

1. 서 론
산업안전보건법 및 중대재해처벌법 제정을 통해 건설 현장의 사망재해 및 안전사고 대응에 노력을 기울이고 있다(Na et al., 2022). 이에 따라 건설현장 내의 위험 요인을 사전에 발견하여 인적 및 물적 피해를 대비할 수 있는 안전관리 기술 및 시스템 개발에 많은 연구자의 관심이 집중되고 있다. 더욱이 최근 광학 기술 및 딥러닝 기반 컴퓨터 비전 기술의 발전으로 건설현장 안전관리 기술과 접목하여 건설현장의 재해율 감소를 위한 많은 연구가 수행되고 있다.
이런 연구 방향에 맞춰 한국건설기술연구원은 컴퓨터 비전 기반 건설현장의 안전관리 기술 개발의 목적으로 토목 현장에서 CCTV 기반 영상 수집 시스템을 구축하였고, 1년 동안 현장 영상 데이터를 취득하였다. 또한, 건설 현장 내 주요 안전관리 객체를 정의하고 영상 데이터를 가공하여 영상 AI기반 객체 검출 실험을 수행하였다(Na et al., 2022, Na et al., 2023). 하지만 선행연구의 AI기반 건설장비 객체 검출 실험 과정에서 객체 검출 성능은 다양한 기상 조건과 및 조도 조건에 따라 민감하게 변화하여, 일관된 추론 성능을 유지하지 못하는 결과를 도출하였다(Na et al., 2022, Na et al., 2023).
객체 검출 모델은 연속된 주요 안전관리 객체 추적과 위험 요인의 안정적인 감지를 위해서 주변 환경의 변화(기상 혹은 조도 변화)에서 일관적으로 검출하는 성능을 확보해야 한다. 하지만, 저조도 환경에서 영상 데이터의 밝기 대비가 감소 하므로, 객체 검출 정확도는 밝은 조도 조건 대비 현저히 낮아진다. 이에 따라, 본 연구에서 저조도 환경 건설현장의 주요 안전관리 객체검출 모델 생성을 위한 전처리 과정으로 AI기반 저조도 강화 모델의 성능 비교·분석 연구를 진행하였다. 저조도 환경에서 취득한 택지개발 공사현장 CCTV 영상을 데이터셋으로 구성하고 다양한 딥러닝 기반 저조도 영상 강화 모델을 적용하여 저조도 영상 강화를 수행하였다. 저조도 강화된 결과를 정성적, 정량적으로 분석하였으며, 실험에 사용된 택지개발 현장 데이터에 최적화된 모델을 선정하고 객체 검출 모델의 전처리 단계를 연계하여 적용 전후의 결과를 비교하였다.
2. 저조도 영상 강화 기법
최근 컴퓨터 비전 분야에서 딥러닝을 이용한 영상 처리 기법의 적용이 활성화되고 있다. 이에 따라 통계 값이나 Retinex 원리에 기반한 전통적인 저조도 영상 강화 기법에 딥러닝을 도입하는 방안이 활발히 모색되고 있다(Frieden, 2005). 딥러닝 기반의 저조도 영상 강화 기법은 데이터 학습 방식의 측면에서 지도학습을 적용한 기법과 비지도 학습을 적용한 기법으로 구분된다. 지도학습은 다량의 정답 데이터(labeled data)를 기반으로 학습한다. 따라서 저조도와 일반조도 영상이 일대일로 대응하는 데이터 쌍을 학습 데이터로 사용하며 일반조도 영상을 정답 데이터로 활용한다. 반면에, 비지도 학습은 정답이 없는 데이터에서 패턴을 추론하므로, 데이터 쌍을 필요로 하지 않는다. 본 논문에서 적용한 GLADNet (Wang et al., 2018), KinD (Zhang et al., 2019), LLFlow (Wang et al., 2022)는 지도학습 방식을 따르고 있으며, Zero-DCE (Guo et al., 2020)는 비지도 학습 방식을 따르고 있다.
Fig. 1은 GLADNet의 모델 흐름도이다. GLADNet은 global illumination estimation 단계와 details reconstruction 단계로 구성되어 있다. 1단계에서는 저조도 영상에 대한 영상 전역의 일반조도를 추정하며, 2단계에서는 1단계에서 손실된 영상의 상세정보를 복원한다(Wang et al., 2018).
