

1. 서 론
2. 균열 방향성의 정의와 표현
2.1 방향성
2.2 반구 투영법
2.3 수직 단위벡터와 극점
3. 균열 방향성 자료의 밀도 분석
3.1 밀도 계수 방법
3.2 구 표면에서의 계수
3.3 가중 함수들
4. 군집화 알고리즘
4.1 K-평균 방법
4.2 피셔혼합모델
4.3 군집의 수 및 초기값 설정
5. 자료의 적용과 분석
5.1 방향성 자료
5.2 밀도 등고선
5.3 군집화
6. 결 론
1. 서 론
암반 내에 분포하는 불연속면들(discontinuities)은 암반의 변형과 파괴에 영향을 주어, 불연속면들의 방향성(orientation)에 따라 거동과 특성이 달라지는 이방성을 갖게 한다. 따라서, 암반 불연속면들의 방향성은 암반을 대상으로 한 공학 설계에서 고려해야할 중요한 요소이다. 암반 내의 불연속면들은 생성 원인과 시기에 따라 유사한 방향성을 가지는 군집(cluster)으로 분류할 수 있으며, 특정한 관심 구역에서 하나 이상 수 개까지의 이러한 군집을 확인할 수 있다. 암반공학적 설계나 분석에서 개개의 불연속면들을 확인하고 그 영향을 반영하기보다 확인된 군집들의 군집별 특성을 주로 사용한다. 본 논문에서는 앞으로 층리, 절리, 단층 등 다양한 생성 원인과 특성을 가지는 불연속면들을 통칭하는 용어로 다양한 특성에 중립적이라고 볼 수 있는 균열(fracture)을 주로 사용할 것이며, 유사한 방향성을 지닌 균열의 군집은 균열군(frature set)으로 부르도록 하겠다(Chilès and Marsily, 1993, Ojeda et al., 2023, Zimmerman and Paluszny, 2023).
이러한 균열군을 확인하기 위해서 균열의 방향성을 반구투영도에 표시하여 서로 근접한 균열들을 하나의 군집으로 묶는 방법을 주로 사용해 왔다. 극점이나 극점의 밀도 등고선으로 표현된 반구투영도 상에 표시된 방향성들은 육안으로도 군집을 확인할 수 있는 경우가 많으므로, 이들을 군집으로 묶고, 각 균열군의 평균과 같은 대푯값을 계산하는 과정을 인력으로 수행하는 것이 가능하다. 그러나, 측정된 균열의 수가 많을 경우, 이 과정은 많은 시간이 소요될 뿐 아니라 계산 과정에 오류가 포함되거나 인위적 판단과 같은 주관이 개입될 가능성이 커지게 된다. 이 문제를 해결하기 위하여 자동으로 균열군을 확인하고 각 균열군의 대푯값을 구하는 시도들이 있어 왔다(Hammah and Curran, 1998, Marcotte and Henry, 2002, Jung and Jeon, 2003, Ruan et al., 2023).
균열의 방향성은 노두 조사와 시추 조사 등의 지반 조사 과정에서 얻어진다. 근래에는 시추 조사 과정에서 시추공 영상을 촬영하여 시추공 내부의 균열의 자취를 분석하여 시추공과 교차하는 균열의 방향성, 틈새 등의 자료를 획득하는 조사법이 적용되어 주로 노두 조사에 의존하던 과거에 비하여 균열 방향성과 특성 자료의 획득이 상대적으로 용이해지고 그 수도 증가하였다. 이처럼 처리해야할 자료의 수가 많아짐에 따라, 인력 작업의 비효율과 오류의 가능성은 커지고, 그 결과 균열군 확인과 통계 처리 과정의 자동화 필요성도 함께 커졌다고 볼 수 있다.
본 연구에서는 대표적 비지도 학습 인공 지능 군집화 기법인 K-평균 방법(K-means method)과 본 연구에서 제안한 이른바 피셔혼합모델(Fisher Mixture Model, FMM)을 기반으로하여 균열군을 자동으로 분류하고 통계적으로 분석할 수 있는 알고리즘을 개발하였다. 또한, 방향성들을 반구투영도 상에 밀도 등고선으로 표현하여 시각화하고 객관적 분석의 도구로 활용하기 위한 이론을 연구하였다. 이상의 성과들은 C++ 언어를 기반으로한 전산 프로그램인 알네트(Rnet)로 구현하였으며, 개발된 프로그램은 시추공 촬영 영상에서 측정된 암반 균열의 방향성 자료에 적용하여, 그 결과의 타당성을 검토하고, 이를 적용할 수 있는 응용 방안을 함께 제시하였다. 본 논문 내의 반구투영도와 계산 및 분석 결과는 모두 알네트를 통하여 구현된 것이다.
2. 균열 방향성의 정의와 표현
2.1 방향성
균열은 삼차원 공간 상에서 평평한 하나의 면으로 간주한다. 이 면이 수평면과 만나 이루는 교선의 방향이 그 면의 주향(strike)이다. 그리고 이 교선과 직각을 이루는 가상의 수직면과 균열면의 교선과 가상의 수직면과 수평면이 이루는 교선 사이의 각을 그 균열면의 경사(dip)라고 하며 뒤의 교선의 방향 중 아래로 아래로 경사 진 방향을 경사방향(dip azimuth)라고 한다. 본 연구에서는 경사방향과 경사를 사용하여 균열의 방향성을 표현하였다. 경사방향은 정북으로부터 시계 방향으로 측정한 각돗값으로 표기하며 그 범위는 [0–360]이 된다. 경사는 두 교선 사잇각 중 작은 값이며 그 범위는 [0–90]이 된다.
2.2 반구 투영법
방향성은 공간적인 정보이므로, 이를 지면과 같은 이차원 평면에 도식적으로 표현하는 것은 그 이해와 분석에 한계가 있다. 반구 투영(hemispherical projection) 또는 평사 투영(stereographic projection)은 이러한 한계를 극복하고, 삼차원적 방향성 자료를 정보의 손실없이 이차원 평면 상에 효과적으로 표현할 수 있는 방법이다.
균열면이 가상의 구의 중심을 통과한다고 가정할 때 이 면이 구의 표면과 이루는 교선은 구의 반지름과 동일한 반지름을 가지는 원의 모양이 된다. 이 중 구의 중심을 통과하는 수평면을 경계로 이 원을 아래와 위로 분할하고 상부의 반원 또는 하부의 반원을 수평면에 투영시켜서 그려진 자취로 균열면을 이차원 평면 상에 표현한다. 이 때 상부의 반원을 사용하면 상반구(upper hemisphere)투영이라고 하고, 하부의 반원을 사용하면 하반구(lower hemisphere) 투영이라고 한다. 이 때 평면 상에 그려진 호를 대원(great circle)이라고 한다. 평면 상에 그려진 구의 자취, 즉, 구와 동일한 반지름 가진 원에 비하여 큰 원의 호가 되므로 대원이라 하지만 엄밀하게는 구의 자취 원에 포함된 대원의 일부인 호로 그려진다. 균열면을 투영도 상에 대원으로 표현하는 것이 익숙해지면 상당히 직관적으로 방향성들의 분포와 이들 간의 관계를 파악할 수 있다.
반구 투영법에서 반구 상의 점이나 투영면(area of projection)은 이차원 평면 상에서 중복없이 표현된다. 이 투영면은 반지름 R을 가진 원이 되고 원에서 시계 방향으로 12시 방향이 북, 3시 방향이 동, 6시 방향이 남, 9시 방향이 서가 된다.
그 중심이 투영면의 중심과 일치하며 반지름 R을 가지는 기준 구(reference sphere)에서 선경사 방향 𝛼 와 선경사 𝛽 를 가지는 선이 이 구의 중심을 통과한다고 가정하면, 이 선은 기준 구(구의 표면)와 두 지점에서 교차하게 되며, 이 점을 극점(pole)이라고 한다(Fig. 1). 이와 같이 기준 구 상의 한 점인 극점은 이 점을 만드는 선의 방향성 하나와 대응하며, 이 위치를 평면 상에 투영하여 방향성을 표현할 수 있게 된다.
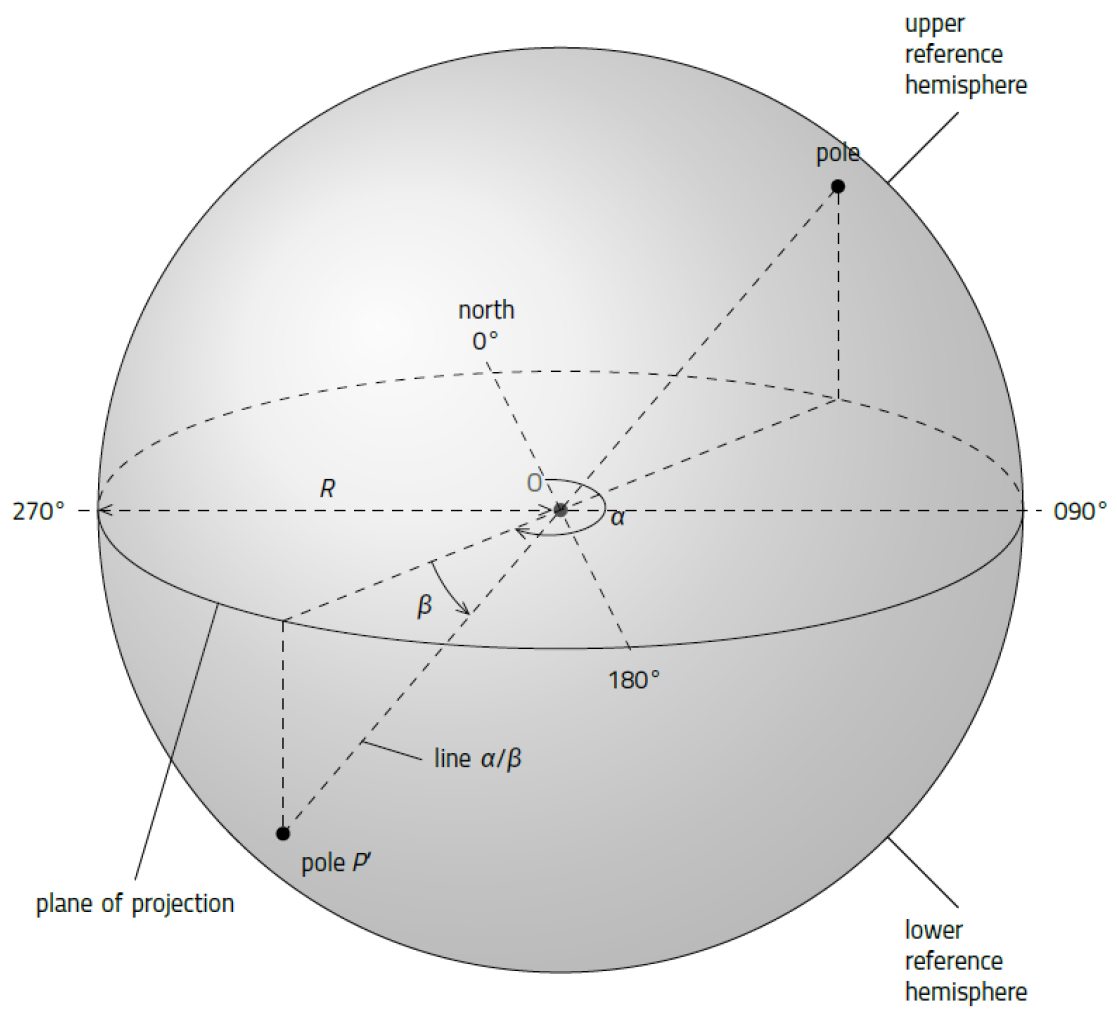
기준 구는 수평인 투영면의 윗 부분인 상반구와 아랫 부분인 하반구로 나누게 된다. 상반구는 선경사가 음일 경우(상향 경사)에만 대응하므로, 반구 투영에는 하반구를 사용하는 것이 편리하며, 본 연구에서도 하반구를 사용할 것이다.
