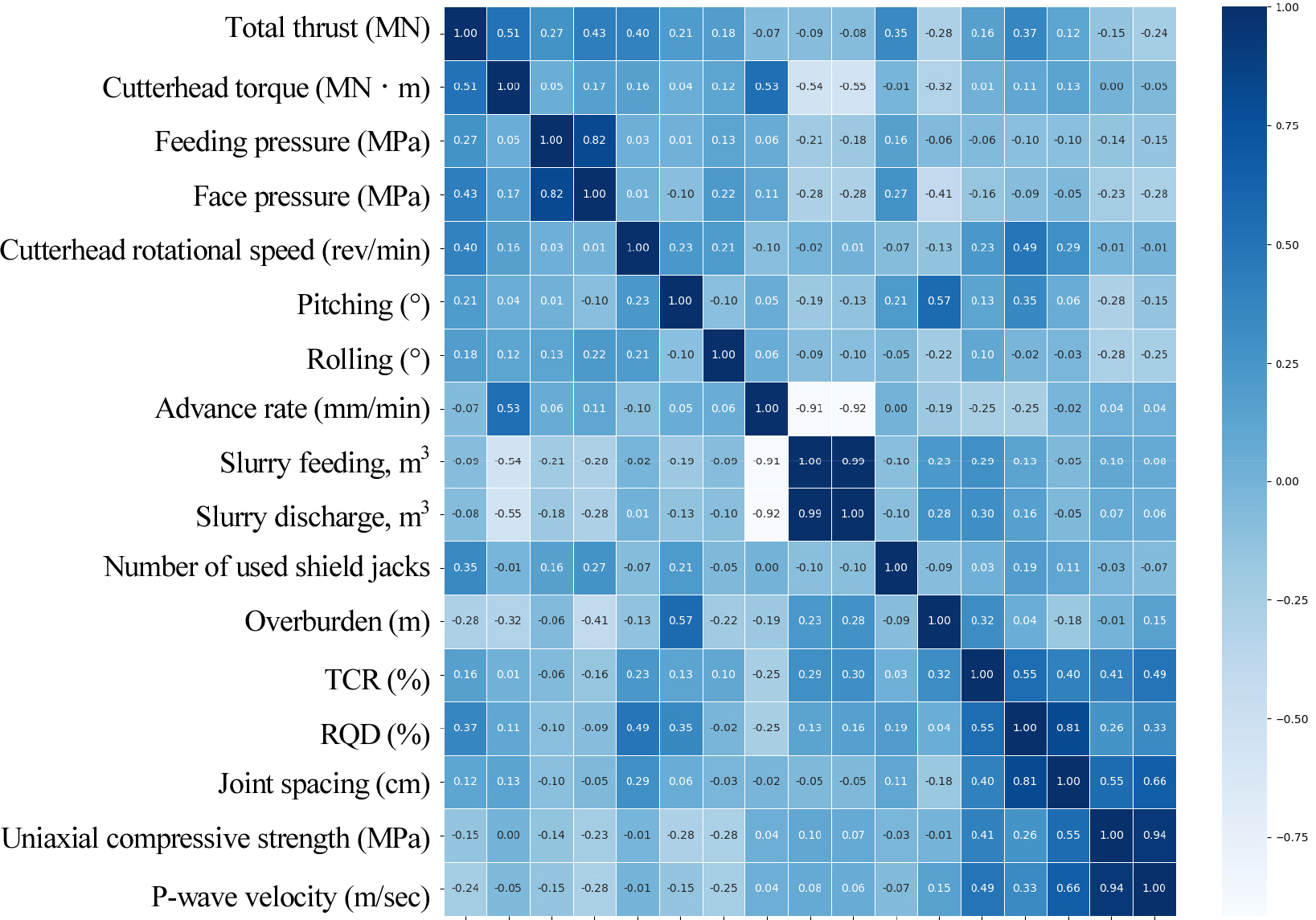
이상의 특성 변수들에 대해 Fig. 2에서 통계적 분포 특성이 뚜렷한 특성변수를 먼저 선택하였고, 그 다음으로 Fig. 3의 상관관계 검증을 통해 특성변수를 확인하였다. 분석결과, 이수식 쉴드 TBM 장비의 운영 변수 중에서 기계학습 대상인 목적변수로 선정된 총추력, 커터헤드 토크, 막장압 및 배니유량와 송니압, 배니유량, 굴진속도, 사용 쉴잭수 등의 특성변수들의 높은 상관도를 확인하였다. 그리고, 본 연구의 학습 대상 현장에서는 약 1,500개 항목의 11만개 기계데이터가 획득되어 분석에 사용되고, 터널 설계단계에서 조사된 시추조사 위치의 지반데이터와 동일한 구간에서 획득한 기계데이터 총 2,100개로 학습 데이터를 구성하였다.