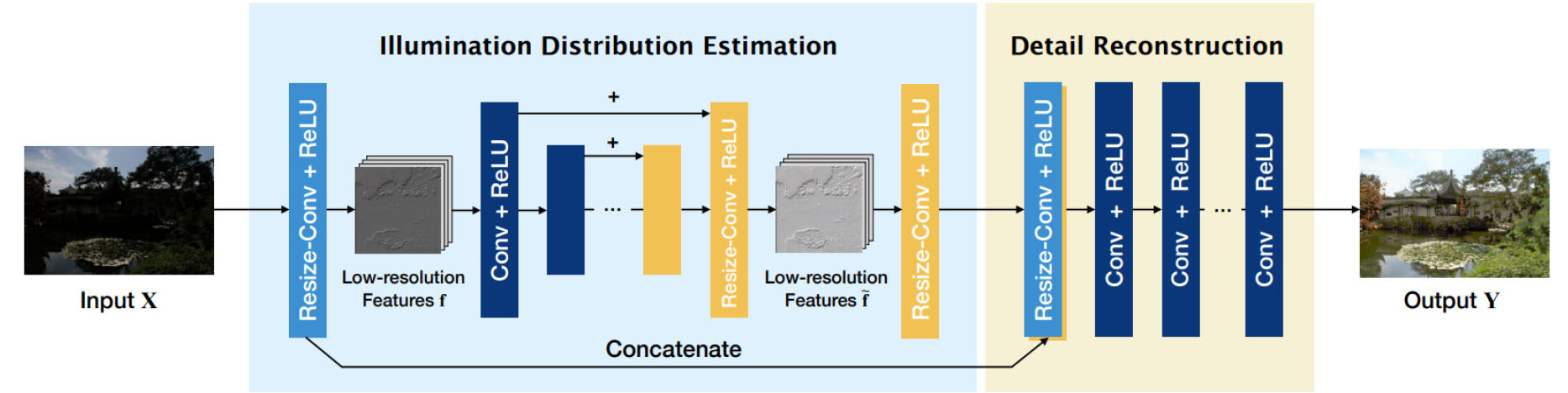
Fig. 2는 KinD (Kindling the Darkness)의 모델 흐름도이다. KinD는 3단계로 구성되어 있으며, 저조도 영상과 일반조도 영상을 reflectance 성분과 illumination 성분으로 분해하는 layer-decomposition net 단계, 저조도 영상의 illumination과 일반조도 영상의 illumination 간의 비율을 계산하여 저조도 영상의 조도를 강화하는 illumination adjustment net 단계, 마지막으로 일반조도 영상의 reflectance를 참조하여 저조도 영상의 reflectance와 강화된 저조도 영상의 illumination을 합성하는 reflectance restoration net로 구성되어 단계별로 수행한 후 최종적으로 영상을 개선한다(Zhang et al., 2019).