2.3 수직 단위벡터와 극점
반구 투영도 상에 대원으로 방향성의 분포를 표현하는 방법 외에 구 표면과 균열면의 수직 벡터의 교점을 투영도 상에 표현하는 방법이 있다. 이 수직 벡터와 상반구 또는 하반구 표면의 교점을 사용하며, 투영도 상에서 하나의 점, 극점으로 표현된다.
대원으로 균열면을 표현하면 균열의 수가 많을 경우, 투영도 상에서 대원들이 복잡하게 얽히게 되어 직관적인 상황 파악이 어려워진다. 따라서, 많은 수의 균열들을 투영도 상에 표현할 때는 대원 보다는 극점을 사용하는 것이 편리하다. 극점의 분포 형태를 보면 직관적으로 균열면들의 방향성 분포 특성을 알 수 있으며, 그 특성에 따라 균열들을 군집으로 분류하는 것이 가능하다.
균열면 수직 벡터는 반구의 중심에서 반구의 표면에 이르는 벡터로, 만약 반구의 반지름을 단위 길이로 놓으면 이 수직 벡터는 단위벡터가 된다. 이렇게 균열면의 수직 벡터를 단위벡터로 표현하는 것은 분석의 편의성을 위함이다. 예를 들어 두 개의 균열의 평균 방향성을 구해야 한다면, 경사방향과 경사를 각각 평균 낸다면 원하는 결과를 얻을 수 없을 가능성이 매우 크다. 그러나, 단위벡터는 평균을 구하여 다시 방향성으로 변환하면 원하는 결과를 얻을 수 있다. 이 밖에도 벡터의 형식은 대수학적으로나 수치해석적으로 다루기에 매우 유리하다.
본 연구에서는 균열 방향성 자료를 균열면에 수직인 단위벡터로 환산하여 수치적 계산들을 수행하였다. 이 단위벡터 n̂의 성분은 Fig. 2와 같이 북쪽을 𝑥−축, 서쪽을 𝑦−축, 그리고 하향을 𝑧−축으로 하는 오른손 직교좌표계를 사용하고 하반구투영법을 적용하면 다음 식으로 구할 수 있다.
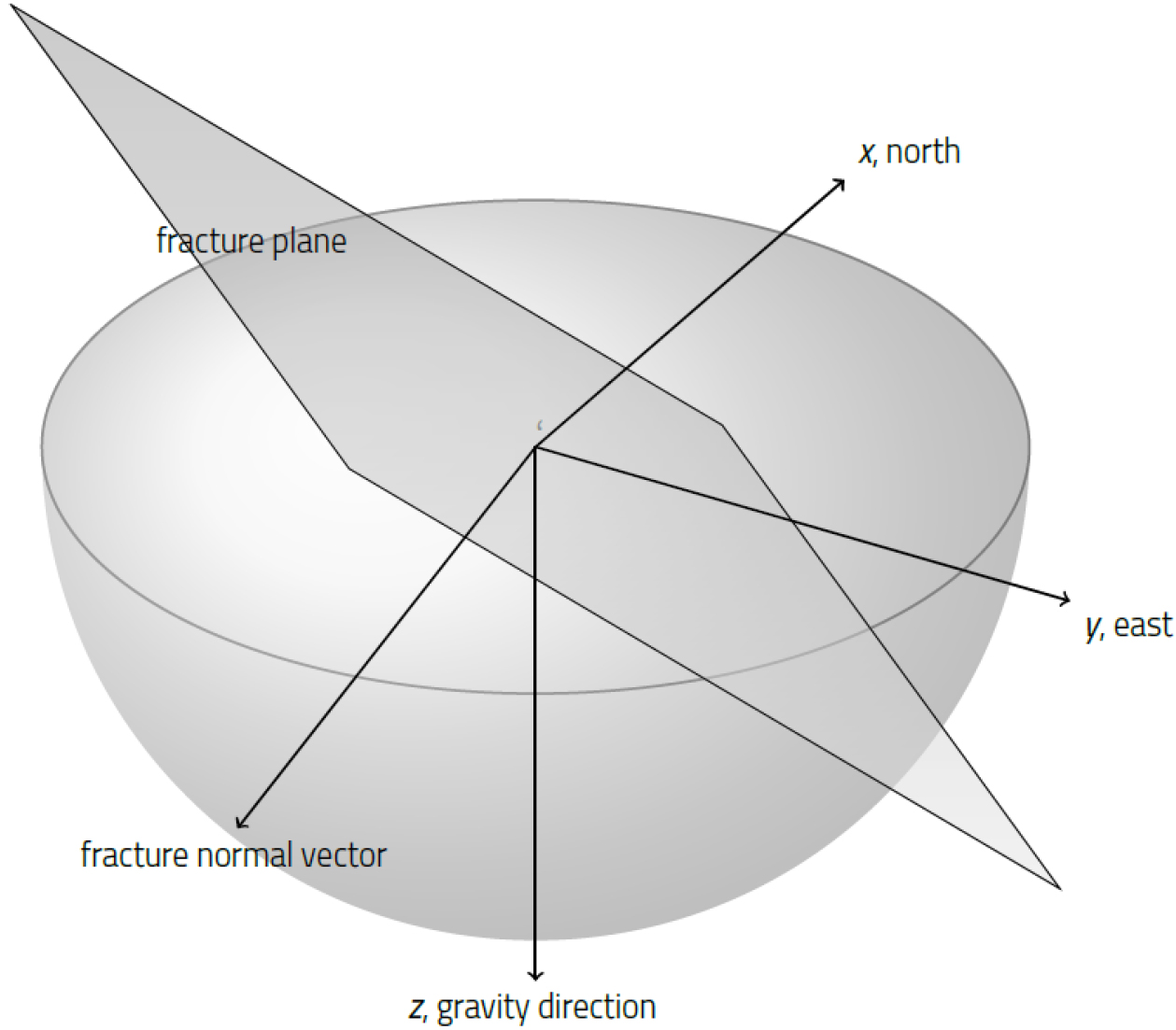
여기서, 𝛼 는 경사방향, 𝛽 는 경사이다.
3. 균열 방향성 자료의 밀도 분석
반구투영도에 방향성의 밀도 등고선(density contour)을 작도하면 방향성 자료의 분포 경향을 직관적으로 확인할 수 있다. 밀도 등고선을 작도하기 위해서는 투영도 상의 방향성 밀도 분포를 파악해야 한다. 슈미트 네트(Schmidt net) 방법에서는 전체 면적의 1%를 차지하는 계수원(counting circle)을 사용하여 규칙적 격자의 노드에서 밀도를 추정하고, 격자는 1% 면적당 밀도 백분율 단위로 등고선을 그리는 방법이 광범위하게 사용되어 왔으나, 등고선이 표본 크기에 크게 의존하기 때문에 자료군들을 비교하는 데 적합하지 않다는 문제점이 있다(Vollmer, 1995).
3.1 밀도 계수 방법
Kamb(1959)는 이항확률분포에 기초하여 밀도 분포도를 작성하는 방법을 제시하였다. 이항확률변수, 𝜇 와 𝜎는 다음과 같다.
여기서 p는 한번 시행에 성공할 확률, n은 시행의 수이다. 전체 면적 A에 균등하게 무작위로 분포한 n개의 점이 있다면 어떤 점이 주어진 임의의 면적 a 안에 있을 확률은 다음처럼 쓸 수 있다.
면적 a 안에 포함된 점의 수는 기댓값 E 가 평균 𝜇 인 이항확률변수로 볼 수 있다. a를 반지름 r인 원, A를 반지름 R인 원이라고 하면, 위의 식은 다음과 같이 고쳐 쓸 수 있다.
Kamb(1959)는 다음과 같이 이항확률 모델을 선정하여, 균등 분포 모집단에서 무작위 표본이 주어지면 계수원은 기댓값에서 크게 벗어나지 않을 만큼 충분히 크게 하였다.
이상의 식 (2), (3), (6)을 조합하면 다음과 같이 된다.
이 식을 다시 식 (5)에 대입하면, 계수원의 반지름은 다음 식으로 계산된다.
균등 분포에 대한 기댓값을 정의하는 표준 편차의 계수가 다를 수 있도록 허용하면 E = k𝜎 가 되고, 여기서 k를 표준 편차 단위의 기댓값이라고 하면, 식 (7), (8)은 다음과 같이 된다.
이 방법은 표본 크기에 따라 바람직한 계수원의 크기가 결정되므로, 등고선에 대한 표본 크기의 영향을 줄여 표본 크기가 다른 자료군들을 비교할 수 있도록 한다.
