

1. 서 론
2. 배경 이론
2.1 연구 지역 및 시추공 제원
2.2 이상점 탐지 알고리즘
3. 수리 이상점 탐지 결과
3.1 물리검층 자료
3.2 알고리즘 적용 결과
3.3 수리 이상점을 포함한 조사 구간 선정 결과
4. 결 론
1. 서 론
고준위방사성폐기물처분장은 방사성폐기물의 위해성이 인간 생활권에 영향을 미치지 않을 수준까지 저감 되도록 충분한 기간 동안 그 안전성을 보장해야 하며, 이를 위해 공학적 방벽(engineered barrier)과 천연 방벽(natural barrier)으로 구성된 다양한 안전장치를 마련한다. 일반적으로 천연 방벽은 처분장이 위치하는 부지의 모암을 의미하며, 방벽으로서 온전히 기능하기 위해 양호한 암반 부지를 선정하고 충분히 깊은 심도에 처분장을 건설한다. 처분장으로부터 핵종이 유출된다면 이는 지하수를 통해 암반을 통과하여 최종적으로 지표까지 이동한다. 따라서 유출의 매개가 되는 지하수와 그 매질이 되는 암반의 수리적/지화학적 특성에 대한 정밀한 평가가 매우 중요하다.
한국원자력연구원(Korea Atomic Energy Research Institute, KAERI)은 심부 암반의 수리지질/지화학 특성 분석을 위해 원내에 KURT(KAERI Underground Research Tunnel)를 건설하였고, 또한 KURT 내부와 그 인근에 다수의 조사용 시추공을 시추하여 각종 시험을 수행 중이다. 시추공을 통한 지반 조사 수행 시, 조사 목적에 적합한 시험 방법과 시험 구간 선정은 매우 중요하다. 예를 들어, 현지응력을 측정하기 위해 수압파쇄시험을 수행하는 경우, 새로운 균열을 생성하고 확인하기 용이한 구간을 선정하는 것이 바람직하다. 또한 지화학 분석 등을 위한 지하수 채수가 목적인 경우, 지하수 유동이 확연하여 유량이 풍부한 구간을 선정하는 것이 조사 목적에 부합한다. 조사 구간 선정을 포함한 시추공 시험 계획 수립 시, 시추 코어의 상태와 물리검층 결과를 반영하는 것이 일반적이다. 초음파 주사검층 혹은 공벽 이미지 촬영 결과를 분석하고 시추 코어와 비교하여 개별 절리의 위치와 방향 정보 등을 확인할 수 있다. 또한 탄성파, 밀도 검층 등을 통해 공벽과 암반의 상태를 추정할 수 있으며, 온도와 전기전도도 등의 검층 자료를 통해 공내 지하수의 특성을 확인할 수 있다. 이처럼 물리검층 자료를 정밀히 취득하고 분석하여 암반의 특성을 파악하거나, 혹은 추가적인 조사를 위한 기반자료를 생산할 수 있다.
본 논문은 시추공 물리검층 자료를 바탕으로 수리 이상점의 위치를 파악하기 위해 작성되었다. 여기서 수리 이상점은 시추공에서 수리 유동 가능성이 높은 지점을 의미하며, 비교적 높은 유량이 예상되어 지하수 채수가 용이한 구간에 해당한다. 시추공의 특정 지점에 지하수 유동이 있는 경우, 이는 검층 결과에 영향을 준다. 예를 들어, 공내 지하수를 통해 측정되는 온도, 전기전도도 검층 등은 수리 유동에 의해 국부적으로 큰 변화를 보일 수 있다. 따라서 이를 심도에 따라 도시하고 그 변화를 확인하여 수리 이상대를 탐지할 수 있다. 그러나 이러한 방법은 주관이 개입될 여지가 있으며, 검층 결과의 변화가 크지 않거나 자료의 크기가 클 경우 적용이 제한적이다.
최근 이상점 탐지(outlier/anomaly detection)를 위한 기계학습 알고리즘은 공학, 금융, 의료 등 광범위한 분야에서 활발하게 적용되고 있다. 매우 다양한 적용 사례를 통해 그 성능이 확인되었으며, 지반 조사와 관련된 연구도 활발히 진행되고 있다(Bressan et al., 2020, Ali et al., 2023, Dastjerdy et al., 2023). 상술한 것처럼 수리 이상대는 지하수 검층 자료에서 국부적으로 큰 변화를 보이는 지점일 가능성이 높으며, 이는 전체 자료에서 이상점에 해당한다. 따라서 본 논문에서는 기계학습 알고리즘 적용을 통해 체계적이고 효율적으로 수리 이상점을 탐지하고 알고리즘의 적용성을 평가하고자 하였다. 동시에 수리 이상점 탐지 결과를 반영하여 지하수 채수가 용이한 조사 구간을 선정하고자 하였다. 적용한 알고리즘은 이상점 탐지를 위해 널리 적용되는 DBSCAN, OCSVM, kNN, isolation forest이며 사용한 자료는 한국원자력연구원 내에 위치한 심도 1 km 수준의 DB-2 시추공 물리검층 자료이다.
2. 배경 이론
2.1 연구 지역 및 시추공 제원
연구지역인 KURT 부지의 지형, 지질 조건을 간략하게 기술하면 다음과 같다. 연구지역의 서쪽으로는 고지대인 계룡산이 존재하고, 계룡산 줄기를 능선으로 공주시와 접하며, 갑천이 서남쪽에서 북동쪽으로 흐른다. 연구지역은 비교적 완만한 지형이며 남북 방향으로 반암질의 산지가 형성되어 있다(Lee et al., 1980, Park et al., 1977). 또한 연구지역은 경기변성암 복합체 내에 위치하며 주로 선캠브리아기의 편마암류와 중생대의 심성암과 관입맥암류로 구성되어 있다. 선캠브리아기의 변성암류는 흑운모 편마암 및 편암으로 구분되며, 이들은 KURT 북서부에 주로 분포한다. 심성암류는 크게 시대 미상의 편상화강암과 복운모화강암으로 나뉘며, 복운모화강암이 편상화강암을 관입하고 있는 것으로 알려져 있다(Lee et al., 1980, Park et al., 1977). 상술한 지형, 지질 조건은 Fig. 1과 같다.