4. 분석 결과
4.1 성능평가와 하이퍼파라미터 결정
이수식 쉴드 TBM의 운전 변수 예측을 위한 학습 모델의 적합성을 평가하기 위해서 총 2,100의 데이터에 대해 학습 데이터와 테스트 데이터를 7:3 비율로 무작위로 조합하여 적용하였다. 회귀 모델의 예측성능을 평가하는 방법으로는 평균오차제곱에 루트를 더하여 실제 관측값과의 차이를 확인할 수 있는 RMSE (Root Mean Squared Error)와 예측 모델이 주어진 자료와 얼마나 적합한가를 평가하는 척도인 결정계수(coefficient of determination, R2)를 사용하였다. 결정계수는 1에 가까울수록 선정된 회귀 모델이 설명력이 높음을 알려준다(Table 3).
Table 3.
Performance measures of regression prediction
| Definition of the terms | Formulas for measuring performance |
| MSE: Mean Squared Error | |
| RMSE: RootMean Squared Error | |
| R-squared: Coefficient of determination |
하이퍼파라미터(hyperparameter)는 머신러닝 모델을 만들 때 직접 조정해주는 값으로 최적의 훈련 모델을 구현하기 위해 결정하는 변수이다. 데이터 훈련 과정에서 알고리즘 모델에 적합한 파라미터의 조합을 찾기 위해 하이퍼파라미터 튜닝(hyperparameter tuning)을 수행할 수 있으며, 이는 모델의 성능에 영향을 주는 하이퍼파리미터들의 최적값을 착기 위한 조정 작업이다.
본 연구에서는 쉴드 TBM의 운전 변수 예측의 학습 결과가 일부 데이터에 과적합(overfitting)되는 것을 방지하기 위해 분할 교차 검증(k-fold cross validation)을 적용하였다. 분할 교차 검증은 앞서 7:3로 분할된 학습 데이터(training data)를 다시 k 묶음으로 나누어 학습 데이터와 테스트 데이터를 k개 구성하여 k번 학습을 반복하고 k번의 학습 결과에 대해 평균을 계산하여 편향되지 않는 최종 성능을 구하는 방법이다(Fig. 4). 본 연구에서는 5번의 교차검증(5-fold cross validation)의 성능비교를 통해 가장 좋은 성능을 내는 하이퍼파라미터 조합을 찾는 그리드서치(GridSearchCV) 튜닝 방법에 의해 회귀 학습모델에 대해 각 목표 변수별로 적합한 파라미터를 결정하였다(Table 4).