3.2 구 표면에서의 계수
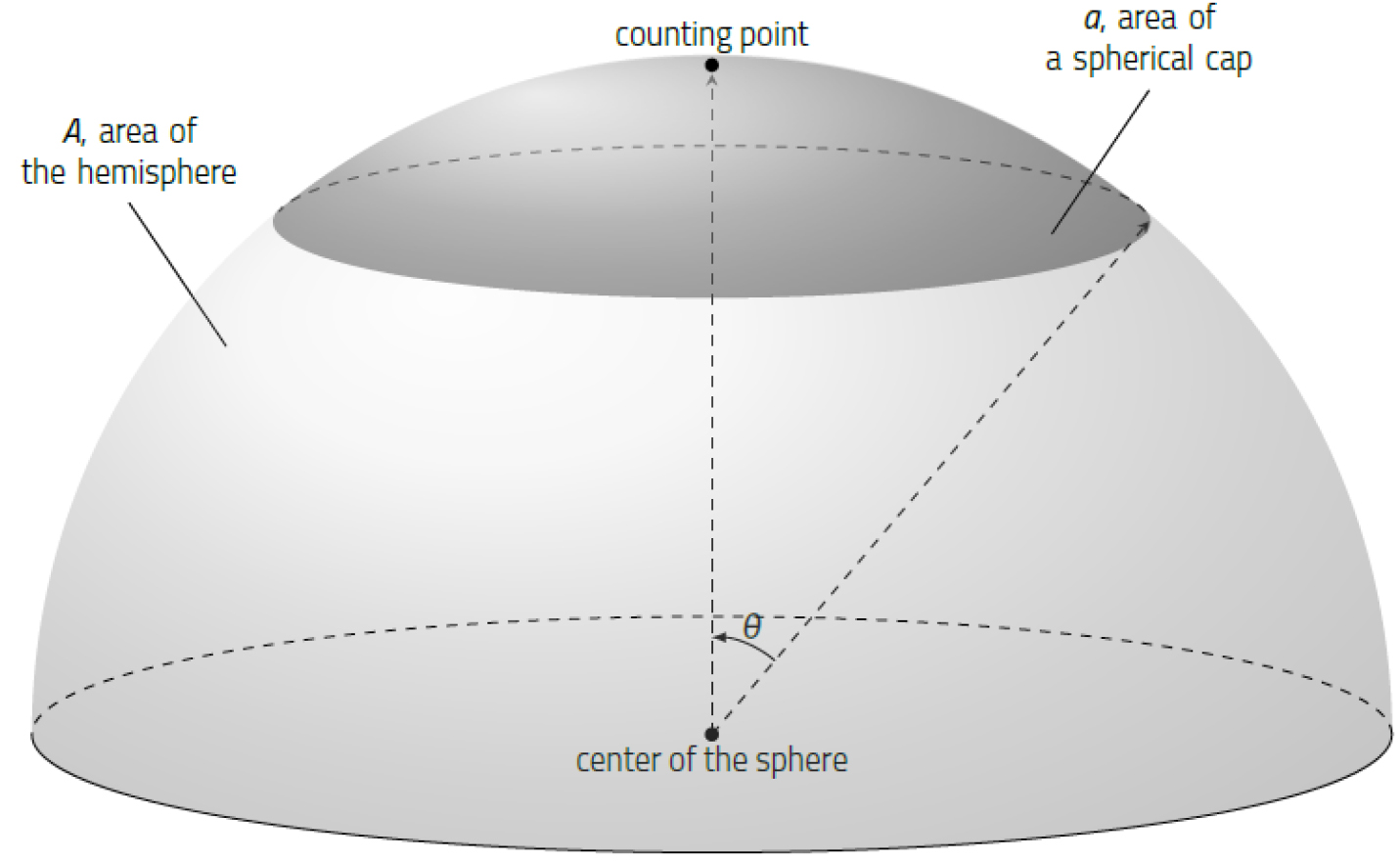
밀도를 구하기 위하여 투영도 상의 계수원을 사용하는 것 보다 구 표면에서 직접 세는 것이 더 단순하고, 더 정확한 방법이 될 수 있다(Vollmer, 1995). 구의 표면에서 계수원은 구형모(spherical cap)의 형태가 된다. 단위 구에서 구형모(Fig. 3)의 면적은 다음과 같다.
여기서, 𝜃 는 구형모를 형성하는 반중심각(semiapical angle)이다. 계수를 위한 구형모를 계수모(counting cap)라고 하면, 반구에서 표본이 계수모에 속할 확률은 다음이 된다.
식 (9)와 (12)로부터 cos𝜃 는 다음과 같이 계산된다(Robin and Jowett, 1986, Vollmer, 1995).
3.3 가중 함수들
계수원 안의 점들을 단순히 세는 것은 아주 만족스러운 결과를 보여주지 못한다. 이런 단순 계수법은 측정 범위를 나타내는 구면의 면적을 a, 측정 극점이 그 테두리에 위치하는 구면의 면적을 𝑥라 할 때, 가중값 𝑤는 다음과 같은 계단 함수(step function) 형태의 가중 함수(weighting function)로 표현할 수 있다.
단순 계수법의 결과를 개선하여 밀도 분포선을 보다 부드러운 곡선으로 구현할 수 있는 다음의 식 (15)의 단순 역면적 가중 함수(simple inverse area weighting function) 와 식 (16)의 역면적 제곱 가중 함수(inverse area squared weighting function)가 있다(Vollmer, 1995).
구 가우스(spherical Gaussian) 또는 피셔 분포(Fisher’s distribution)에 기초한 지수 가중 함수(exponetial weighting function)는 이상적인 단봉 분포(unimodal distribution)로 구 표면의 모든 점을 사용한다(Robin and Jowett, 1986). 지수 가중 함수는 일반적으로 식 (15)와 식 (16) 보다 더 부드러운 등고선을 가지며, 다음과 같다.
여기서, 𝛿 는 계수모의 중심과 표본의 사잇각이며, 계수 𝛼 는 계수모의 크기에 따라 변하는 데, 다음과 같은 근사적 관계를 가진다(Robin and Jowett, 1986).
4. 군집화 알고리즘
4.1 K-평균 방법
K-평균(K-means) 방법은 일반적 기계 학습(machine learning) 분야에서 널리 알려진 군집화 방법이다. 또한, 균열 방향성 자료의 자동 군집화에 사용되어온 방법 중 하나이다.
K-평균의 알고리즘은 군집의 갯수를 K개라고 하면, K개의 평균을 가정하고 각 자료들을 이 평균값들 중 가장 가까운 평균이 대표하는 군집에 속한다고 가정하고 각 군집을 평균을 계산하여 평균값들을 갱신하고, 다시 각 자료들을 가까운 평균값들이 대표하는 군집에 할당하는 과정을 반복하여, 각 자료의 군집 이동이 발생하지 않거나, 또는 미리 정한 상한 이하의 변화가 발생했을 때, 수렴한 것으로 간주하여 그 결과를 채택하는 방법이다(Géron, 2019).
K-평균 군집화는 N 개의 관측값으로 구성된 자료 세트 Xn 이 있고, 이 자료 세트가 K 개의 군집으로 나누어진다고 가정하고 각 군집의 중심 벡터를 𝜇k 라고 하고, Xn 이 𝜇k 에 속하면 1, 아니면 0의 값을 갖는 이진 지시 변수를 rnk 라고 하면 다음과 같은 목적 함수(objective fuction)을 최소화하는 과정을 통하여 구현할 수 있다(Bishop, 2006).
K-평균 방법의 장점은 수렴까지 계산 속도가 빠르고, 수렴이 대체로 잘 이루어지는 편이라고 할 수 있다. 그러나, 군집의 수와 초기 평균값을 할당해야 하므로, 이 가정에 따라 그 결과가 달라진다는 점이 문제점이라고 볼 수 있다.
4.2 피셔혼합모델
4.2.1 피셔 분포
본 연구에서 제안하는 피셔혼합모델(Fisher Mixture Model, FMM)은 표본들이 여러 개의 가우시안 분포에서 생성된 것으로 가정하는 가우시안혼합모델(Gaussian Mixture Model, GMM)의 방법론(Bishop, 2006)을 차용하여 측정된 방향성 표본들이 여러 개의 피셔 분포(Fisher’s distribution)에서 생성되었다고 가정한다.
피셔 분포는 다음 식과 같은 형태의 확률 밀도 함수(probability density function)를 가진다(Fisher, 1953, Watson, 1966, McFadden, 1980, Hutchinson et al., 2012).
여기서 𝜅 는 피셔 상수(Fisher contant)로 불리는 분산 계수(dispersion factor)이며, 𝜃 는 평균값과 측정값의 방향성 벡터 사잇각을 의미한다. 피셔 분포는 구 상에서 분포하는 방향성 벡터들을 모델링하는 데에 사용하는 확률 분포로서 단순함과 유연함으로 균열 방향성 자료에 대한 가치있는 모델을 제공한다(Priest, 1993).
4.2.2 피셔혼합모델의 정의
본 연구에서 개발한 피셔혼합모델 방법은 측정된 방향성 자료들이 여러 개의 피셔 분포를 이루고 있다는 가정에 기반하므로, 피셔혼합분포는 다음과 같이 K 개의 피셔 분포가 선형 중첩된 형태로 표현할 수 있다.
여기서, 𝜋k 는 혼합 계수(mixing coefficient)라고 하며, k번째 피셔 분포가 선택될 확률을 의미하므로, 다음 두 식을 만족해야 한다.
피셔혼합모델을 적용하여 군집화를 하는 것은 주어진 자료군 {𝜃n}에 대하여, 자료군의 피셔혼합분포 가능도(likelihood)를 최대화하는 각 군집의 모수들을 찾아가는 과정이라고 할 수 있다.
4.2.3 잠재변수 기반의 피셔혼합분포
잠재변수(latent variable)로 특정한 성분 하나만 1이고 나머지는 0인(“1-of-K”), K 차원의 이진 확률 변수 z를 도입하면, 어떤 성분이 0이 아닌지에 따라 벡터 z는 K 개의 가능한 상태가 있게 된다. 이제 잠재변수와 결합분포(joint distribution), p(𝜃, z)를 주변 분포(marginal distribution), p(z)과 조건부 분포(conditional distribution), p(𝜃 | z)으로 정의하면, 다음 형태가 된다.
z에 대한 주변 분포는 혼합 계수, 𝜋k 로 다음과 같이 특정된다.
z가 1-of-K 표현을 사용하므로, 이 확률 분포를 다음과 같은 형태로 쓸 수 있다.
조건부 분포도 위와 유사하게 주어진 특정한 z값에 의해 다음과 같이 특정된다.
조건부 분포 역시 다음 형태로 표현할 수 있다.
결합 분포는 p(z)p(𝜃 | z) 형태로 주어지고, 𝜃 의 주변 분포는 모든 가능한 z에 대하여 결합 분포를 더하여 다음과 같이 얻어진다.
위의 식은 결합 분포를 가지고 주변 분포를 표현했으므로 모든 표본, 𝜃n 에 대하여, 해당하는 잠재변수 zn 이 존재하게 되며, 주변 분포 p(𝜃) 대신 결합 분포 p(𝜃, z)를 사용할 수 있게 된다.
한편, 𝜃 가 주어졌을 때, z의 조건부 확률, p(zk | 𝜃)은 베이즈 정리를 이용하여 다음과 같이 구할 수 있게 되며, 이는 𝛾(zk)을 사용하여 표기하며, 부담율(responsibility)라고 한다.
4.2.4 가능도 함수
주어진 자료군, {𝜃1, 𝜃2, ..., 𝜃N} 이 독립적으로 동일하게 분포한다면(i.i.d.), 로그-가능도(log-likelihood)는 다음과 같이 정의된다.
여기서, 𝝅 = {𝜋1, 𝜋2, ..., 𝜋K}, 𝝁 = { 𝜇1, 𝜇2, ..., 𝜇K}, 𝜿 = {𝜅1, 𝜅2, ..., 𝜅K}이다. 피셔혼합분포에서 확률분포를 식 (22)와 같이 K 개의 피셔 분포의 선형 중첩으로 정의하였으므로, 이를 적용하면 로그-가능도는 다음 식과 같이 된다.