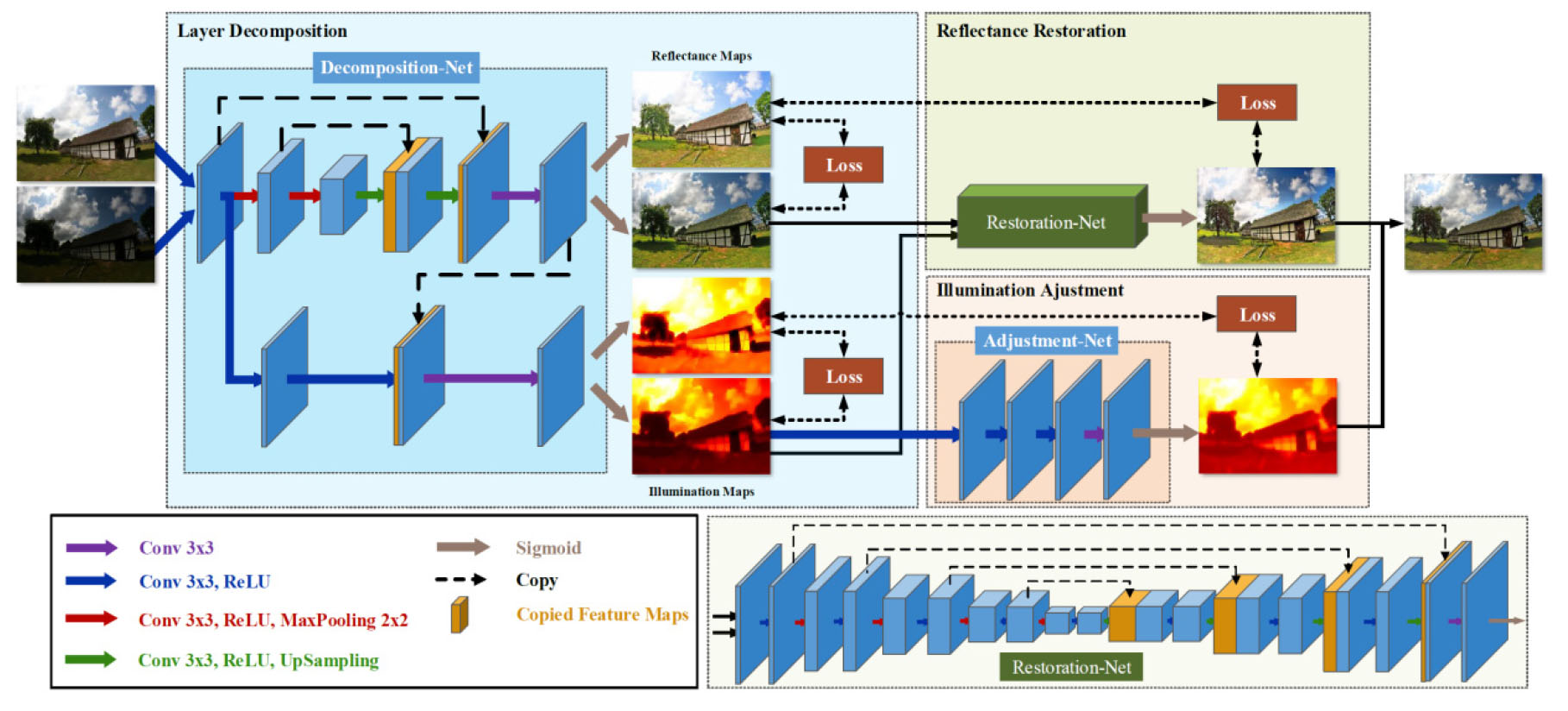
Fig. 3은 LLFlow의 모델 흐름도이다. LLFlow는 인코더 단계와 가역 네트워크 단계로 구성되어 있다. 1단계에서는 저조도 영상으로부터 color map을 출력한다. 2단계에서는 획득한 color map을 일반조도 영상과 연결하는 가역적 정규화 흐름을 통하여 저조도 영상을 강화한다(Wang et al., 2022).
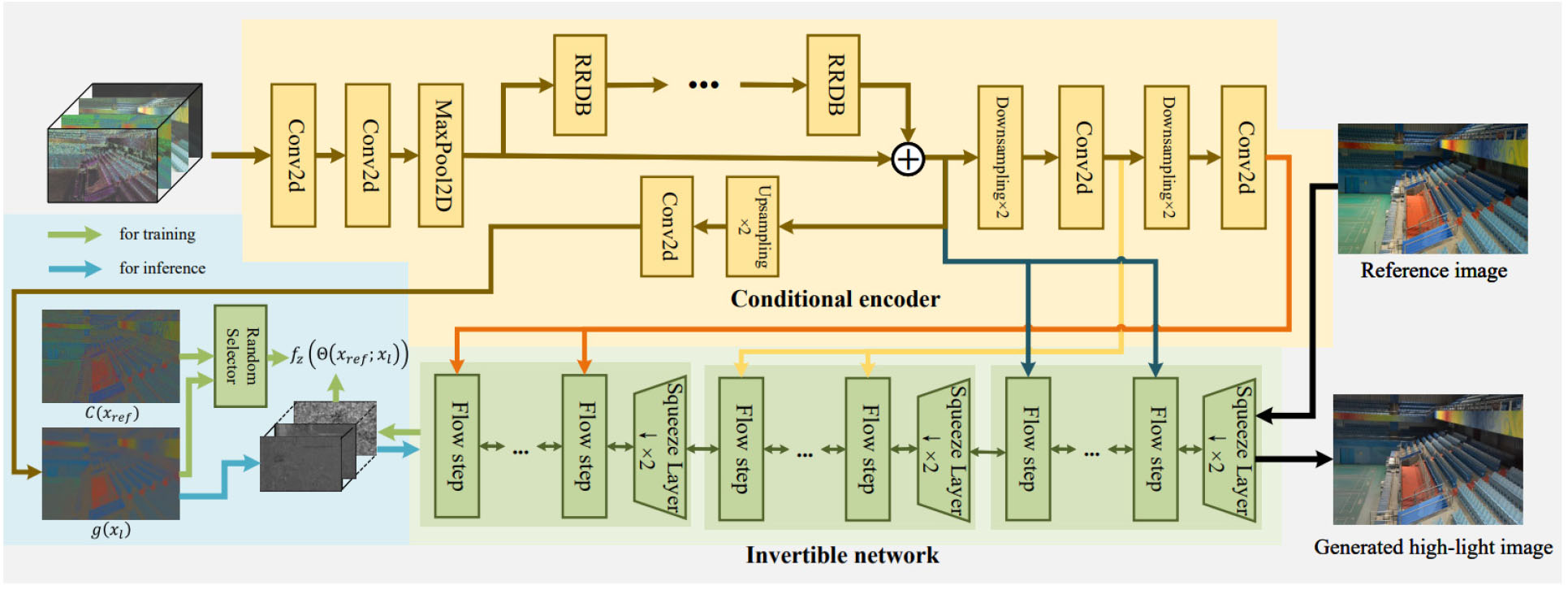
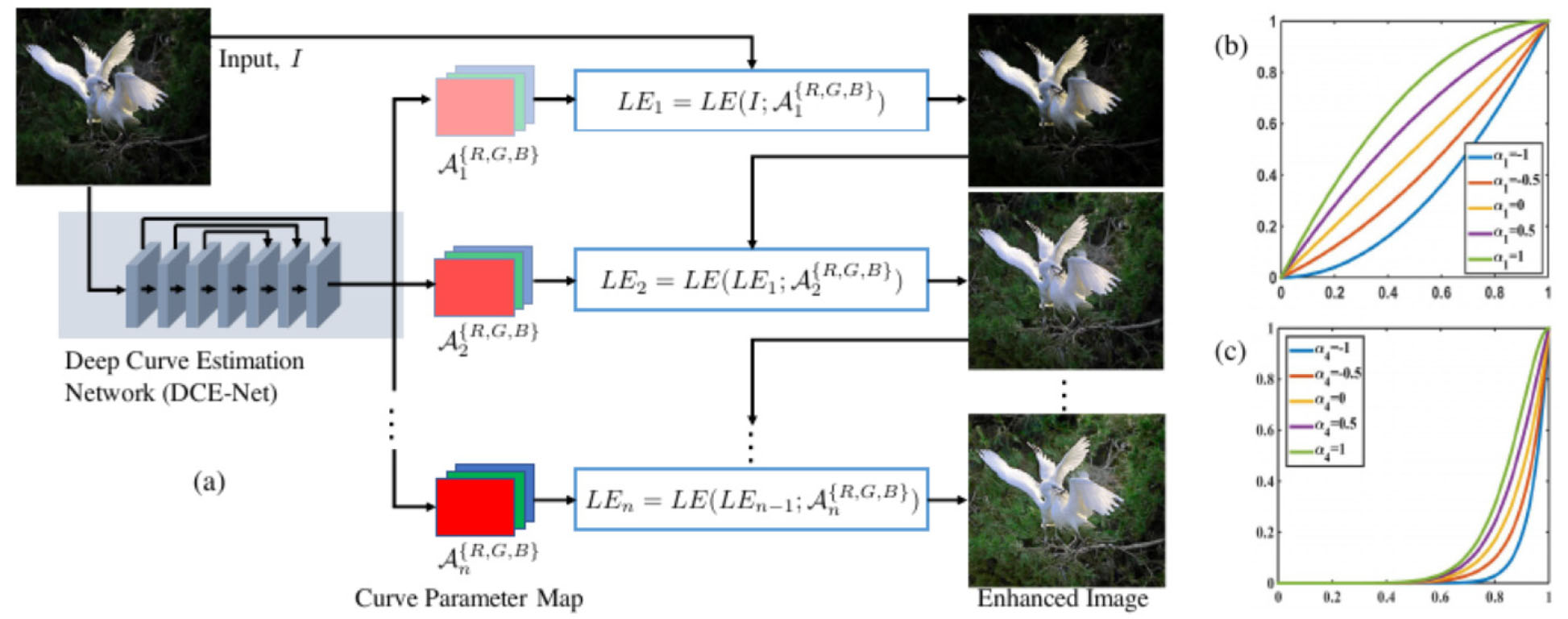
Fig. 4는 Zero-DCE의 모델 구조를 보여준다. Zero-DCE는 앞선 모델들과 다르게 비지도 학습 기반으로 동작하며 레이블 제한 없이 학습이 가능한 Zero-reference 방식을 따른다. Zero-DCE는 DCE-NET (Deep Curve Estimation Network) 학습을 통해 영상 개선함수인 LE-curves (Light Enhancement curves)를 얻는다. DCE-NET은 영상 픽셀이 가진 모든 RGB 채널을 입력으로 받아서 각 채널에 대응하는 고차원 LE-curves를 출력한다. 최종적으로 LE-curves는 저조도 영상에 적용된다. 학습은 인접한 화소 간 값이 급격한 변화가 있는지 판단하는 spatial consistency loss, 저조도 레벨의 화소로부터 적절한 노출 값인 exposure loss, 픽셀의 {R,G,B} 값들과 gray 영상 간의 관계를 나타내는 color constancy loss, 최종적으로 illumination를 나타내는 illumination smoothness loss 함수가 최적화할 때까지 반복된다.