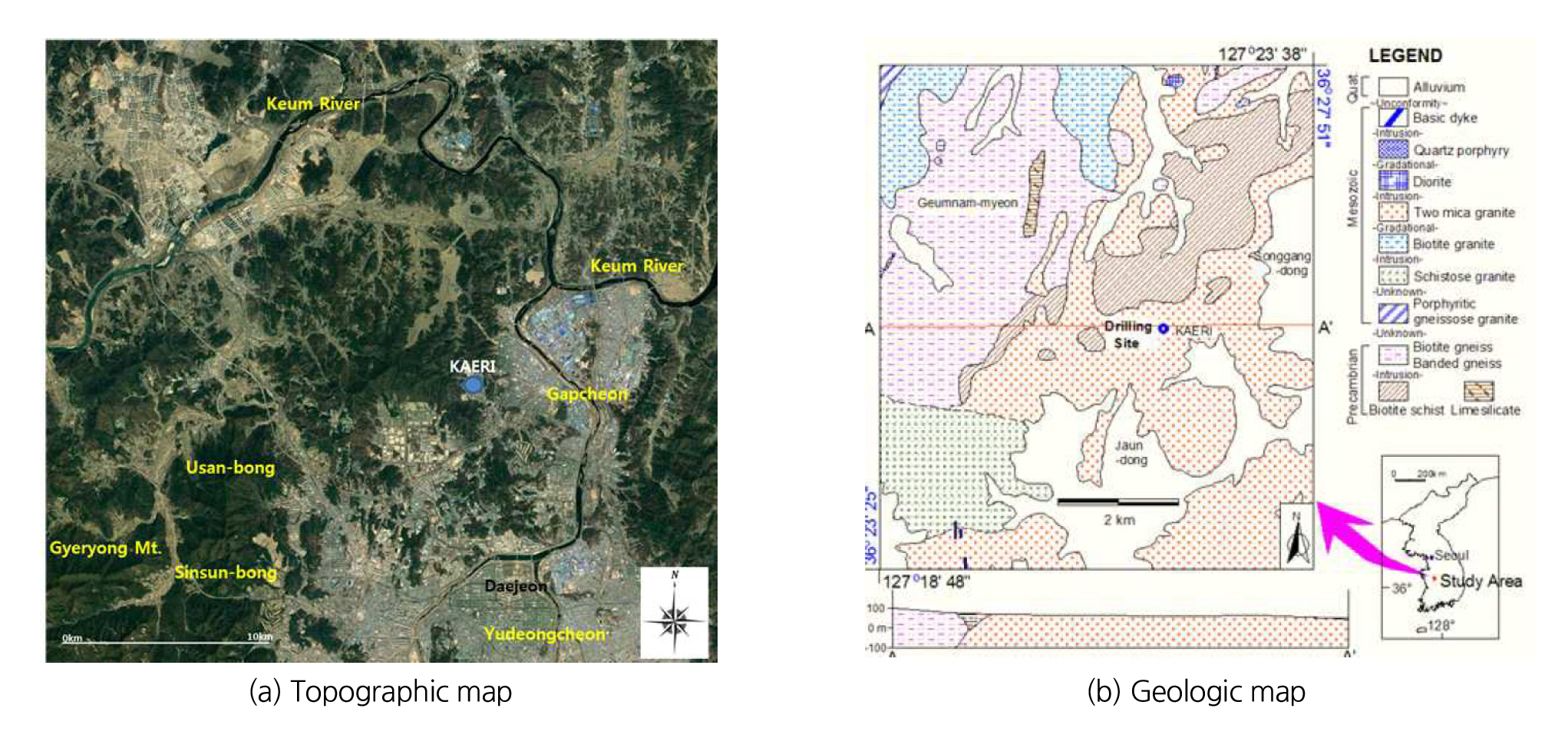
연구 대상 시추공은 KURT 인근에 위치한 DB-2 시추공이다. DB-2 시추공은 KURT 입구에서부터 약 180 m 떨어져 있으며, 지반고 108.16 m에 위치하고 있다. 심도 200 m까지는 4 inch 직경으로, 200~1,000 m 심도는 3 inch 직경으로 시추되었다. 암반은 대부분 화강암으로 이루어져 있으나 다양한 심도에서 열수변질 구조가 분포하며, 변질암으로 분류한 구간은 장석류와 운모류의 내부 변질에 의한 치환 작용이 심하게 발생한 것으로 판단된다(Jung et al., 2021).
2.2 이상점 탐지 알고리즘
본 논문에서는 체계적이고 효율적인 이상점 탐지를 위해 기계학습 알고리즘을 적용하였다. 다양한 분야에서 적용 사례가 풍부한 DBSCAN, OCSVM, kNN, isolation forest 네 가지 알고리즘을 적용하였고, 각 알고리즘에 대한 간단한 설명과 장단점 및 특징을 간략히 정리하면 아래와 같다(Table 1).
Table 1.
Comparison of the algorithms applied in this study
2.2.1 DBSCAN (density based spatial clustering of applications with noise)
DBSCAN은 데이터의 밀도를 기반으로 한 알고리즘이며, 이를 통해 데이터 클러스터링 혹은 이상점 탐지를 수행한다. 전체 데이터의 밀도를 기준으로 클러스터를 형성하고, 클러스터에 포함되지 않는 데이터는 이상점으로 분류된다. DBSCAN은 크게 데이터 밀도(혹은 거리)와 최소 이웃 개수 등을 기반으로 분류를 수행하며, 간략한 설명은 다음과 같다(Ester et al., 1996). 먼저, 특정 데이터 포인트를 기준으로 일정 거리 내에 존재하는 이웃의 개수를 계산한다. 이 개수가 설정한 최소값 이상인 데이터를 ‘core point’로 분류한다. ‘Core point’를 시작으로 일정 거리 내에 존재하는 이웃을 포함하는 클러스터를 형성하고, 최종적으로 어떠한 클러스터에 속하지 않는 데이터를 이상점으로 분류한다. DBSCAN은 클러스터의 숫자를 미리 지정할 필요가 없으며, 비선형 데이터나 밀도가 낮은 데이터에서 효과적으로 적용할 수 있는 장점이 있다. 그러나 밀도 분포의 영향을 받으며 데이터 크기에 따라 연산 시간이 길어질 수 있다.
2.2.2 OCSVM (one class support vector machine)
OCSVM은 정상/이상 데이터를 분류하는 하이퍼 평면(hyperplane)을 찾는 비지도 학습 알고리즘이다. 정상/이상 데이터 간 거리(margin)와 데이터를 매핑하는 커널 함수(kernal function)를 사용하며, 간략한 설명은 다음과 같다(Hu et al., 2003). 먼저, 커널 함수를 학습시키며 정상 데이터가 원점에서 최대한 멀어지는 방향으로 원자료(raw data)를 특성 공간(feature space)에 투영한다. 원점에서부터 데이터까지의 거리를 바탕으로 분류 기준선(decision boundary, hyperplane)을 결정하며, 이때 분류 기준선에 가까운 데이터가 ‘support vector’에 해당한다. 분류 기준선과 ‘support vector’ 사이 거리를 최대화하는 방향으로 최적화를 수행하면 이상점이 분류된다. OCSVM은 비선형 데이터와 높은 차원의 데이터에도 적용할 수 있으나 사전에 임계 거리(혹은 이상점의 비율) 등을 설정해야 한다.
2.2.3 kNN (k-nearest neighbor)
kNN은 비지도 학습 알고리즘 중 하나이며, 데이터 간 거리를 기반으로 이상점을 탐지한다. kNN은 이웃의 개수(k)와 데이터 간 거리, 두 가지 요소를 사용하며 거리는 유클리드, 맨하탄, 하이퍼볼릭 등을 사용하여 계산한다. 알고리즘을 간략히 설명하면 다음과 같다(Taunk et al., 2019). 먼저, 한 데이터에서 거리가 가까운 k개의 이웃을 선정하고 거리를 계산한다. 계산된 거리의 최대값 혹은 평균이 다른 자료에 비해 확연히 큰 데이터를 이상점으로 간주한다. kNN은 알고리즘이 매우 단순하며 다양한 데이터에 적용할 수 있지만, 임계값을 설정해야 하며 데이터 크기에 따라 연산 시간이 길어질 수 있다.