4.2.5 기댓값 최대화 알고리즘
본 연구에서는 이른바 기댓값 최대화 알고리즘(expectation-maximization algorithm, 이하 EM 알고리즘)을 이용하여 최대 가능도(maximum likelihood)를 만족하는 피셔혼합모델의 모수들을 구하였다. EM 알고리즘은 잠재변수를 가진 확률 분포에 대한 최대 가능도 해를 찾는 일반적인 기법으로, E 단계(Expectation step, E step)과 M 단계(Maximization step, M step)를 반복하여 가능도의 기댓값을 최대화한다(Bishop, 2006). EM 알고리즘을 적용하여 각 군집의 피셔분포 모수들의 최대 가능도 해를 구하는 과정은 다음과 같다.
1. 매개변수 초기화: 각 피셔 분포의 평균, 𝜇k, 피셔 상수, 𝜅k, 혼합계수, 𝜋k 와 같은 매개변수들의 초기값을 설정한다.
2. E 단계: 현재의 매개변수들을 가지고 부담률, 𝛾k 를 평가(갱신)한다.
3. M 단계: 현재의 부담률을 가지고 매개변수들을 평가(갱신)한다.
k번째 평균, 𝜇k 은 다음과 같다.
각 측정값의 방향성 벡터를 Vn, 각 피셔 분포의 결과 벡터를 Rk = 𝛾(znk)Vn 이라고 하면, 다음 식과 같은 𝜅 의 최대 가능도 추정(maximum likelihood estimation), k (Fisher, 1953, Watson, 1966, McFadden, 1980)의 값을 구하여 k번째 피셔 상수, 𝜅k 를 갱신한다.
k번째 혼합계수, 𝜋k 는 다음과 같다.
여기서, Nk 는 다음으로 계산되며, 의미상 k 군집에 속하는 표본의 수와 같다.
4. 로그-가능도 평가:식 (33)의 로그-가능도를 구하여 수렴 조건을 만족하면 종료하고 그렇지 않으면 두 번째 단계로 돌아간다.
피셔혼합모델을 사용하여 군집화를 시행하면, 피셔 분포에 최적화된 군집화 결과를 얻을 수 있으며, 그 결과는 균열 군집화 결과를 개별 균열망(Discrete Fracture Network, DFN) 생성에 적용하는 데에 편리하다는 장점이 있다.
4.3 군집의 수 및 초기값 설정
K-평균과 피셔혼합모델 방법은 군집 수를 지정해 주어야 한다. 군집의 수는 여러가지 군집의 수를 가정하여 실시한 군집화 결과를 관성(inertia), 실루엣(silhouette) 기법 등으로 평가하여 최적인 군집의 수를 결정하는 방법도 있으나(Géron, 2019), 본 연구에서는 반구투영도 상에서 측정값의 밀도 등고선도에서 첨두값의 수와 위치를 이용하여 군집의 수와 각 군집의 초기 평균을 설정하였다.
5. 자료의 적용과 분석
5.1 방향성 자료
본 연구에서는 균열 방향성 자료 자동 군집화 방법의 시험과 적용을 위하여 12개의 시추공 영상 촬영 자료들을 사용하였다. 이 자료들은 실제 사업을 위한 설계 단계의 지반 조사 과정에서 얻어진 자료들이다. 다만, 본 연구의 목적에 비추어 필수적이지 않은 사업명이나 위치 등 자료의 구체적 출처 정보는 밝히지 않았다.
편의를 위해 이 방향성 자료군들을 B1에서 B12까지 명명하였다. 다음 Table 1은 자료들의 기본 정보를 요약해서 보여준다. 각 자료군들은 시추공 영상 분석 소프트웨어에서 추출한 균열 자취들의 경사방향과 경사, 위치(심도) 등의 정보를 포함하고 있다. 측정된 균열의 수는 최소 112개에서 최대 599개까지이며, 측정 균열 수를 측정 구간 전체 길이로 나눈 값인 균열 빈도(fracture frequency)는 최소 3.04 m-1, 최대 7.52 m-1 이다. RQD는 80.69에서 94.72로 계산되었으며, 이론적 RQD*는 균열 간격이 음지수 분포(negative exponential distribution)를 따른다고 가정하여 균열 빈도로부터 다음 식을 통해 구한 값이다(Priest and Hudson, 1976).
Table 1.
Information of fracture orientation data sets
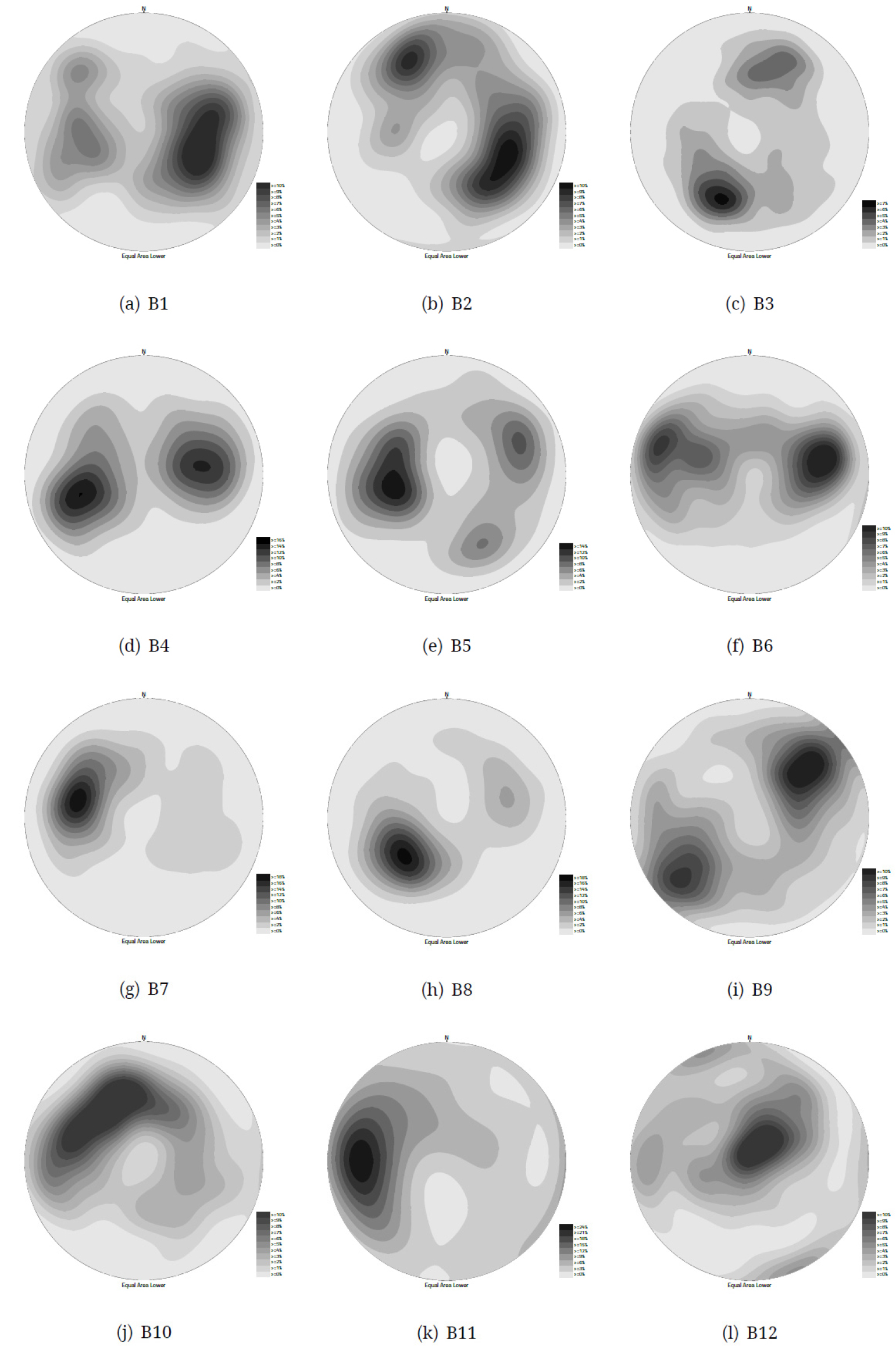
Fig. 4에는 각 자료군들의 방향성 극점들이 하반구 등적 투영도 상에 표시되어 있다. 그림 상에서 극점들이 몰려 있는 부분들을 확인할 수 있으며, 이들을 각 방향성 군집의 중심부로 판단할 수 있다.
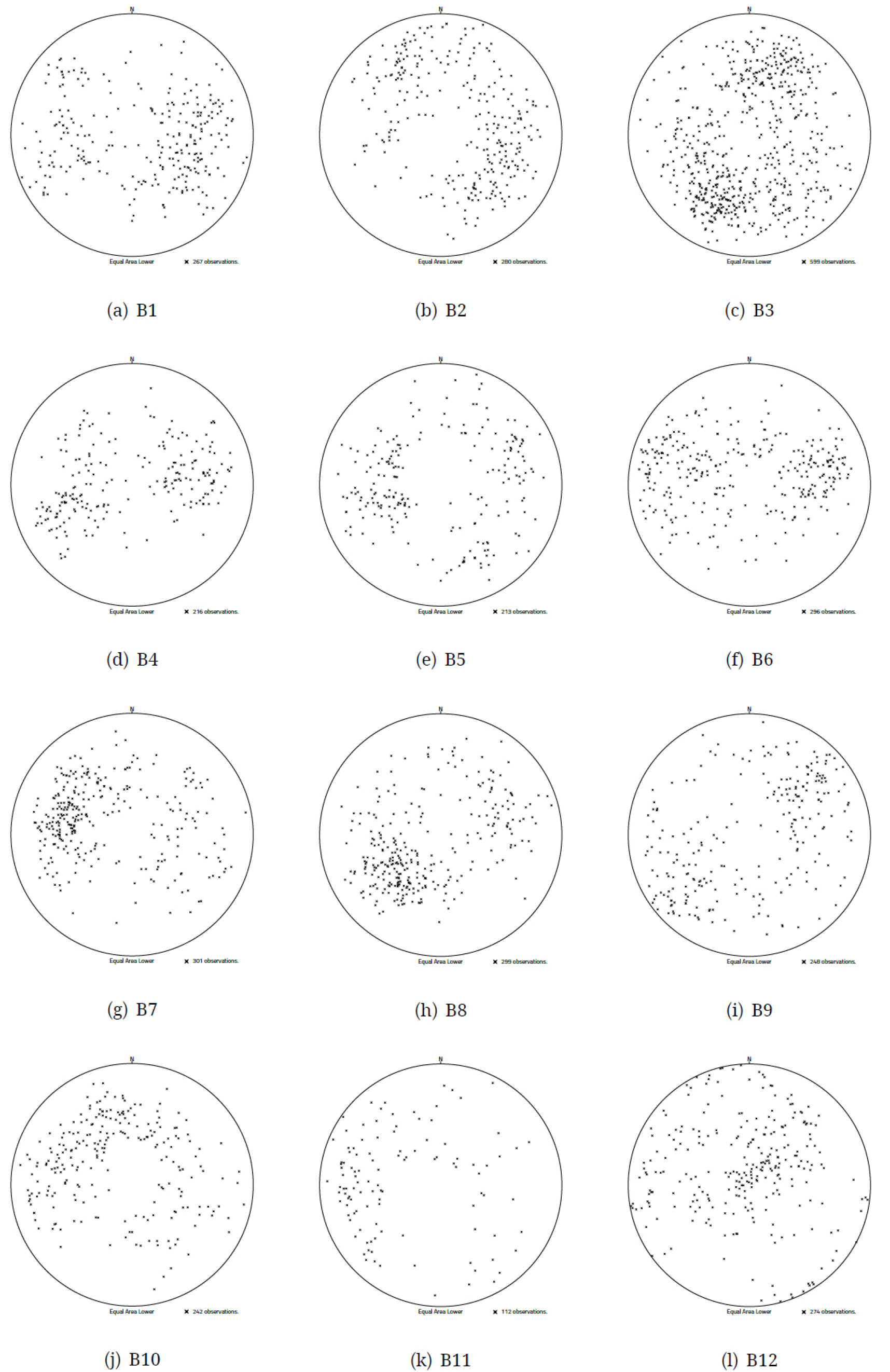
Fig. 5는 각 자료군들의 방향성 극점들의 밀도 분포를 보여 준다. 밀도가 높을수록 짙어지는 밀도 분포의 투영도는 가장 짙게 표현된 부분들이 각 방향성 군집의 중심부라는 점을 쉽게 확인할 수 있으므로 단순한 극점 도시보다 더 확연하게 방향성 군집들의 형태와 그 중심부를 드러낸다.