본 논문에서는 토공 현장 대상으로 어두운 배경의 영상 환경에서도 안정적인 모니터링을 수행하기 위해 어두운 조도의 입력 영상을 밝은 조도의 배경으로 변환하는 영상 강화 방안을 제안한다. 저조도 강화 모델은 오픈소스로 다수 제안되고 있지만 모델 특성에 따라 현장마다 성능이 다르다. 따라서 딥러닝 기반의 다양한 저조도 강화 모델(GLADNet, KinD, LLFlow, Zero-DCE)을 적용하여 실험을 수행하였으며, 각 모델의 특성을 파악하고 정량적, 정성적 평가와 함께 비교 분석을 수행하였다. 최종적으로 저조도 영상을 일반조도 영상으로 강화한 결과를 확인하였다. 이러한 전처리 기술을 모니터링 시스템의 조도 환경에서의 취약성을 보완하였으며 향후 딥러닝 기반의 객체 검출 기술과 연계를 통해 현장 위험 상황 자동 감지에 연계될 기술이라 판단된다. 다음 장에서는 저조도 영상 강화 기법의 전통적인 연구와 딥러닝 기반의 방법론에 대한 지식을 제공하며, 3장에서는 실험 결과와 분석을 제공하고 4장에서는 본 논문의 결론을 제시한다.
3. 딥러닝 기반의 저조도 영상 강화 실험
3.1 실험 데이터
본 연구에 활용한 실험 데이터는 한국건설기술연구원에서 택지개발 공사현장에서 취득한 CCTV 영상을 사용하였다(Na et al., 2023). 영상 데이터의 취득은 Pan, Tilt, Zoom (PTZ) 카메라를 사용하여 전체 현장 중 절토 및 성토 공정 단계의 영상 데이터를 활용하였다. 1년간의 현장 영상 데이터를 원격으로 수집하도록 시스템을 구성하였으며, 본 연구에서 활용할 저조도 강화 모델 성능 비교실험을 위해 전체 취득 영상에서 저조도 영상을 추출하였다. 추출된 영상 데이터 현황은 Table 1에 정리하였으며, 전체 영상에서 동절기(11월-1월) 동안 매일 24장(낮 조건 12장, 저녁 조건 12장)의 이미지를 샘플링하였다. 저조도 영상 강화학습을 위해 저조도 영상과 낮 조건의 영상을 동시에 획득하는 것은 지도학습 모델에 유리한 조건이지만, 동일 시간대에 저조도와 밝은 영상을 동시에 취득하는 것은 불가능하므로 가장 유사한 낮 조건의 영상을 선별하였다.
Table 1.
Image dataset structure
본 연구에서 비교한 저조도 영상 강화 모델은 지도학습 모델인 GLADNet, KinD, LLFlow 모델과 비지도학습인 Zero-DCE 모델로 구성된다. 학습 모델의 방법론을 고려한 학습 데이터셋을 구성은 필수적이며, 이에 대한 영상 데이터셋 현황도는 Table 2에 정리 되어있다. GLADNet, KinD, LLFlow 모델의 경우에는 저조도 영상과 낮 조건의 영상을 쌍으로 학습 데이터셋을 구성하였으며, 비지도학습인 Zero-DCE의 경우 서로 다른 노출 레벨의 영상(저조도 영상과 낮 조건의 영상)을 함께 학습 데이터로 구성하였다.