2.2.4 Isolation forest
Isolation forest는 의사결정 나무(decision tree) 기반의 이상점 탐지 기법으로 알고리즘을 간략히 설명하면 다음과 같다(Liu et al., 2008). 기본적으로 이상점은 전체 데이터에서 비교적 소수이며 홀로 고립되는 경향이 있으므로 이러한 성질을 이용한다. 먼저, 데이터 특징(feature) 중 임의로 하나를 선택하고 그 특징의 최대, 최소 범위 중 임의의 값으로 전체 데이터를 분할한다. 분할 과정은 특징을 바꿔가며 트리의 최대 깊이에 도달할 때까지 반복하며, 빠르게(분할 초기) 고립되는 혹은 고립되는 경로의 깊이(길이)가 짧은 데이터를 이상점으로 판단한다.
3. 수리 이상점 탐지 결과
3.1 물리검층 자료
기계학습에 사용한 데이터는 DB-2 시추공에서 수행한 물리검층 자료이며, 초음파 주사검층, 온도, 전기전도도 검층 자료를 수집하였다. 이 중, 학습에 사용한 데이터는 지하수 검층에 해당하는 온도와 전기전도도 자료이다. 전체 심도 1,000 km까지 수행한 온도, 전기전도도 검층의 원자료는 Fig. 2와 같다.
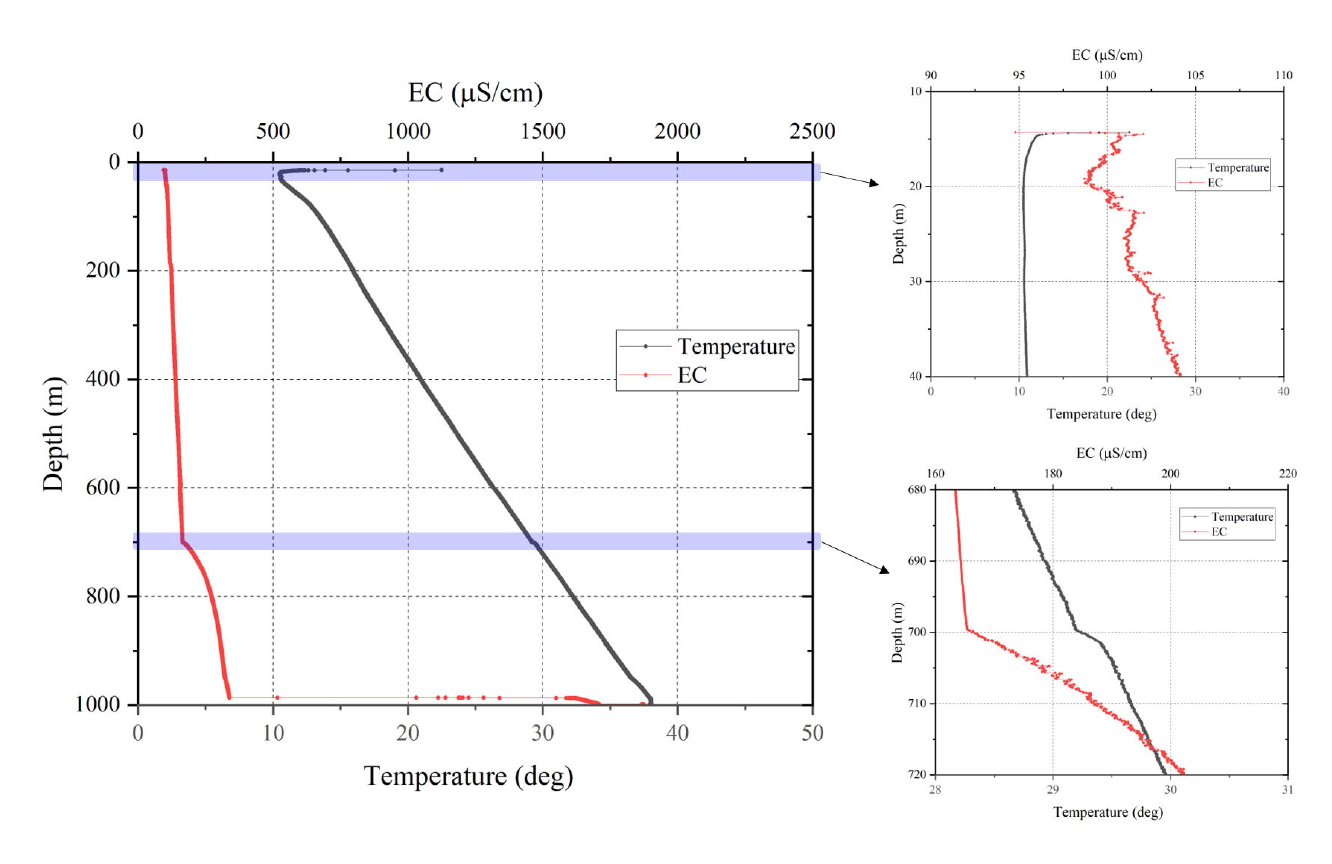
Fig. 2에서 확인할 수 있듯, 데이터 사용에 주의를 요하는 구간이 두 지점 확인되었다. 먼저, 심도 ~20 m 구간의 경우, 심도가 증가함에 따라 온도가 감소하는 경향을 확인할 수 있는데, 이는 일반적인 지온 경사 분포와 다르다. 지하수의 온도는 암반 지온 경사의 영향을 크게 받기 때문에 심도에 따라 증가하는 것이 일반적이다. 따라서 ~20 m 구간의 수온 역전 현상은 외부적 요인, 특히 대기 온도의 영향을 크게 받은 것으로 판단된다. 대기 온도는 계절에 따라 변하며, 이는 지표에서부터 약 20 m 심도까지 영향을 줄 수 있다(Kim and Song, 1999). 따라서 기상관측소의 관측자료 등을 이용하여 대기 영향을 보정해야 하지만, 현재 DB-2에서 온도 검층을 수행한 정확한 시기를 알 수 없어 외부 요인의 영향을 크게 받은 ~20 m의 검층 자료를 제외하고 분석을 수행하였다.