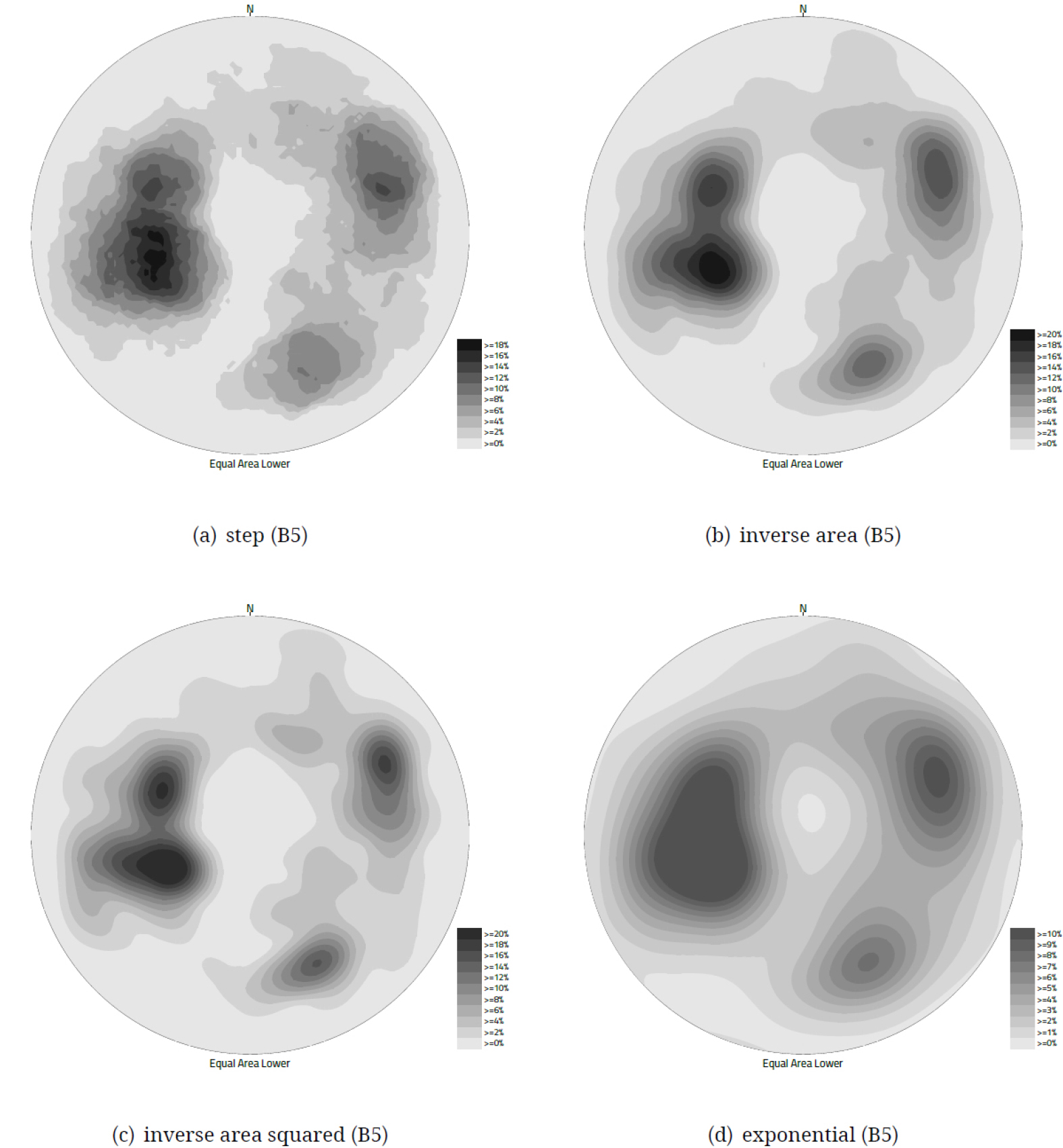
5.2 밀도 등고선
밀도 등고선을 위한 방향성 자료의 계수는 3.3절에서 논의된 가중 함수들을 통하여 이루어진다. 다음 Fig. 6에는 B5 자료에 서로 다른 가중 함수들을 적용한 밀도 등고선 결과가 나와 있다. Fig. 6(a)는 가장 단순한 형태의 계단 함수를 적용한 결과로 등고선이 부드럽게 이어지지 않은 모습을 보이고 있다. 반면 Fig. 6(b)의 단순 역면적 함수와 Fig. 6(c)의 역면적 제곱 함수의 경우는 등고선이 부드러운 곡선으로 이어져 있음을 알 수 있으며, 역면적 제곱 함수의 경우가 보다 부드러운 곡선을 나타내지만 이 두 함수의 적용 결과의 큰 차이는 보이지 않는다. 마지막으로 Fig. 6(d)의 지수 함수를 적용한 결과를 살펴 보면 모든 함수 중에서 가장 부드러운 곡선으로 표현되고 있으며, 그 양상도 나머지 함수의 결과와 다소 차이를 보이고 있는데, 이는 다른 함수들의 밀도 계산은 계수원(또는 계수모) 안의 표본들에 국한되는 반면, 지수 함수의 경우는 반구 전체의 표본을 모두 사용하기 때문에 나타나는 결과이다. 특히, 방향성이 분포하고 있지 않은 측정점에서도 원리상 밀도가 0이 되지 않기 때문에 가장 낮은 밀도 범위의 면적이 상대적으로 작게 나타나는 경향이 있다. 또한 인접한 표본 밀집 구역은 하나의 첨둣값을 가지는 구역으로 표현된다.
가중 함수에 따라 밀도 계산 결과가 어떻게 다른지를 살펴 보기 위하여, B3, B5, B11의 자료군에 대한 각 가중 함수를 적용하여 밀도 계산을 수행한 결과가 Table 2에 정리되어 있다. 자료군 마다 표본의 수가 상이하므로, 자료군 마다 계수모의 면적을 달리하여(3.1 절), 밀도 계수가 수행된다. 계수모의 면적은 표본의 크기, n과 기댓값과 표준 편차의 관계에서 계수 k에서 결정된다(식 (10), (13)). 본 연구에서는 Vollmer(1995)를 준용하여 k = 3을 사용하였으며, 그 결과는 Table 2와 같다. 지수 함수의 경우는 전체 표본을 모두 밀도 계산에 사용하기 때문에, 계수모의 개념은 필요하지 않으나, 이 역시 k와 n에 따라, 계수 𝛼 가 결정되므로, 표본의 크기 영향을 받으며, 𝛼 는 계수모의 면적비와 반비례 관계로 계수모의 면적비는 표본들이 무작위로 분포할 경우, 기댓값과 의미 상 동등하게 된다.
Table 2.
Density calculation results using various weighting functions
가중 함수별 결과에서 각 측정점에서 계산된 밀도 중 최댓값을 살펴 보면 계단 함수 보다는 단순 역면적 함수의 결과가, 단순 역면적 함수의 결과 보다는 역면적 제곱 함수의 결과가 그 값이 크게 나타나나, 단순 역면적 함수와 역면적 제곱 함수의 결과는 그 차이가 미미한 편이며, 지수 함수는 가중 함수 중 가장 낮은 값의 최댓값 결과를 나타내고 있다. 밀도 계산의 범위가 제한되는 다른 함수와 달리, 지수 함수에서는 최솟값은 0이 아닌 값으로 계산된다.
이와 같이 어떤 가중 함수를 적용하여 밀도 계산을 하느냐에 따라 밀도 등고선도의 결과는 다르게 나타난다. 따라서, 이 상이한 결과는 각 가중 함수가 지니는 의미에 따라 평가하고 분석해야 한다. 다만, 본 연구에서는 분석과 자료 비교의 일관성을 위하여, 확률 분포와 연관성과 부드러운 곡선으로 표현되는 장점을 가진 지수 함수를 가중 함수로 사용한 밀도 등고선도를 주로 사용하였다.
5.3 군집화
5.3.1 군집의 수
균열 방향성 자료의 군집화에서 가장 먼저 이루어져야 할 작업은 해당 자료에 몇 개의 군집이 있느냐를 결정하는 것이다. 이 군집의 수는 인위적인 방법에서 뿐 아니라, K-평균 방법과 본 연구에서 제안한 피셔혼합모델에서도 방법의 특성 상 결정하여야 할 일종의 초매개변수(hyperparameter)이다. 또다른 초매개변수로는 결정된군집의 수에 해당하는 초기 중심점, 즉, 각 군집의 대푯값이다.
먼저 군집의 수에 대하여 살펴보면, 인위적인 군집 분류 방법에서는 극점 분포(Fig. 4)를 육안으로 검토하는 과정을 통하여, 군집의 수를 결정하거나 좀 더 편리한 방법으로 극점의 밀도 등고선도(Fig. 5)를 이용하는 것이다. 군집화 알고리즘을 적용하여 인위적인 개입을 배제하더라도, 본 연구에서 사용한 두 가지 방법 모두 군집의 수는 초매개변수에 해당한다. 즉, 사용자의 경험적인 판단에 의한 결정이 필요한 매개변수라는 의미이다.