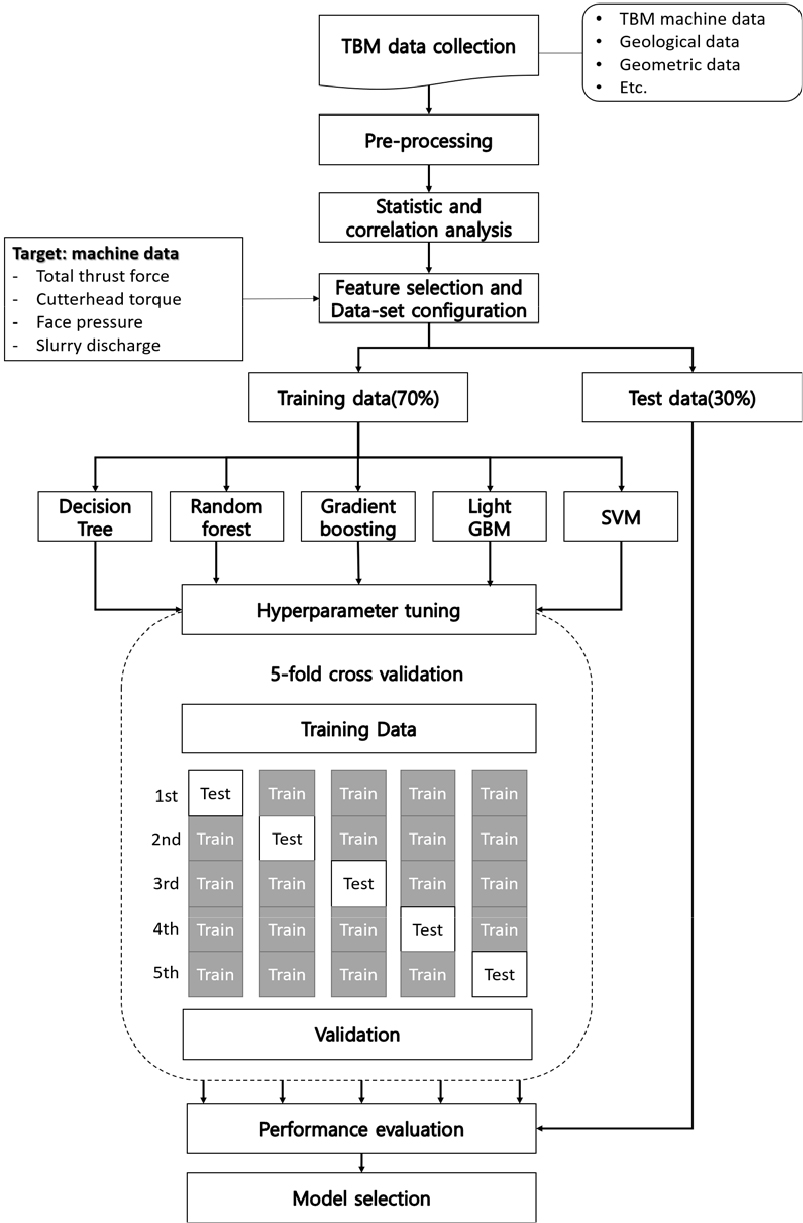
Table 4.
Summary of Hyperparameter for regression models
4.2 학습 결과
본 연구에서는 이수식 쉴드 TBM의 굴진 데이터와 지반정보에 대해 기계학습 알고리즘을 이용하여 학습을 수행하였다. 학습 모델의 적합성을 나타내는 결정계수는 1에 가까울수록 예측성능이 우수함을 의미하며, RMSE는 오차를 나타내므로 작을수록 오차가 작아 예측성능이 우수하다는 것을 의미한다. 이상과 같은 기계학습 알고리즘 모델을 이용한 분석결과를 정리하면 다음의 Fig. 5 및 Table 5와 같다.
분석 대상인 이수식 쉴드 TBM의 운전 변수 가운데 총 추력, 커터헤드 토크 및 막장압에 대한 예측 결과, 의사결정트리와 랜덤 포레스트의 결정계수가 학습 세트(70%)와 테스트 세트(30%)에서 각각 0.688~0.899 및 0.724~0.890으로 나타나 예측 성능이 뛰어나지는 않은 것으로 나타났다. 반면, 그래디언트 부스팅, Light GBM 및 서포트 벡터 기법의 경우에는 결정계수가 학습 세트와 테스트 세트에서 각각 0.887~0.997 및 0.921~991의 범위로 나타났으며, RMSE값도 0.049~2.234로 나타나 예측성능이 상대적으로 높은 것을 확인할 수 있다.