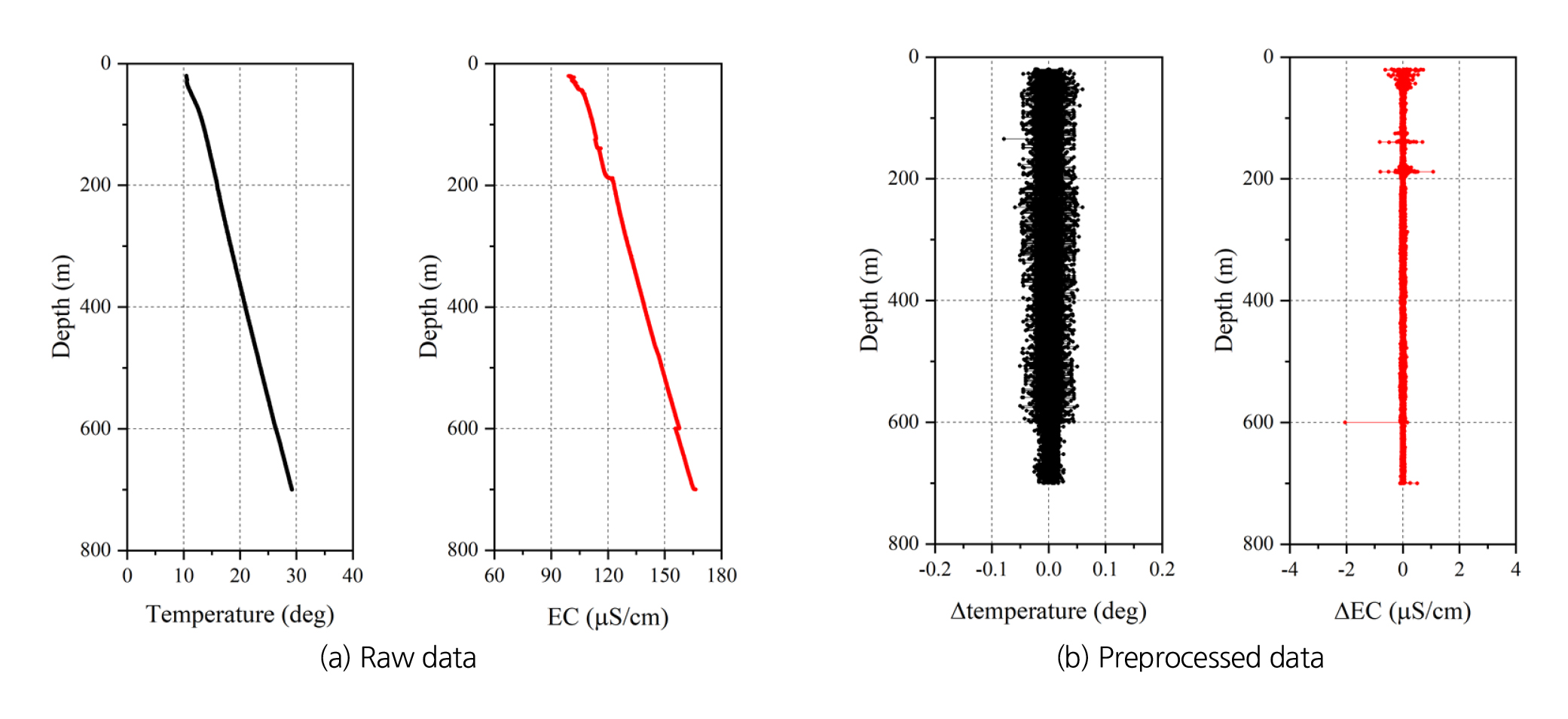
두 번째 주의 구간은 심도 약 700 m 부근이다. 비교적 선형적으로 분포하던 온도와 전기전도도 자료가 700 m를 기점으로 매우 다른 거동을 보였다. 특히, 전기전도도의 경우, 700 m 이하 심도에서 이차함수와 유사한 비선형 거동을 보이는데, 이는 비정상적인 거동으로 판단된다. 이에 대한 정확한 원인은 알 수 없으나, 시추 이수(slurry)나 암편의 침전 혹은 공내 조사 장비 이송에 의한 상/하부 지하수 혼합 등이 영향을 미쳤을 가능성이 있다. 마찬가지로 지하수 유동이 아닌 외부 요인의 영향을 받은 것으로 판단되므로 700 m 이하의 검층 역시 학습에서 제외하였다. 절사된 검층 자료의 심도에 따른 분포는 Fig. 3(a)와 같다.
특정 경향(trend)이 존재하는 데이터를 분석할 때, 이를 그대로 사용하면 부정확한 결과를 도출할 수 있으므로 그 경향을 제거(detrending)하는 것이 바람직하다. 예를 들어, 상술한 것처럼 온도 분포는 지온 경사의 영향을 받기 때문에 심도에 따라 증가하는 것이 일반적이다. 온도 분포에 대한 수리 유동의 영향을 보다 선명하게 파악하기 위해서는 이러한 경향을 제거하는 것이 바람직하다. 다양한 방법을 통해 경향 제거가 가능하지만, 본 논문에서는 단순하게 △ = xn+1-xn 형태로 경향을 제거하였다. 최종적으로 전처리 완료된 학습 데이터는 Fig. 3(b)와 같다.
3.2 알고리즘 적용 결과
Fig. 3(b)와 같이 전처리된 검층 자료를 네 가지 기계학습 알고리즘에 적용하였다. 기계학습 알고리즘은 각 기법에 따라 요구되는 하이퍼 파라미터(hyperparameter)가 존재하며, 이에 적절한 값을 부여해야 원하는 결과를 얻을 수 있다. 예를 들면, DBSCAN의 경우, 최소 이웃 개수와 데이터 간 거리를 적절히 설정해야 하며, OCSVM은 적당한 커널 함수를 설정해야 한다. 하이퍼 파라미터 최적화를 위해 grid search를 적용하였다. 각 알고리즘에서 요구되는 하이퍼 파라미터의 일반적인 사용 범위 내에서 4~5 수준으로 grid를 분할하고 학습을 수행하였다.
각 조합에 따른 학습 결과를 평가해야 최적 파라미터 조합을 결정할 수 있다. 다양한 지수를 활용해 알고리즘 평가가 가능하며 본 논문에서는 실루엣 지수(silhouette score)를 적용하였다. 실루엣 지수는 클러스터링 알고리즘의 성능을 평가하는 지표 중 하나로, 클러스터 내 객체와 다른 클러스터 객체 간 거리를 비교하여 클러스터의 밀도와 분리를 평가한다. 즉, 클러스터링 되지 않은 데이터는 이상점에 해당하므로 클러스터 결과가 양호할수록 이상점 탐지 역시 양호한 것으로 판단하였다. 실루엣 지수는 [-1, 1] 사이의 값으로 계산되며 높은 값일수록 좋은 성능을 의미한다. 실루엣 지수가 1에 가까울수록 좋은 분류 결과이며, 0에 가까우면 경계에 위치한 데이터가 있음을, -1에 가까울수록 불량한 결과를 의미한다. 네 가지 학습 알고리즘의 성능을 grid search를 통해 평가한 결과는 Fig. 4와 같다.