Table 2.
Train and test dataset depending on AI models
3.2 실험 방법
Fig. 5는 AI기반 저조도 강화 모델에 따른 저도도 영상 강화 성능 비교실험의 순서를 나타낸다. 실험의 첫 단계로 취득된 데이터로부터 영상을 샘플링하고, 다음으로 샘플링 된 영상 데이터를 Table 2와 같이 학습 데이터셋으로 구성한다. 데이터셋 구성 후 저조도 강화 모델에 따라 학습을 수행하여 모델을 생성한다. 마지막으로 학습된 모델별로 테스트 데이터셋을 활용하여 정성적, 정량적 평가를 수행하여 각 모델의 저조도 강화 성능을 비교 분석하였다.

저조도 강화 모델에 따른 저조도 강화 성능의 정량적 평가를 위해 PSNR (Peak-Signal-to Noise Ratio), SSIM (Structural Similarity Index) (Wang et al., 2004), Delta-E (Robertson, 1990) 3가지 평가 지수를 활용하였다. 컴퓨터 비전 분야에서 PSNR은 영상 데이터가 압축되거나 왜곡된 상태의 품질을 원본 데이터와 비교하여 측정하는 데 사용되는 지표다. PSNR은 데시벨(dB)로 측정되며, 식 (1)을 사용하여 계산된다.
여기서 는 이미지의 최대 픽셀 값(8비트 그레이스케일 이미지의 경우 최대 255)이며, 는 원본과 왜곡된 이미지 간의 평균 제곱 오차이다. PSNR 값이 클수록 원본과 왜곡된 이미지 간의 인식 가능한 차이가 적다는 것을 나타내며, 손실이 적은 양질의 영상 데이터임을 의미한다.
SSIM은 두 이미지 간의 유사성을 양적으로 측정하는데 사용되는 지표로써, 픽셀 단위의 차이에 집중하는 PSNR과 달리 SSIM은 이미지의 구조 정보와 인간의 시각 기관 상의 변화를 고려한다. SSIM은 이미지의 유사도를 luminance, contrast, structure 측면에서 비교하여 –1부터 1까지의 범위로 유사성이 계산된다. 식 (2)를 활용하여 계산된 값이 1에 가까워질수록 높은 유사성을 가지는 것을 의미한다.
여기서 와 는 이미지의 와 의 평균이며, 와 는 이미지의 와 의 분산이고, 는 이미지의 와 의 공분산이다. 과 는 분모에 0이 되는 것을 방지하는 목적으로 안정성을 위한 상수이다.
Delta-E는 두 이미지 간의 색상 차이를 측정하는 데 사용되는 지표이며, 주로 모니터, 프린터, 카메라 등의 영상 장치에서 색상 재현의 정확도를 검증하는 목적으로 사용된다. 이 지표는 두 영상의 RGB 색상을 CIE (Commission Internationale d’Eclairage) LAB 색상으로 변환하여 서로의 차이를 계산한다. L은 명도, a는 빨강과 초록의 보색, b는 노랑과 파랑의 보색을 의미한다. Delta-E 값이 0에 근접할수록 색이 유사한 양질의 영상으로 평가한다.
3.3 실험 결과 및 분석
저조도 강화 모델별로 저조도 영상 강화 성능을 정성적으로 비교하기 위해 강화된 저조도 영상에 대한 육안 분석을 수행하였으며, 더불어 정량적인 비교를 위해 낮 조건의 영상과 비교하여 저조도 강화된 영상의 영상 품질 평가 지수를 산출하고 분석하였다.