일반적인 군집화 알고리즘이 다루는 다양한 자료들과 비교하여, 방향성 자료의 군집의 수는 그 범위가 한정되어 있다. 대체로 1에서 4까지의 범위가 일반적이라고 볼 수 있다. 따라서, 제한된 범위의 군집의 수를 적용한 군집화 결과를 가지고 판단하는 방법을 적극적으로 고려할 수 있을 것이다. 이 방법을 적용할 경우, 군집의 수의 적정성을 판단할 수 있는 지표로 관성(inertia)과 실루엣 점수(sillhouette score)을 고려해볼 수 있다(Géron, 2019). 관성은 각 샘플이 속한 군집의 중심과 거리의 제곱을 평균한 값을 말한다. 이는 K-평균 알고리즘의 목적함수 식 (20)을 표본의 수로 나눈 값과 동일하다. 군집의 수 관점에서 보면, 이 값이 최소화 되는 군집의 수는 표본의 수와 동일하게 될 것이므로 단순히 관성의 최솟값을 가지는 군집의 수를 찾는 것은 무의미하며, 군집의 수에 따라 변하는 관성의 변화 추이를 보고 변화의 기울기가 완화되는 지점의 군집의 수를 최적으로 판단하는 방법이 있다(Bishop, 2006, Géron, 2019).
실루엣 점수는 한 표본 i와 그 표본이 속한 군집 내의 모든 표본과의 거리의 평균을 ai, 또 그 표본과 가장 가까운 거리에 있는 그 표본이 속하지 않은 군집 내의 모든 표본과의 거리의 평균을 bi 라 할 때, 다음 값을 그 표본의 실루엣 계수(sillhouette coefficient), si 라고 한다.
실루엣 점수 S 는 모든 표본에 대한 실루엣 계수의 평균이다.
Fig. 7에는 각 자료군을 1에서 5개까지 군집의 수를 변화시켰을 때, 관성이 변화하는 추이를 보여주고 있다. 각 자료군의 그래프에서 K 값의 증가함에 따라 동일하게 관성도 작아지므로, 관성의 크기가 아닌 변화의 추세를 봐야 한다. 각 추세 곡선에서 변화의 기울기가 완만해지는 지점의 K 값을 해당 자료군의 적절한 군집의 수로 판단한다. 그러나, 그래프들을 살펴보면 추세 곡선이 이는 부분이 분명히 드러나는 경우(B1, B2, B4, B5, B6, B8, B9)도 있지만, 꺾이는 부분이 잘 드러나지 않거나, 변화의 크기가 작아 판단하기 어려운 경우(B3, B7, B10, B11, B12)도 관찰된다. 꺾이는 지점이 있는 것으로 판단되는 경우 중 B5의 경우만 꺾이는 지점은 K 가 3일 때이고, 나머지는 모두 K 가 2일 때인 것으로 판단된다.
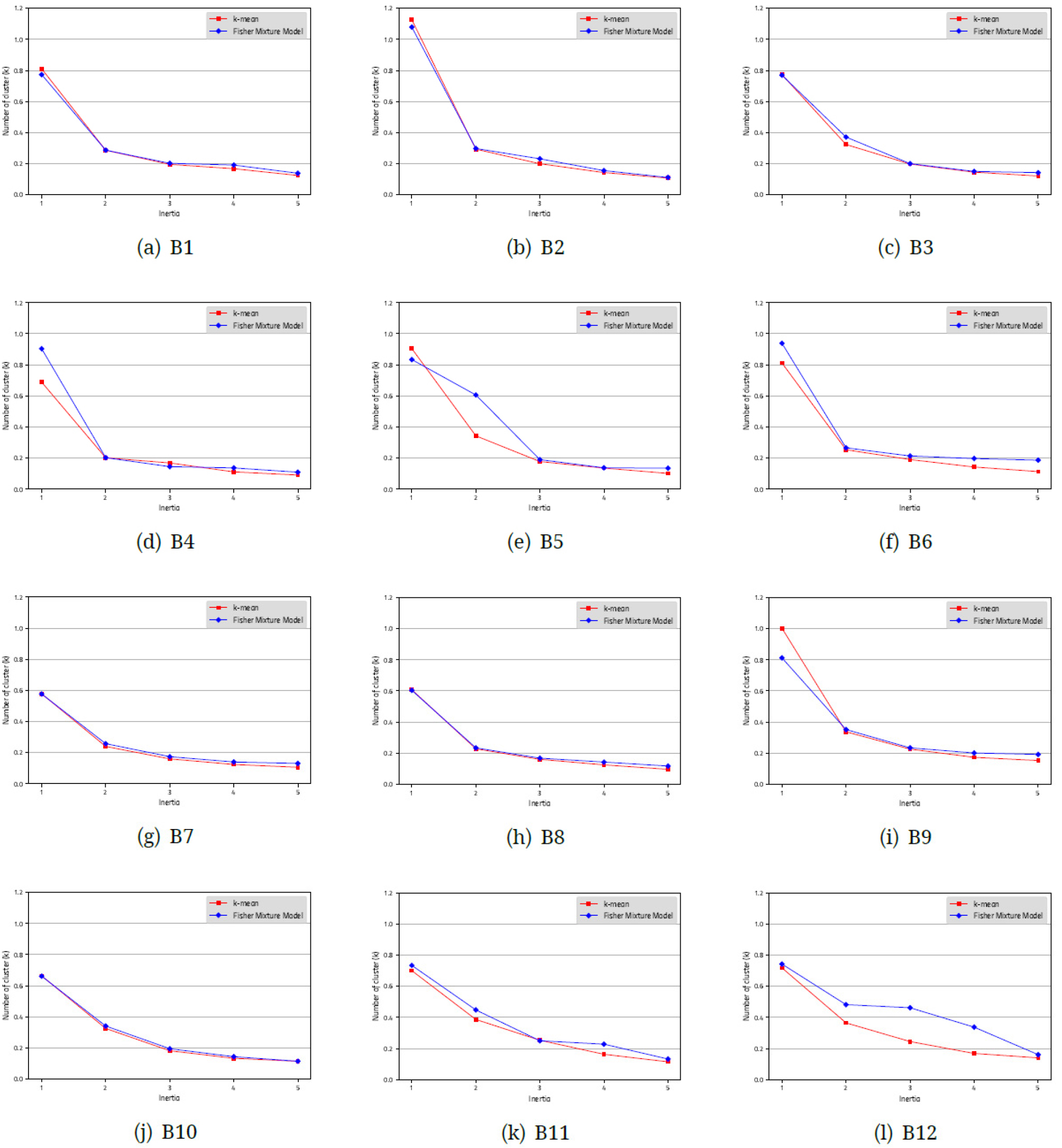
Fig. 8에는 군집의 수에 따라, 실루엣 점수가 변화하는 추이를 보여준다. 실루엣 계수의 경우는 큰 값일 경우가 적절한 군집의 수로 판단할 수 있으므로, 판단의 기준은 명확하다고 볼 수 있다. 그래프에서 결과를 살펴 보면, k가 2일 때가 최적인 경우는 B1, B2, B4, B6, B7, B8, B12이고, 3일 때가 최적인 경우는 B3, B5, B9, B10 이 있다. B11의 경우는 군집화 알고리즘에 따라, K-평균 방법의 결과는 2가, 피셔혼합모델을 적용한 결과는 5가 최적인 것으로 나왔으나, 피셔혼합모델의 경우는 결과값의 차이가 크지 않아 판단의 근거가 부족하다고 판단되어, B11의 경우도, 2가 최적인 결과로 판정을 하였다.
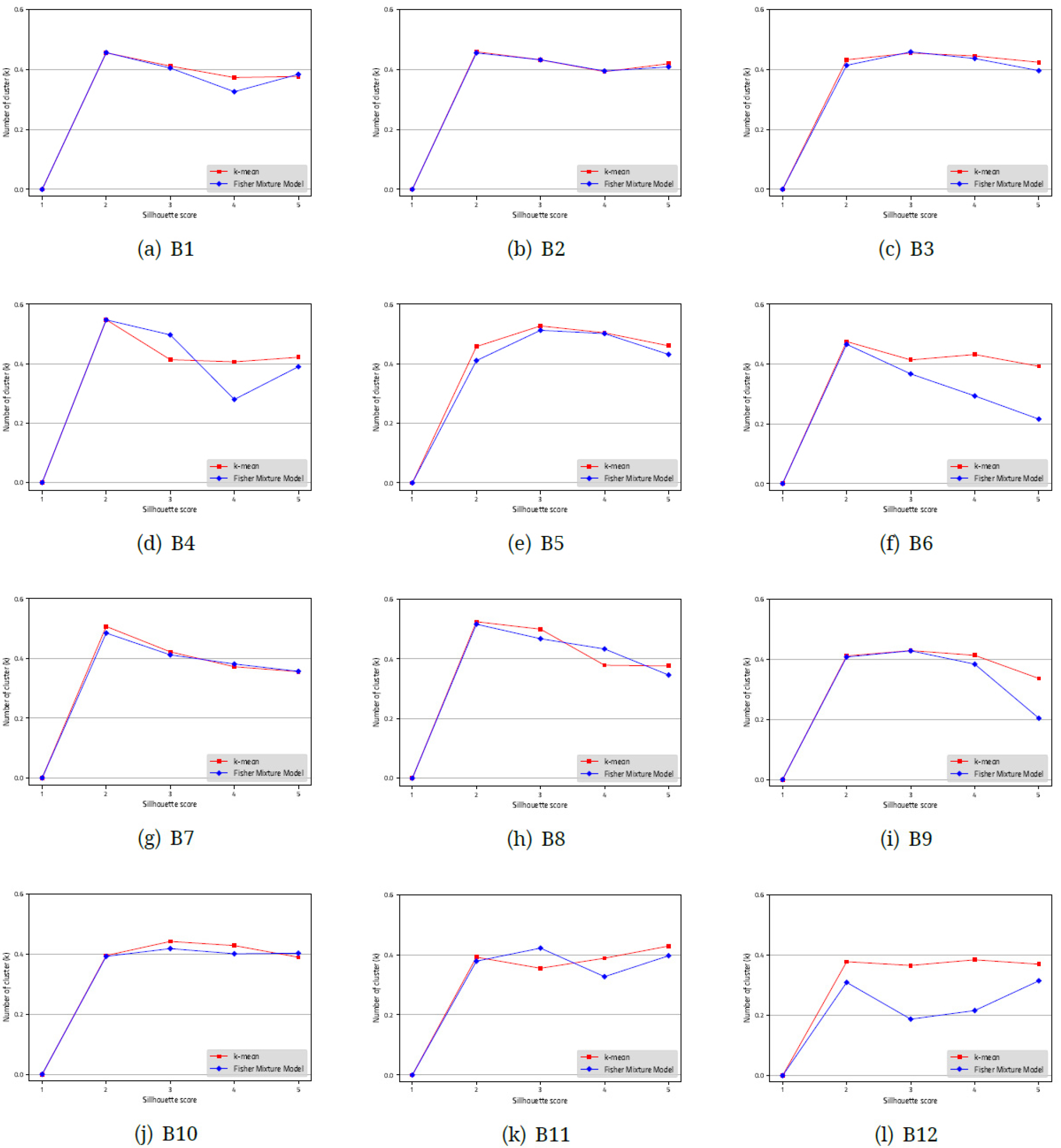
관성과 실루엣 점수를 구하여, 최적인 군집의 수를 결정하는 방법은 세 가지의 문제점을 가지고 있다. 첫번째는 관성 결과로 판단하는 경우, 꺾이는 지점이 명확하게 나타나지 않는 경우가 있어, 판단의 근거를 삼기 어려우며, 실루엣 점수의 경우도, 최댓값이 두드러지지 않거나, 값이 오르내리는 진동의 양상을 보일 때가 있으므로 단순 최댓값을 적용하기 어렵다는 점 때문에 주관적 판단의 여지가 크므로, 이 과정 자체를 자동화하기 어렵다는 점이다. 두번째는 군집의 수가 하나인 경우를 찾아내지 못한다는 점이다. 모두 균열 방향성 자료들이 둘 이상의 균열군으로 분류할 수 있는 것이 아니다. 그러나, 관성은 처음 계산 결과가 k = 1일 때이므로, 변화의 추이를 볼 수가 없으며, 실루엣 점수의 경우는 그 계산 원리 상 군집이 하나일 경우는 계산이 불가능하다. 세 번째는 4∼5회 이상의 군집화를 반복하여 그 결과를 비교해야 한다는 점이다.