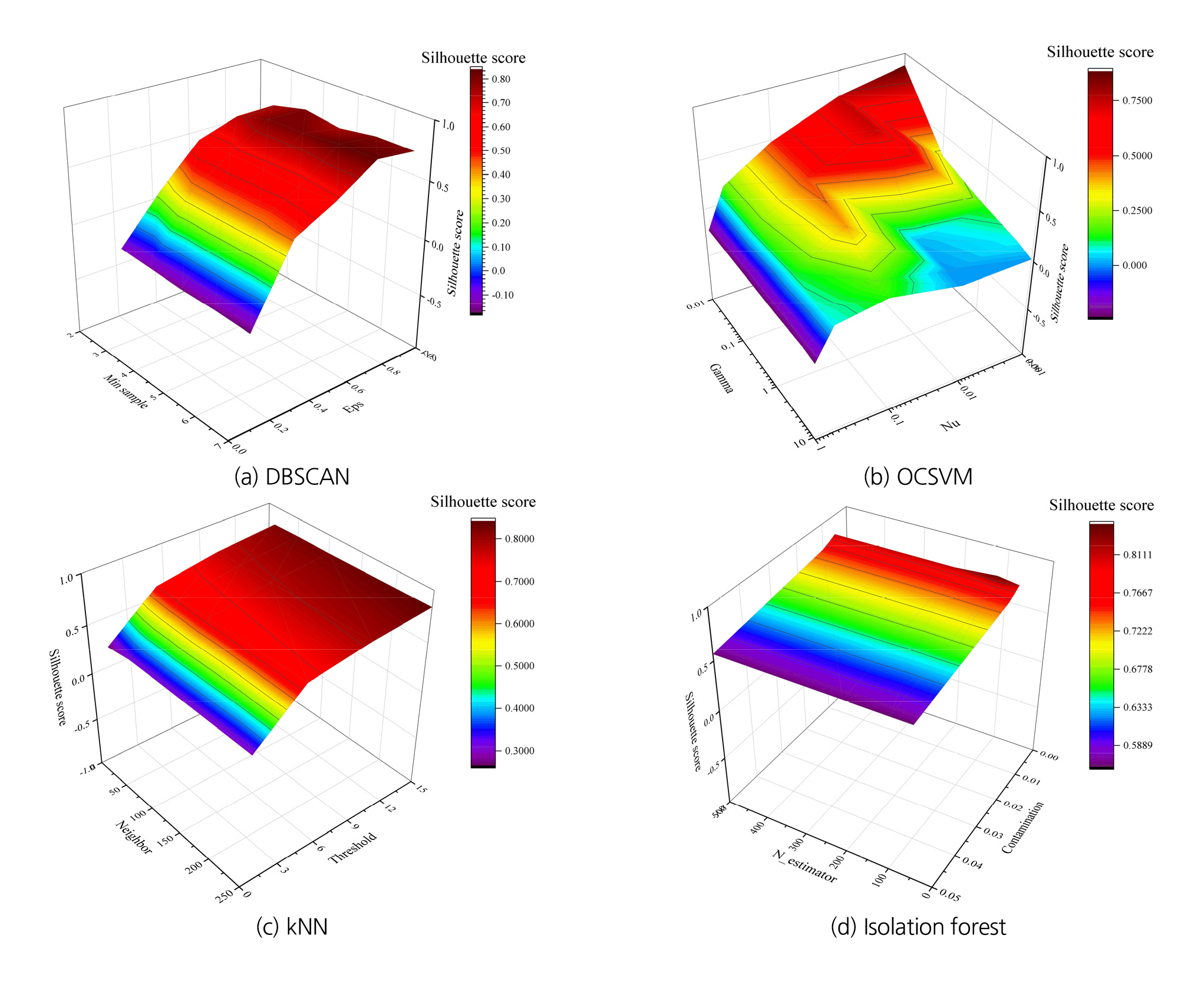
네 가지 알고리즘 모두 실루엣 지수 0.8 이상의 양호한 평가 결과를 보였다. Grid 내에서 최대 실루엣 지수를 보인 하이퍼 파라미터 조합을 적용하여 수리 이상점을 탐지하면 Fig. 5와 같다. 학습시킨 자료는 △Temp, △EC 형태이므로, 두 값으로 이루어진 평면에 이상점으로 분류된 결과를 도시하였다.
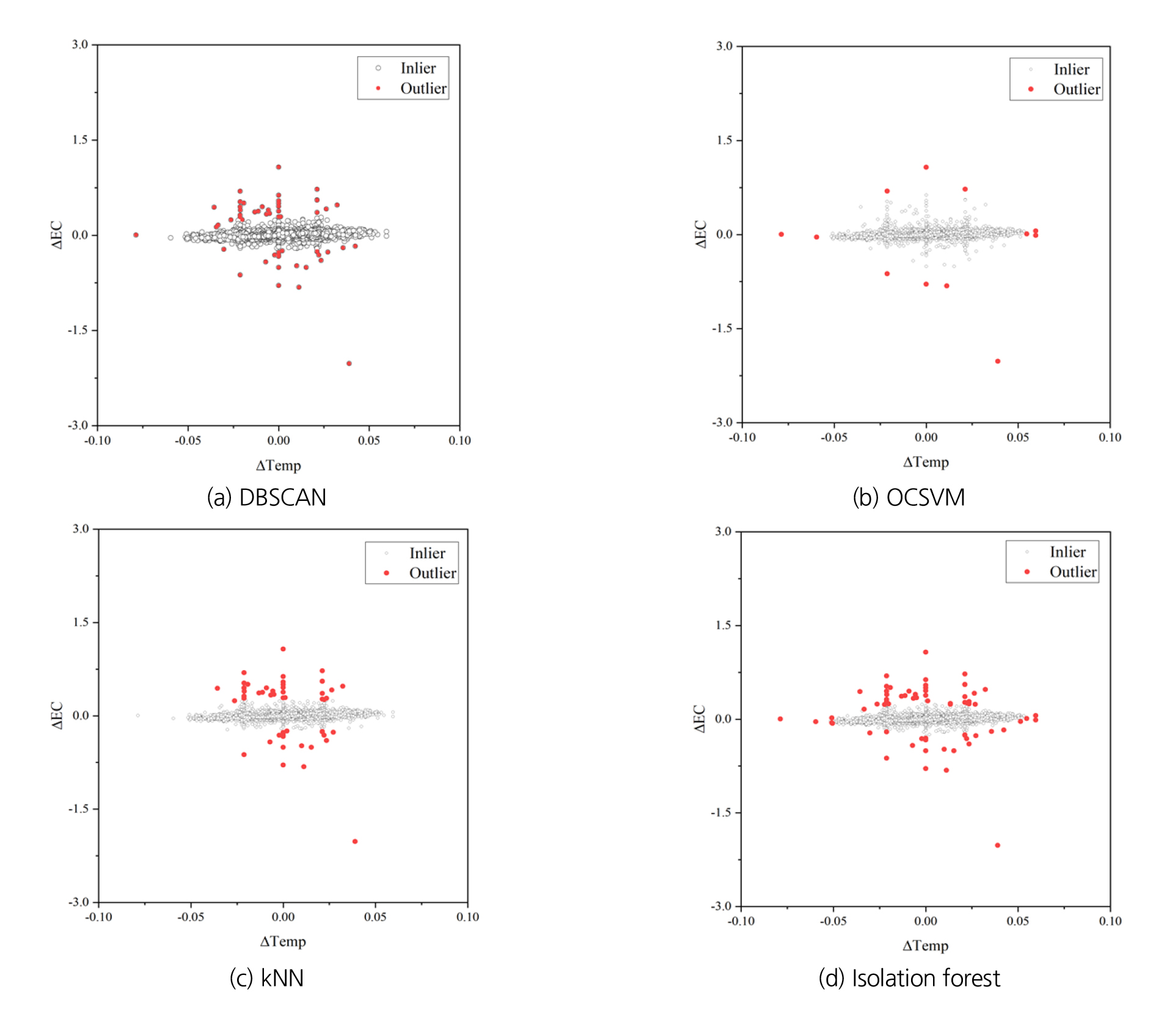
네 가지 알고리즘은 각각 55, 12, 52, 68개의 이상점을 탐지하였고, 분류 형태를 기준으로 DBSCAN과 kNN이 서로 유사하고 OCSVM과 isolation forest가 비교적 유사한 형태를 보였다. 먼저, DBSCAN과 kNN은 △EC = 0 직선을 중심으로 상/하부로 구분할 수 있는 분류 형태를 보였으며, 이상점의 개수도 55, 52개로 유사한 수준을 보였다. 반면에, OCSVM과 isolation forest는 원점을 중심으로 하며, △Temp 축을 장축으로 한 타원과 같은 형태의 정상점(inlier) 분포를 보였으며, OCSVM은 최외곽의 소수 데이터(12개)를 이상점으로 분류하였고, isolation forest는 보다 작은 타원을 중심으로 그 외곽의 데이터(68개)를 이상점으로 탐지하였다. DBSCAN과 kNN은 기본적으로 국부적인 밀도(local density) 혹은 거리를 기반으로 작동하여 데이터의 지역적인 분포와 밀집도가 강조된다. 반면에 OCSVM과 isolation forest는 데이터의 전체적인 구조 및 패턴을 중요시한다. kNN의 경우, 커널 함수를 바탕으로 특정 영역을 구분하며, isolation forest는 데이터 분할 과정을 반복하여 전체적인 구조를 반영한다. 이러한 알고리즘의 작동 원리로 인해 분류 형태의 차이가 발생한 것으로 판단된다.