슬러리의 배니량에 대해서는 전체 예측 모델의 결정계수가 학습 세트는 0.964~0.997, 테스트 세트는 0.951~0.991로 나타났으며, RMSE값도 0.279~1.708로서 모든 모델의 예측 성능이 양호한 것으로 나타났다.
이상의 분석 결과, 테스트 세트의 성능 측면에서만 보면 의사결정트리와 랜덤 포레스트를 제외하고 모두 비슷한 성능을 나타내었으나, 그래디언트 부스팅 모델이 총 추력, 커터헤드 토크, 막장압 및 배니량의 테스트 세트에 대한 예측에서 전반적으로 가장 좋은 성능을 보이는 것으로 나타났다. 각 모델들의 전산자원 소모량과 학습속도를 고려할 필요가 있고 일반적으로 조정해야 할 하이퍼파라미터의 숫자와 모델별 특성에 따라 속도차이가 있지만, 본 연구에서는 그래디언트 부스팅이 학습 진행 속도와 예측 성능 측면 모두에서 가장 양호한 결과를 산출하는 것을 확인하였다.
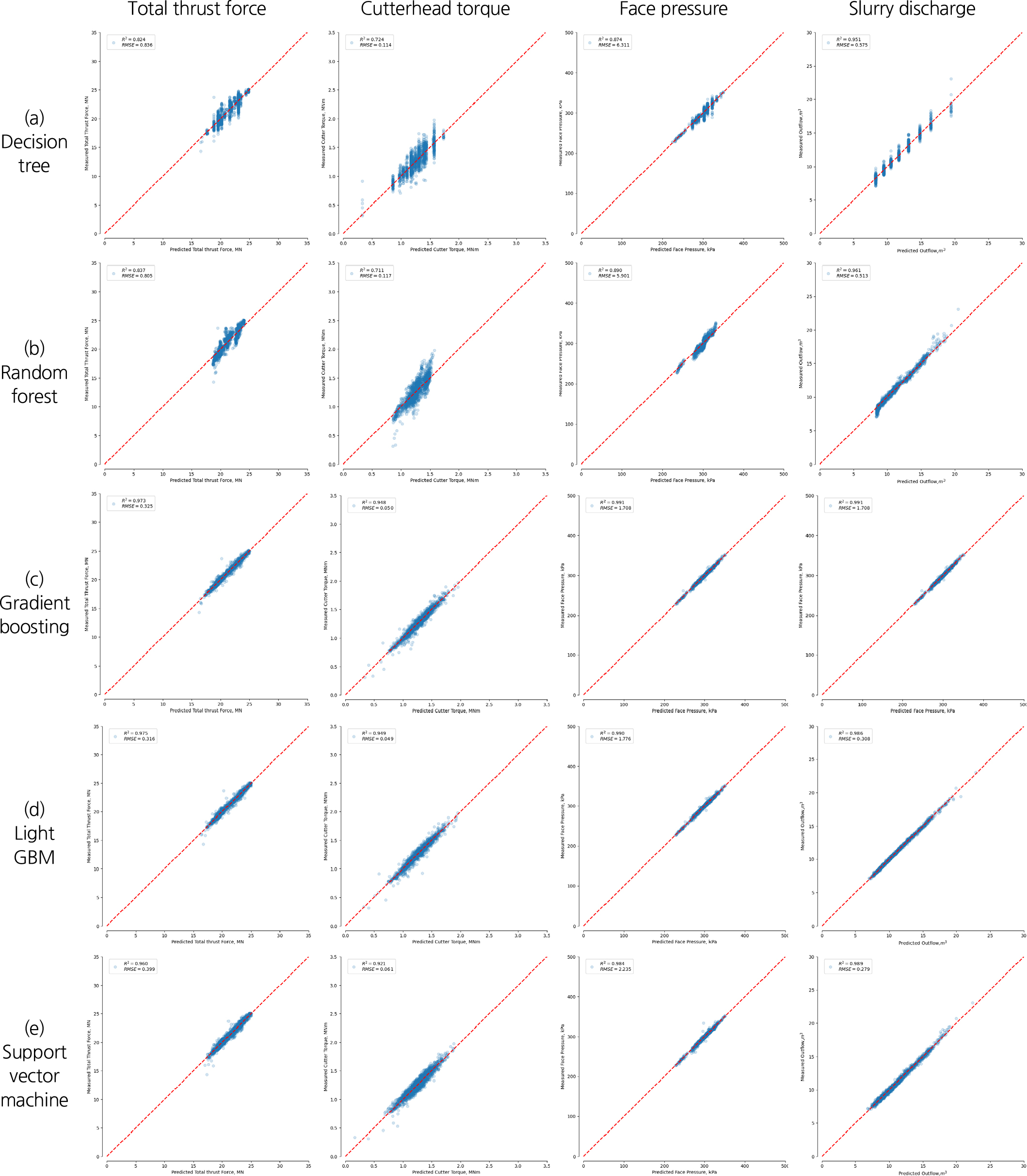
Table 5.