본 연구에서 제안하는 방향성 자료의 군집의 수 결정 방법은 밀도 등고선 작성에 필요한 격자망의 밀도값을 이용하는 것이다. 방향성 군집들이 가우시안 분포를 하고 있다면, 각 군집의 중심점 근처의 표본 밀도가 높게 나올 것이다. 그렇다면 인접한 주변 격자보다 높은 밀도를 보이는 첨둣값을 가진 격자망에서의 위치는 방향성 군집 중 하나의 중심점과 가까운 위치일 가능성이 높을 것이며, 첨둣값의 수가 해당 방향성 자료의 군집의 수와 관련이 깊다고 볼 수 있다. 격자망 상의 첨둣값의 위치는 그 결과로 그려지는 밀도 등고선도에서 확인할 수 있다(Fig. 5). 밀도 등고선에서 첨둣값으로 판단될 수 있는 위치는 B1, B2, B5, B12의 경우 3개소, B3, B4, B6, B8, B9의 경우 2개소, B7, B10, B11의 경우 1개소가 육안으로 확인된다. 그러나, 밀도 등고선을 육안으로 보고 첨둣값을 판단하는 것 역시 주관적 요소의 개입이 불가피하고, 밀도 등고선의 간격과 해상도에 따라 밀집부의 형상이 달라질 수 있다는 문제가 있다. 특히, 큰 밀도를 가진 첨둣값 위치와 인접한 상대적으로 낮은 첨둣값의 위치는 독립적인 군집의 중심부로 보기 보다는 표본 분포의 무작위성으로 나타나는 부분적인 결과로 판단할 수 있으므로, 이를 결정할 객관적이 기준이 필요하다. 따라서, 격자망에 할당된 첨둣값 밀도값이 특정한 임계값 이상일 때만 군집의 중심값으로 간주하는 방법을 적용하였다. 임계값(threshold), Th는 식 (12)의 계수모에 표본이 속할 확률, p와 표본의 수, n을 곱한 기댓값. E 에 임계값을 조정하는 임계 계수, cth를 곱한 값으로 계산한다.
이 식에서 임계 계수의 의미는 반구 상에서 방향성 자료가 푸와송 분포를 따른다고 할 때, 어떤 격자망 위치에서 예상되는 기댓값 보다 계수된 기댓값이 임계 계수배 이상 크다면 이 위치를 방향성 군집 중 하나의 초기 중심값으로 간주하겠다는 것이다.
Table 3은 이상에서 설명한 군집의 수 결정 방법들을 방향성 자료군에 적용한 결과를 정리한 것이다. 관성의 변화 추이에 따른 군집의 수 추정 결과와 실루엣 점수에 의한 결과는 유사하지만 관성의 경우, 군집의 수 추정 어려운 자료군이 몇몇 있으며, 두 방법 공통으로 군집의 수가 하나인 경우를 제시할 수 없다. 밀도 등고선 육안 판별을 통하여, 밀도 첨둣값 위치를 확인한 결과는 군집의 수 추정 결과의 범위가 넓어졌으며, 군집의 수가 하나인 경우도 제시되고 있음을 알 수 있다. 한편, 입력한 임계 계수에 따라, 군집화 프로그램에서 자동 설정되는 군집의 수는 임계 계수의 값이 작을수록 결정되는 군집의 수가 많아지며, 반대로, 임계 계수가 커지면 군집의 수는 감소하게 된다(Table 3). 임계 계수 1.25, 1.5, 1.75, 2.0를 적용한 결과를 살펴보면, 임계 계수 1.25의 결과가 밀도 등고선을 관찰하여 결정한 육안 판별의 결과와 매우 유사하게 나타난다는 것을 알 수 있다. 임계 계수가 1.75인 경우는 적용한 결과는 실루엣 점수가 높은 경우와, 임계 계수가 2.0인 경우는 관성 변화 추이로 결정한 것과 유사한 군집의 수를 제시하고 있다. 이상의 결과, 임계 계수의 범위는 1.25에서 2.0가 적정한 것으로 판단할 수 있다.
Table 3.
Number of clusters estimated by various methods
반구상의 밀도 첨둣값 위치를 활용한 군집의 수 결정 방법은 시행-착오 방법을 거치지 않는다는 점과 분석자의 주관을 최대한 배제하고 여러 자료군에 동일한 기준을 적용할 수 있다는 장점들이 있으나, 낮은 임계 계수는 많은 군집의 수를, 높은 임계 계수는 적은 군집의 수를 지정하므로써, 군집의 수 자체를 임의로 결정하는 방법과 본질적인 차별성을 확보하기 어려운 단점이 있다. 특히, 밀집도가 차이가 나는 군집들로 구성된 자료군에서 낮은 밀도의 잠재 군집을 높은 임계 계수로 감지하기 어려우며, 반대로 낮은 임계 계수를 사용하면 군집의 수가 지나치게 많아질 우려가 있어 밀집도가 군집 내에서 높은 하위-최적화(sub-optimal)가 발생할 우려가 크다. 따라서, 본 연구에서는 상대적으로 낮은 밀집도의 잠재 군집을 감지하면서도, 자료군의 특성에 비해 많은 군집의 수가 지정되는 것을 방지하기 위하여 허용 거리(allowable distance) 개념을 도입하였다. 이 방법은 첨둣값으로 판명된 위치들 간의 거리가 특정 거리 미만이면 두 첨둣값 중 밀도가 높은 첨둣값만 군집의 수에 포함시키고 낮은 첨둣값을 가진 위치는 버리는 방법이며, 이 특정 거리를 허용 거리로 부르고, da 로 표기한다. 허용 거리는 단위 반구 표면 상의 거리이므로 각돗값을 사용한다.
Table 4는 임계 계수와 허용 거리를 적용한 밀도 첨둣값 사용 방법으로 결정된 자료군들의 군집의 수가 정리되어 있다. 임계 계수가 1.25와 1.75 두 가지 경우에 대해서 허용 거리를 0, 30, 35, 40까지 변화시켜 추정한 결과(da = 0인 경우는 허용 거리를 적용하지 않은 것과 동일하다.), 임계 계수 1.25, 허용 거리 35를 적용한 결과가 육안 판별 결과와 가장 유사하게 군집의 수를 추정한다(Table 3 참조). 임계 계수 1.75를 적용한 결과들은 다소 높은 임계 계수로 다수의 첨둣값 위치들이 기각되어, 허용 거리 적용에 따른 군집의 수 조정 효과가 크게 나타나지 않았다. 따라서, 본 연구에서 제안하는 밀도 첨둣값을 이용한 군집의 수 추정 방법을 사용하는 전략은 낮은 임계 계수를 허용 거리와 함께 사용하는 것이다.
군집의 수 결정 문제는 자료군의 특성에 좌우되지만, 자료군 특성에 맞는 정답이 존재하는 문제는 아니다. 분석자의 주관을 배제하기 위한 첨둣값 사용 방법 역시 임계 계수와 허용 거리를 결정해야하는 선택의 문제가 존재하며, 임계 계수 역시 일종의 초매개변수인 셈이다. 다만, 이 방법을 적용한 다양한 사례들의 결과가 축적이 되면 객관적 선택의 지표를 발견할 수 있는 가능성의 여지는 있다.
Table 4.
Number of clusters estimated by peaks of densities applying thresholds and allowable distances
5.3.2 초기 중심
K-평균 방법은 초기 중심값(initial centroid)을 잘못 선정하면 하위-최적화된 해를 얻게 될 수 있으며, 군집들의 크기가 다양하거나, 군집들의 밀도가 다른 경우 잘 작동하지 않을 수 있다(Géron, 2019). 반구 상의 방향성 자료의 군집들은 크기가 다양하고, 밀집도도 서로 다른 경우가 많다. 따라서, 적절한 군집의 수로 군집화를 시행하더라도 무작위로 할당되는 초기 중심들을 사용하면 하위-최적화의 결과를 얻게될 가능성이 있다.
Fig. 9는 B1 자료군을 대상으로 무작위로 초기 중심값을 할당하여 K-평균과 피셔혼합모델 알고리즘으로 자동 군집화를 시행한 결과를 보여 준다. 난수 생성 알고리즘의 씨앗값(seed)을 변경하여 두 가지 다른 경우의 초기 중심값들(Case I, Case II)을 적용하였으며, 원 모양의 궤적이 각 초기 중심값이 군집의 중심을 찾아가는 계산 과정을 나타낸다. Case I은 K-평균과 피셔혼합모델 모두 밀도 등고선도에 나타난 세 개의 밀도 중심을 군집의 중심으로 제시하는 결과를 보이고 있으나(Fig. 9(a), 9(c)), Case II의 경우(Fig. 9(b), 9(d))는 반대로 표본의 수가 많이 몰려 있는 곳의 하위-최적화가 발생한 결과를 나타내고 있음을 알 수 있다. 이 결과는같은 자료에 대하여, 같은 군집화 알고리즘을 적용하더라도, 초기 중심의 위치에 따라 군집화의 결과가 달라질 수 있다는 점을 보여 준다. 따라서, 타당한 군집화 결과를 얻기 위해서는 결정된 군집의 수에 맞는 군집의 초기 중심들을 적절하게 설정해야 한다.