각 알고리즘에서 두 데이터 특징(feature)인 △Temp, △EC가 분류 결과(label)에 미친 영향을 파악하였다. 분류 결과는 정상/이상의 명목 척도(nominal scale)이기 때문에, 로지스트 회귀 분석을 수행하였고, 로짓 변환 시 각 변수의 계수 및 p-value는 Table 2과 같다.
Table 2.
Results of logistic regression
네 가지 알고리즘 중, OCSVM을 제외한 나머지 세 알고리즘의 변수 영향력은 비슷한 경향을 보였다. Fig. 5(b)에서 확인할 수 있듯, OCSVM은 최외곽 소수 데이터만 이상점으로 탐지했으며, △Temp는 탐지 결과에 (-)의 영향을 미쳤다. 나머지 세 알고리즘에서 공통적으로 확인할 수 있는 경향은 다음과 같다. 먼저, 유의수준 0.05에서 △EC가 탐지 결과에 미친 영향이 상대적으로 크며, △Temp는 유의미한 영향을 미치지 않았다. 또한, △EC가 증가할수록 이상점으로 분류될 가능성이 높은 것으로 파악되었다. 두 변수가 이상점 탐지 결과에 미친 영향은 Fig. 3(b)에서도 확인할 수 있다. 육안으로 확인 가능하듯, △EC의 분별력은 △Temp에 비해 확연히 높은 것을 확인할 수 있다.
3.3 수리 이상점을 포함한 조사 구간 선정 결과
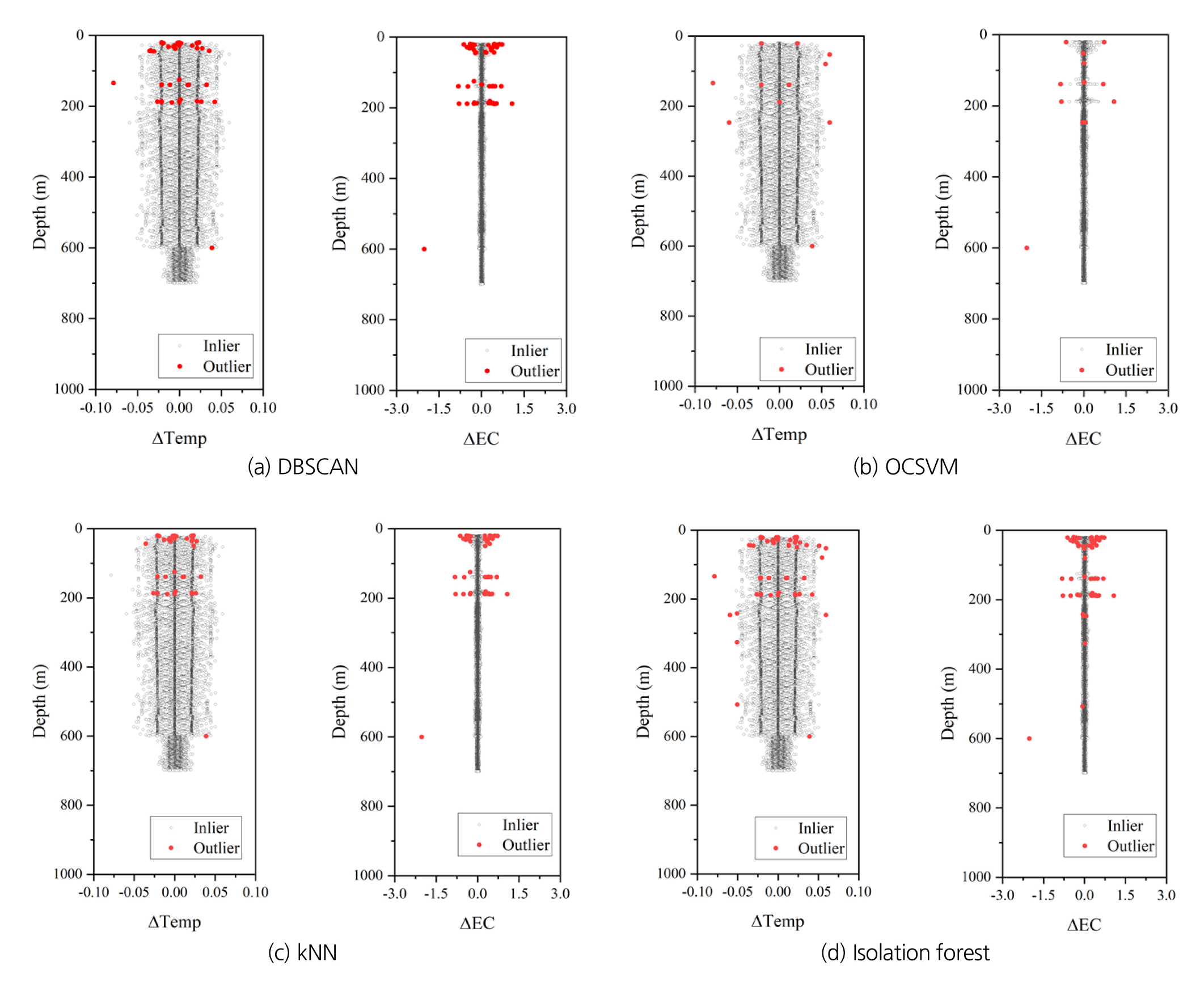
Fig. 5에서 각 알고리즘에 의해 탐지된 수리 이상점을 심도에 따라 도시하면 Fig. 6과 같다. 네 알고리즘 모두 유사한 심도에 수리 이상점이 집중된 것을 확인할 수 있다. 특히, DBSCAN과 kNN은 수리 이상점 탐지 심도가 거의 유사하며, 구체적으로 20~40 m, 140 m, 180 m, 600 m 심도에 집중되었음을 확인할 수 있다. OCSVM은 가장 적은 수의 수리 이상점을 탐지했으며, 그 결과는 isolation forest 탐지 결과에 포함되는 형태를 보였다. Isolation forest는 68개로 가장 많은 수의 수리 이상점을 탐지했으며, 앞선 세 알고리즘의 탐지 심도 외에 325 m, 500 m 등이 추가적으로 탐지되었다.