3.3.1 육안 분석
Fig. 6(a)는 낮 조건에서 촬영한 토공현장 원본 영상이며, Fig. 6(b)는 저조도 조건에서 촬영된 영상이다. Fig. 6(c)에서 Fig. 6(f)는 실험에 사용된 각 저조도 강화 모델 적용 결과를 보여준다. 시각적으로 분석한 결과 각 저조도 영상 강화 모델을 통해 저조도 영상의 조도가 강화된 것을 확인할 수 있다. 지도학습 기반의 저조도 강화 모델인 GLADNet, KinD, LLFlow 모두 Retinex 알고리즘 기반 학습하지만, 결과는 상이하게 나타났다. KinD의 적용 결과, 영상 전반적으로 조도는 강화되었지만, 회색조 영상으로 표현되었다. LLFlow와 GLADNet의 적용 결과는 상대적으로 전체 픽셀 고유의 reflectance 성분과 illumination 성분이 낮 조건의 영상에 가깝게 복원된 것을 확인할 수 있으며, GLADNet의 적용 결과에서 영상 전체적인 대비가 향상되었다. 비지도 학습 모델 Zero-DCE의 적용 결과에서 상대적으로 잡음이 제거되는 결과가 나타났지만, 강화된 영상이 청색으로 표현되는 색감 왜곡 현상이 발생하였다.

3.3.2 영상품질 평가 지수 기반 분석
영상 품질 평가지표로 PSNR, SSIM, Delta-E를 사용하여 저조도 강화 성능을 정량적으로 평가하였다. Table 3은 저조도 강화 모델에 따른 강화된 영상에 대한 영상 품질 평가 지수를 적용한 결과를 보여준다. 원본 영상과 저조도 조건의 영상을 비교한 결과에서 검증할 수 있듯이 모든 모델의 영상 품질 평가 지수가 개선되었음을 확인할 수 있다.
Table 3.
Evaluation results according to low-light enhancement models
| PSNR↑ | SSIM↑ | Delta-E↓ | |
| Night conditions | 8.362 | 0.043 | 38.022 |
| GLADNet | 11.506 | 0.057 | 8.034 |
| KinD | 10.878 | 0.053 | 1.225 |
| LLFlow | 10.771 | 0.049 | 14.257 |
| Zero-DCE | 10.672 | 0.050 | 23.151 |
GLADNet은 강화된 저조도 영상의 PSNR이 11.506으로 품질이 가장 우수한 것으로 나타났으며, SSIM은 0.057로 품질이 가장 높다고 분석되었다. KinD의 경우 LLFlow 및 Zero-DCE와 유사한 PSNR 및 SSIM 결과를 보여주지만, Delta-E가 1.225로 색상 품질이 가장 높은 것으로 분석된다. 육안 분석 결과 KinD로 강화된 저조도 영상의 조도가 가장 낮기 때문에 Delta-E는 인간이 시각적으로 인지하는 영상 품질을 제대로 반영하지 못함을 알 수 있었다. 테스트 데이터셋에 대한 각 모델의 저조도 강화 영상을 정성적, 정량적으로 분석한 결과 GLADNet의 영상 품질이 가장 높다는 것을 알 수 있다.
4. 결 론
본 논문에서 저조도 환경에서 취득한 토공현장 영상의 조도를 딥러닝 기반의 영상 강화 모델을 통해 강화하는 연구를 진행하였다. 실제 택지개발 공사현장의 CCTV 영상에서 저조도 영상과 낮 조건의 영상을 선별하여 데이터셋을 구축하였으며, 저조도 영상 강화 모델인 GLADNet, KinD, LLFlow, Zero-DCE를 통해 테스트 데이터셋에 대한 저조도 강화를 진행하고 각 모델의 결과를 분석하였다. 실험 결과, 모든 강화 모델에서 저조도 영상의 조도가 강화된 것을 확인하였다. 정성적 분석 결과, GLADNet 모델이 전체적으로 대비가 향상되었으며 원본 영상과 가장 유사하게 강화된 영상을 출력한 것을 확인할 수 있다. 정량적 평가지표를 통한 정량적 분석 결과, GLADNet의 품질 평가 지수가 가장 많이 개선되어 GLADNet으로 강화된 영상의 품질이 가장 높은 것을 확인하였다. 이에 따라 GLADNet이 보유한 토공 현장 데이터셋의 저조도 강화에 가장 효과적인 것으로 분석되었다.
본 연구는 저조도 환경에서 취득한 건설 현장 내 CCTV의 조도를 강화하는 전처리 과정으로 활용할 수 있는 것으로 보이며, 저조도 환경시 영상 데이터 전처리 과정에 활용하여 건설 현장 내 주요 객체의 검출 정확도를 높이는 데 기여할 것으로 기대된다. 향후 연구에서 저조도 영상과 저조도 강화 영상 간의 객체 검출 정확도를 비교하고 분석하여 객체 검출 모델의 전처리 단계로서의 저조도 강화 효과를 검증할 예정이다.