Evaluating the performance of regression models for Shield TBM datasets
4.3 학습 결과를 활용한 예측
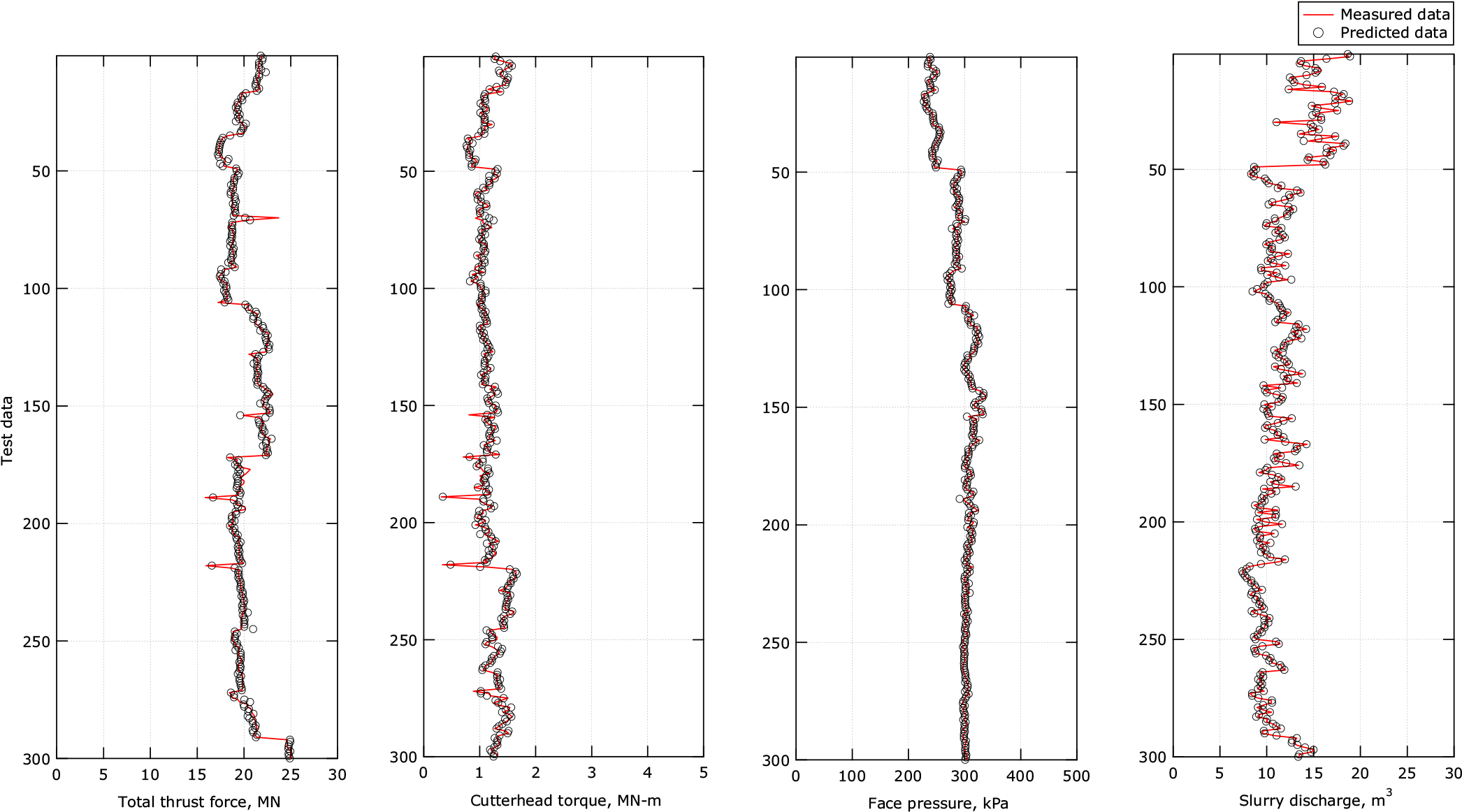
앞선 4.2절에서는 이수식 쉴드 TBM을 대상으로 지반조사 결과와 굴진 데이터를 활용하여 운전 변수 예측을 수행하였고, 학습 결과로부터 그래디언트 부스팅 기반 예측 모델의 성능을 확보하였다. 그래디언트 부스팅 모델에 의해 학습 과정에서 별도로 분리해 놓은 평가 세트를 대상으로 네 가지 운전 변수에 대한 예측을 수행하였다.
Fig. 6은 운전 변수들에 대한 모델 예측값과 실제 측정값을 비교한 결과로서, 이수식 쉴드 TBM의 주요 운전 변수인 총 추력, 커터헤드 토크, 막장압 및 배니량에 대한 그래디언트 부스팅 모델의 결정계수가 각각 0.973, 0.948, 0.991 및 0.987로 양호한 예측결과를 산출하는 것으로 나타났다.
5. 결 론
본 연구에서는 직경 7.3 m인 이수식 쉴드 TBM의 지반정보와 굴진정보에 대한 기계학습에 의해 주요 운영 변수인 총 추력, 커터헤드 토크, 막장압 및 배니유량에 대한 예측을 실시하였다. 실제 현장에서 수집된 데이터를 대상으로 서로 다른 다섯 개의 기계학습 회귀 알고리즘을 적용한 학습을 통해 각 모델에 적합한 하이퍼파라미터를 선정하였으며, 모델 결과를 토대로 최적 모델을 도출하였다.