고준위방사성폐기물처분장 부지의 암반 수준을 고려하면, 암반 매질 자체는 견고하고 공극률이 낮은 양호한 조건을 가정할 수 있다. 결정질이며 동시에 양호한 평가를 받는 암반 조건이면 대부분의 수리 유동은 절리를 포함한 불연속면을 통하여 발생한다. 따라서 절리의 빈도가 높은 구간은 수리 유동 가능성이 높은 지점으로 가정할 수 있다. 초음파 주사검층을 통해 개별 절리의 심도와 경사/경사방향 등의 방향정보를 취득할 수 있다. DB-2 시추공에 대한 초음파 주사검층 결과를 분석한 결과, 약 20~860 m까지 심도에서 총 940개의 절리가 검층되었다. 약 200 m 심도까지 전체 절리의 75%가 분포했으며, 400 m까지 95%의 절리가 분포하였다. 심도가 깊어짐에 따라 절리 빈도는 감소했으며, 가장 깊은 심도의 절리는 865 m에서 확인되었다.
절리 빈도(frequency)는 단위 길이에 존재하는 절리의 수로 정의되며, 절리 간격의 역수이다. 5 m 간격을 기준으로 절리 빈도를 계산하고 히스토그램과 그 누적 분포를 확인한 결과, 누적 빈도 90%에 해당하는 절리 빈도는 약 2.75 m-1로 확인되었다. 심도에 따른 절리 밀도와 빈도 2.75 m-1 이상의 고빈도 구간을 함께 도시하면 Fig. 7(a)와 같다. 또한, 절리 고빈도 구간과 기계학습 알고리즘을 통해 수리 이상점으로 탐지된 구간을 함께 도시하면 Fig. 7(b)와 같다.
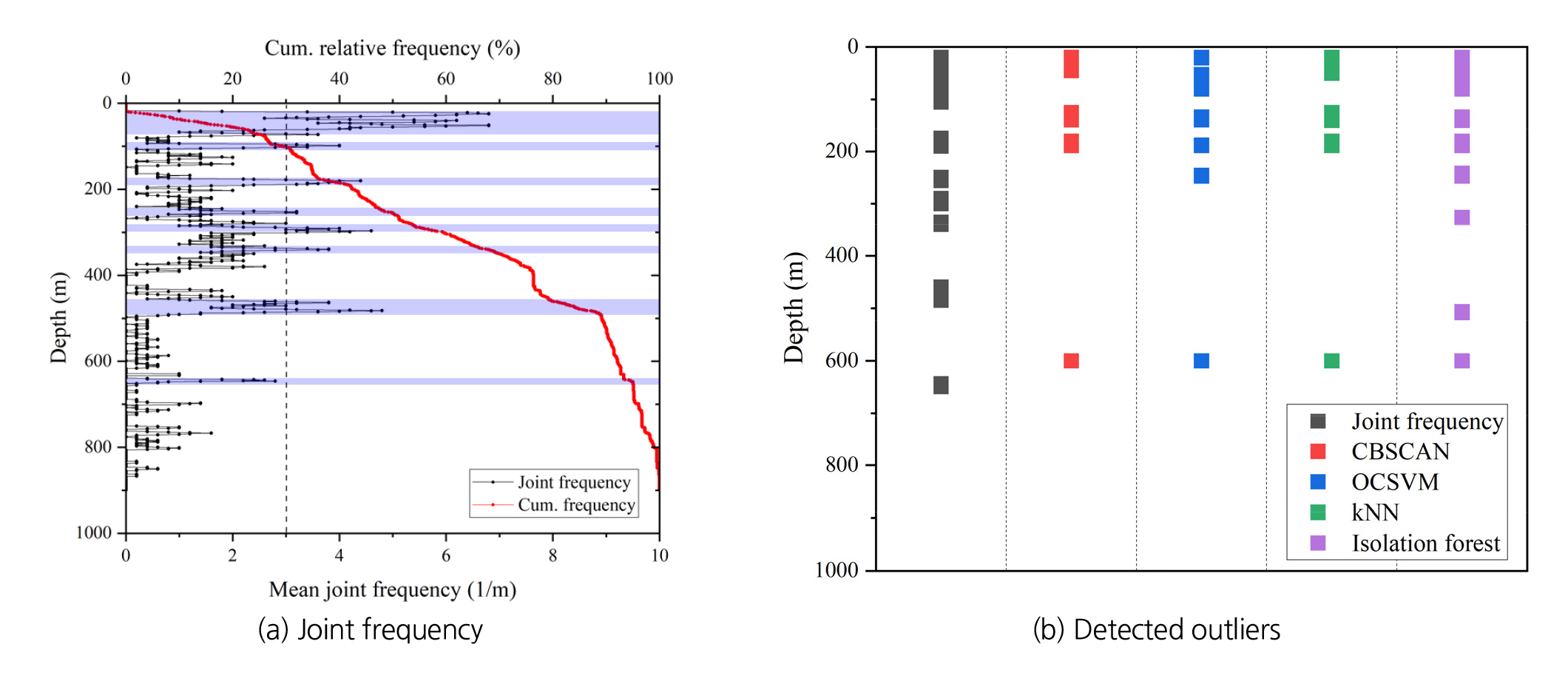
Fig. 7(b)에서 확인할 수 있듯, 초음파 주사검층 자료로 파악된 절리 고빈도 구간과 기계학습을 통한 수리 이상점 구간은 몇몇 구간에서 서로 중첩되지만, 전반적으로 어느 정도 차이를 보였다. 따라서 수리 유동성을 정확히 파악하기 위해서는 복수의 조사 기법을 적용하는 것이 바람직한 것으로 판단된다. Fig. 7(b)의 다섯 가지 분류 중, 최소 세 가지 이상의 항목이 중첩되는 구간을 수리 이상점이 포함된 잠재적 조사 구간으로 선정하였으며, 이는 20~45 m, 135~145 m, 175~190 m, 245~255 m, 600~615 m로 총 5개 구간이다.
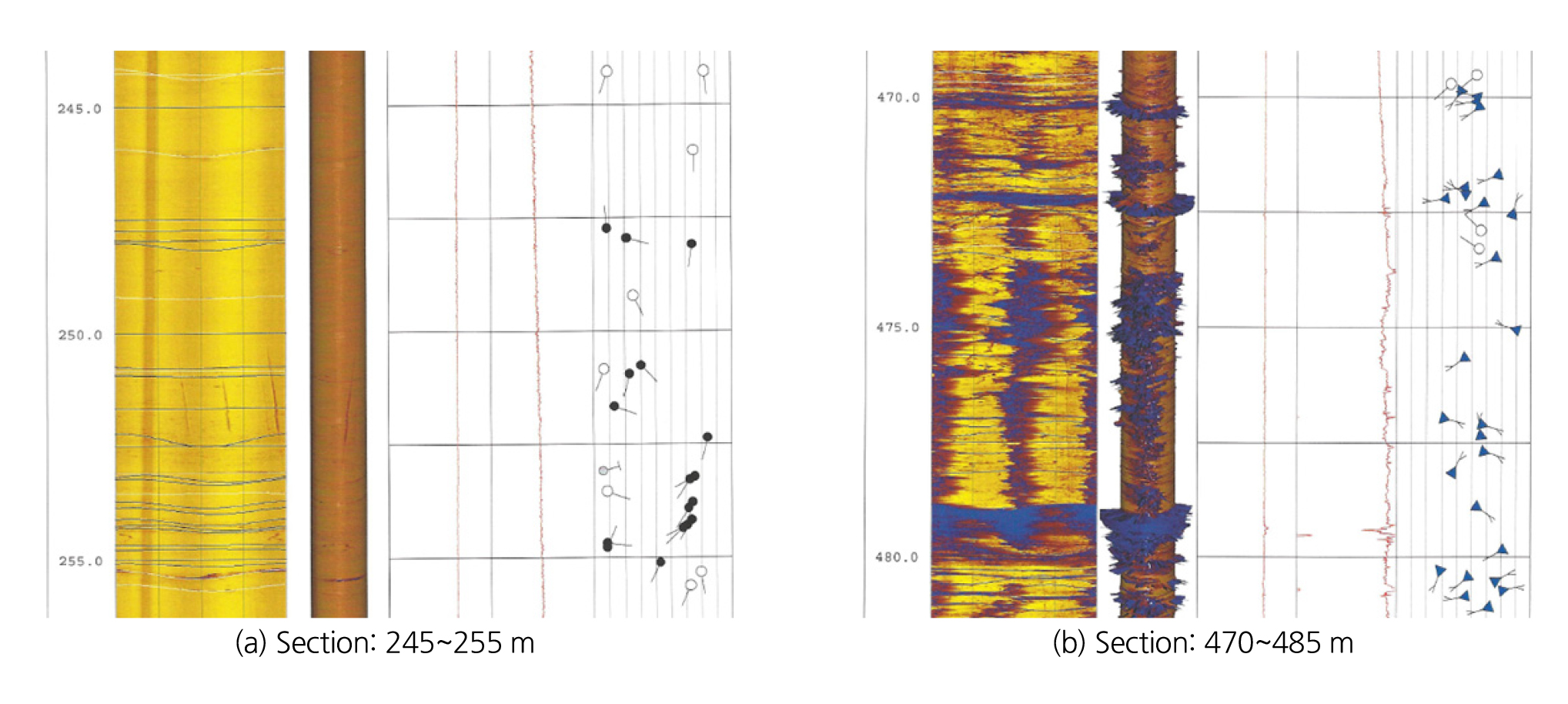
초음파 주사검층 결과 중 일부 구간을 발췌하여 Fig. 8과 같이 도시했으며, 개별 절리 표식은 각각 열린 절리(⭘), 닫힌 절리(⯄), 파쇄대(⯆)를 의미한다. Fig. 8(a)는 조사 구간으로 선정된 245~255 m 구간의 절리 분포이며, Fig. 8(b)는 절리 고빈도 구역이나 수리 이상점으로 판정되지 않은 470~480 m 구간이다. Fig. 8(a) 구간은 OCSVM과 isolation forest 두 알고리즘에 의해 수리 이상점으로 탐지되었으며, 조사 구간과 그 인근에 열린 절리(⭘)가 비교적 다수 분포하고 있는 것을 확인할 수 있다. 반면에 Fig. 8(b) 구간은 절리 빈도가 매우 높으며 다수의 파쇄대(⯆)가 존재하지만, 열린 절리의 비율이 상대적으로 낮은 것으로 파악되었다. 이러한 열린 절리의 분포는 수리 이상점 탐지 결과에 영향을 주었을 가능성이 있으나, 절리 개폐 여부가 반드시 수리 유동을 결정하지 않기 때문에, 참고자료로 활용할 수 있을 것으로 판단된다.
4. 결 론
한국원자력연구원은 심부 암반의 수리지질/지화학 특성 분석을 위해 KURT 내부와 그 인근에 다수의 조사용 시추공을 시추하고 각종 현장 시험을 수행 중이다. 시추공을 통한 지반 조사 시, 조사 목적에 적합한 시험 구간 선정은 매우 중요하다. 본 논문에서는 수리 유동이 확연하여 암반 수리물성 조사와 지하수 채수에 적합한 구간을 선정하고자 하였다. 대상 시추공은 KURT 인근에 위치한 심도 1 km 수준의 DB-2 시추공이며, 조사 구간 선정을 위해 시추공 물리검층 자료인 온도와 전기전도도 검층 자료를 활용하였다. 검층 자료는 적절한 전처리 과정을 거쳤으며, 전체 데이터에서 이상점에 해당하는 지점을 수리 유동 가능성이 높은 구간으로 가정하였다. 체계적이고 효율적인 이상점 탐지를 위해, 다양한 분야에서 널리 활용되는 DBSCAN, OCSVM, kNN, isolation forest 네 가지 기계학습 알고리즘을 적용하여 시추공 심도에서 수리 이상점을 파악하고자 하였다. 각 알고리즘은 최적화 과정을 통해 55, 12, 52, 68개의 수리 이상점을 탐지했으며, 탐지 결과에는 온도 보다 전기전도도의 영향이 크게 작용한 것으로 확인되었다. 심도에 따른 절리 빈도를 도시하였고 고빈도 구역으로 확인된 구간과 수리 이상점 탐지 구역을 비교하여, 최종적으로 20~45 m, 135~145 m, 175~190 m, 245~255 m, 600~615 m 5개 구간을 수리 유동 가능성이 높은 구간으로 판단하였다.
본 논문을 통해 시추공 조사 구간 선정을 위한 기계학습 알고리즘의 적용성을 평가하였다. 시추공 검층 결과를 적절히 전처리하여 전체 데이터 중 이상점에 해당하는 지점을 효율적으로 탐지할 수 있었다. 본 연구의 결과는 각 알고리즘의 적용성 평가뿐 아니라 향후 추가적인 시험 설계를 위한 기반자료로 활용할 수 있을 것으로 예상된다. 예를 들어, 장기적인 수리지화학 모니터링에 적합한 시추공 멀티패커시스템(MPS, multi-packer system) 등의 공내 장비를 설치하는 경우(SolExperts, 2023), 조사 구간(패커 구간) 선정 등에 활용할 수 있다. 다만 본 연구에서 알고리즘 학습에 사용한 자료는 온도와 전기전도도 검층 자료로, 자료의 종류면에서 상대적으로 제한적이었기 때문에 다양한 학습 자료를 활용할 수 있고 검증이 가능한 추가 연구가 필요한 것으로 판단된다. 현재 KURT 인근에 위치하며, 보다 다양한 검층자료가 존재하는 시추공 정보를 수집하고 있으며 이를 활용한 추가 검증을 수행하여 향후 보고할 계획이다.