특성 변수의 분포특성과 변수 간의 상관도 분석을 통해, 기계정보인 총 추력, 커터헤드 토크, 송니압, 막장압, 커터헤드 회전속도, 피칭, 롤링, 굴진속도, 송니유량, 배니유량, 사용된 쉴드잭 개수, 그리고 지반정보인 토피고, RQD, TCR, 절리간격, 일축압축강도, 탄성파속도를 최종변수로 선정하고, 쉴드 TBM의 상ㆍ하행 굴진 시에 측정된 매개 변수를 기반으로 데이터 세트를 구성하였다.
학습모델의 검증을 위해 학습 데이터와 테스트 데이터를 7:3 비율로 구분하여 기계 모델학습 성능평가를 실시하였다. 분할 교차 검증 기반의 그리드서치 튜닝 방법으로 성능비교를 통해 학습 모델별로 가장 좋은 성능을 내는 하이퍼파라미터 조합을 결정하였으며, 총 추력, 커터헤드 토크, 막장압 및 배니유량에 대한 예측에 대한 최종 학습 모델 평가에서 앙상블 모델의 그래디언트 부스팅의 결정계수와 RMSE가 각각 0.917~0.991 및 0.091~0.325로서 적용된 5가지 회귀 알고리즘 가운데 가장 좋은 성능을 나타내었다. 하지만, 본 연구의 결과는 단일 현장에서 측정된 데이터를 기반으로 도출된 것으로서, 향후 다양한 현장에서 측정된 매개변수 데이터를 추가적으로 학습하여 예측 성능의 일반화를 강화하고 검증할 필요가 있다.