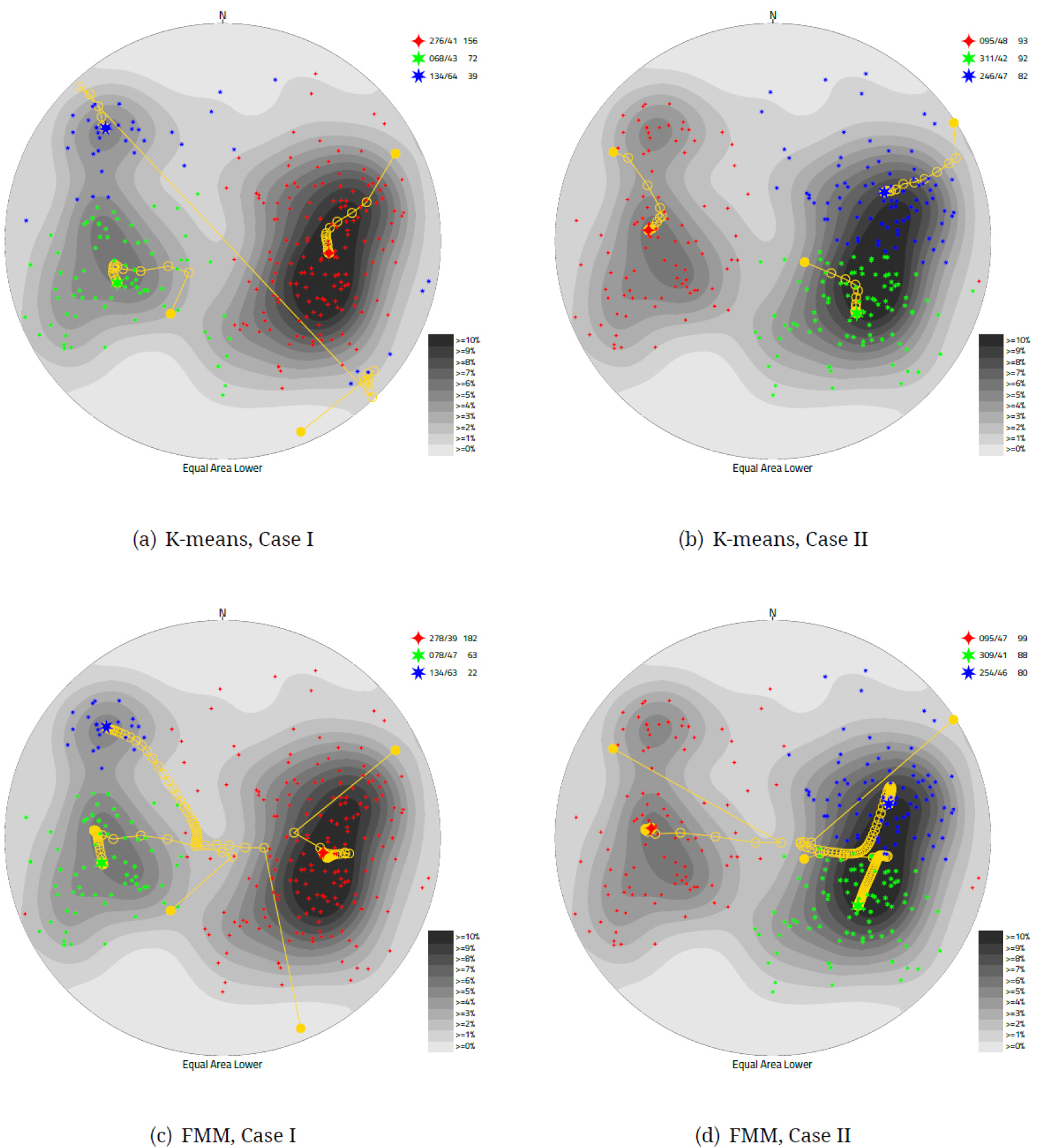
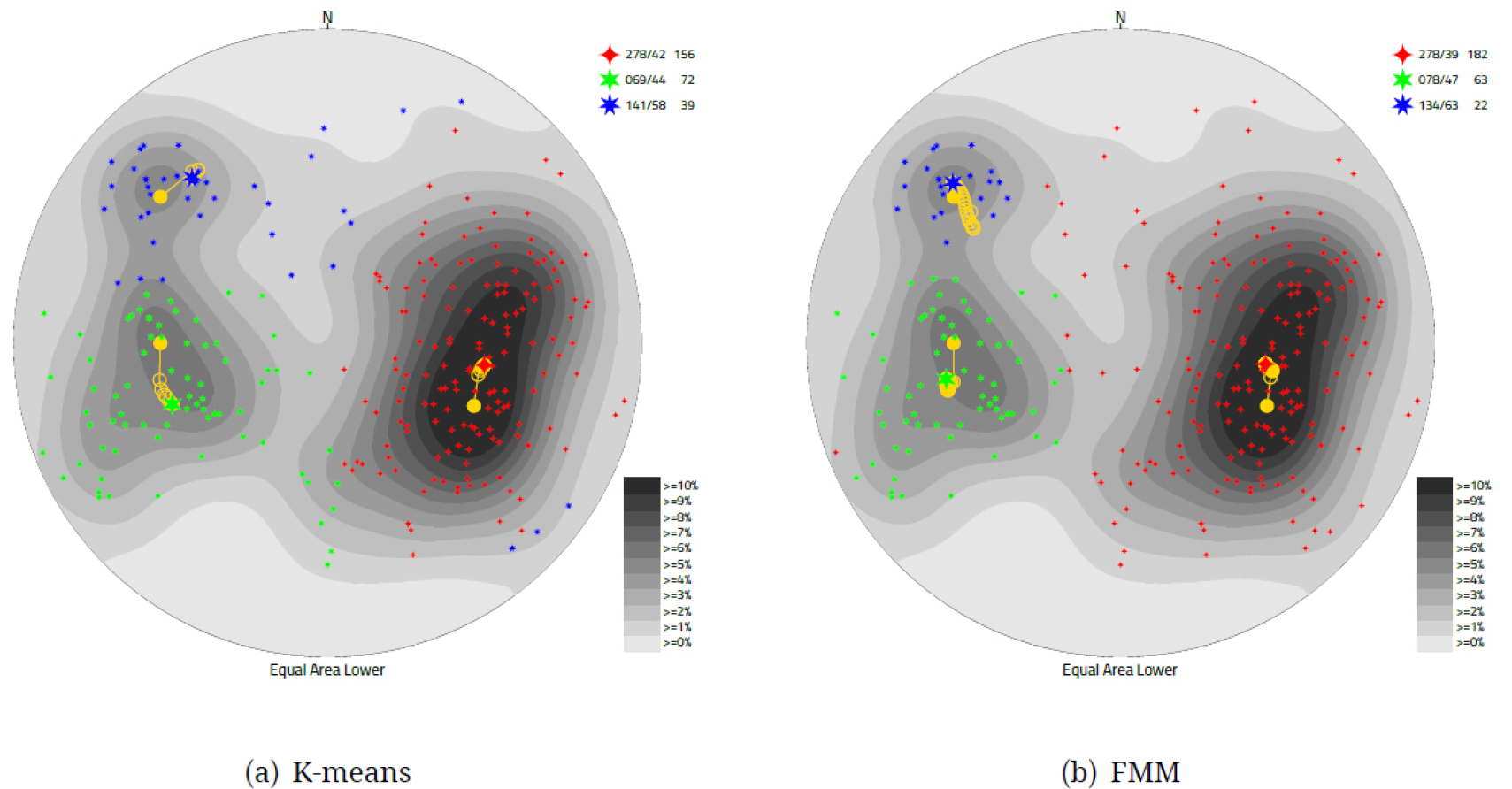
본 연구에서는 군집의 수를 결정하기 위하여 사용한 밀도 격자망의 밀도 첨둣값 위치를 초기 중심으로 설정하는 방법을 사용하였다. 그 결과는 Fig. 10에 나와 있으며, K-평균 알고리즘을 사용한 경우(Fig. 10(a))와 피셔혼합모델을 사용한 경우(Fig. 10(b))모두 최종 중심에 인접한 초기 중심을 설정하였으며, 하위-최적화의 발생없이, 밀도와 크기 차이가 있는 세 개의 군집을 잘 찾아낸 결과를 보여주고 있다.
5.3.3 군집화 알고리즘의 비교
본 연구에서 구현한 군집 자동화 알고리즘은 K-평균(4.1절)과 피셔혼합모델(4.2절)이다. 12개의 표본 자료를 활용하여 이 두 가지 군집화 알고리즘을 적용한 결과를 비교하였다. Table 5는 임계 계수 1.25, 허용 거리 35(B6 자료군의 경우, 45)를 적용한 밀도 첨둣값의 위치들을 이용하여 각 자료군의 군집의 수와 군집들의 초기 중심을 설정하여 군집화를 수행한 결과이다. K-평균과 피셔혼합모델의 군집화 결과는 각 군집의 중심값과 각 군집에 속하는 표본의 수에서 차이가 나는 것을 확인할 수 있다. 예외인 경우도 있으나, 대체적으로, K-평균의 결과 보다 피셔혼합모델의 결과에서 각 군집 간의 크기의 차이가 좀 더 크게 나는 경향을 볼 수 있다. 즉, 최대 군집과 최소 군집의 크기 차이가 더 크게 나타난다. 각 군집의 중심은 약간의 차이가 있으나, 이는 군집의 크기 차이와 군집 중심을 계산하는 방법의 차이에서 기인하는 것이다.
Table 5.
Clustering results from K-means and Fisher mixture model algorithms
| Data set |
Number of clusters* | K-means | Fisher Mixture Model | |||
| Centroids | No. samples | Centroids | No. samples | Fisher const., 𝜅 | ||
| B1 | 3 | 278/42 | 156 | 278/39 | 182 | 6.0392 |
| 069/44 | 72 | 078/47 | 63 | 12.9607 | ||
| 141/58 | 39 | 278/39 | 22 | 57.5107 | ||
| B2 | 3 | 292/44 | 142 | 292/43 | 154 | 7.7927 |
| 171/57 | 103 | 166/55 | 107 | 8.2174 | ||
| 088/35 | 35 | 083/40 | 40 | 25.9483 | ||
| B3 | 3 | 041/44 | 250 | 037/42 | 268 | 8.8873 |
| 198/44 | 214 | 198/44 | 212 | 10.3681 | ||
| 317/48 | 135 | 315/49 | 119 | 7.1147 | ||
| B4 | 2 | 082/41 | 115 | 082/40 | 116 | 8.6431 |
| 255/41 | 101 | 255/41 | 100 | 11.8612 | ||
| B5 | 3 | 091/41 | 104 | 089/41 | 102 | 12.2961 |
| 235/53 | 61 | 237/50 | 74 | 7.1334 | ||
| 325/51 | 48 | 331/53 | 37 | 16.9078 | ||
| B6 | 2** | 102/48 | 156 | 103/44 | 167 | 5.7572 |
| 259/41 | 140 | 260/44 | 129 | 11.4094 | ||
| B7 | 2 | 111/44 | 220 | 109/46 | 202 | 11.5315 |
| 273/38 | 81 | 260/31 | 99 | 4.4679 | ||
| B8 | 2 | 056/38 | 209 | 054/39 | 199 | 11.7550 |
| 239/43 | 90 | 235/37 | 100 | 5.1908 | ||
| B9 | 2 | 234/47 | 130 | 046/53 | 127 | 4.2408 |
| 053/51 | 118 | 233/48 | 121 | 7.1168 | ||
| B10 | 1 | 136/31 | 242 | 146/26 | 242 | 3.2958 |
| B11 | 1 | 103/53 | 112 | 086/48 | 112 | 3.0195 |
| B12 | 3 | 227/19 | 150 | 209/18 | 190 | 5.5338 |
| 093/59 | 74 | 097/68 | 59 | 7.5104 | ||
| 164/83 | 50 | 160/90 | 25 | 30.8409 | ||
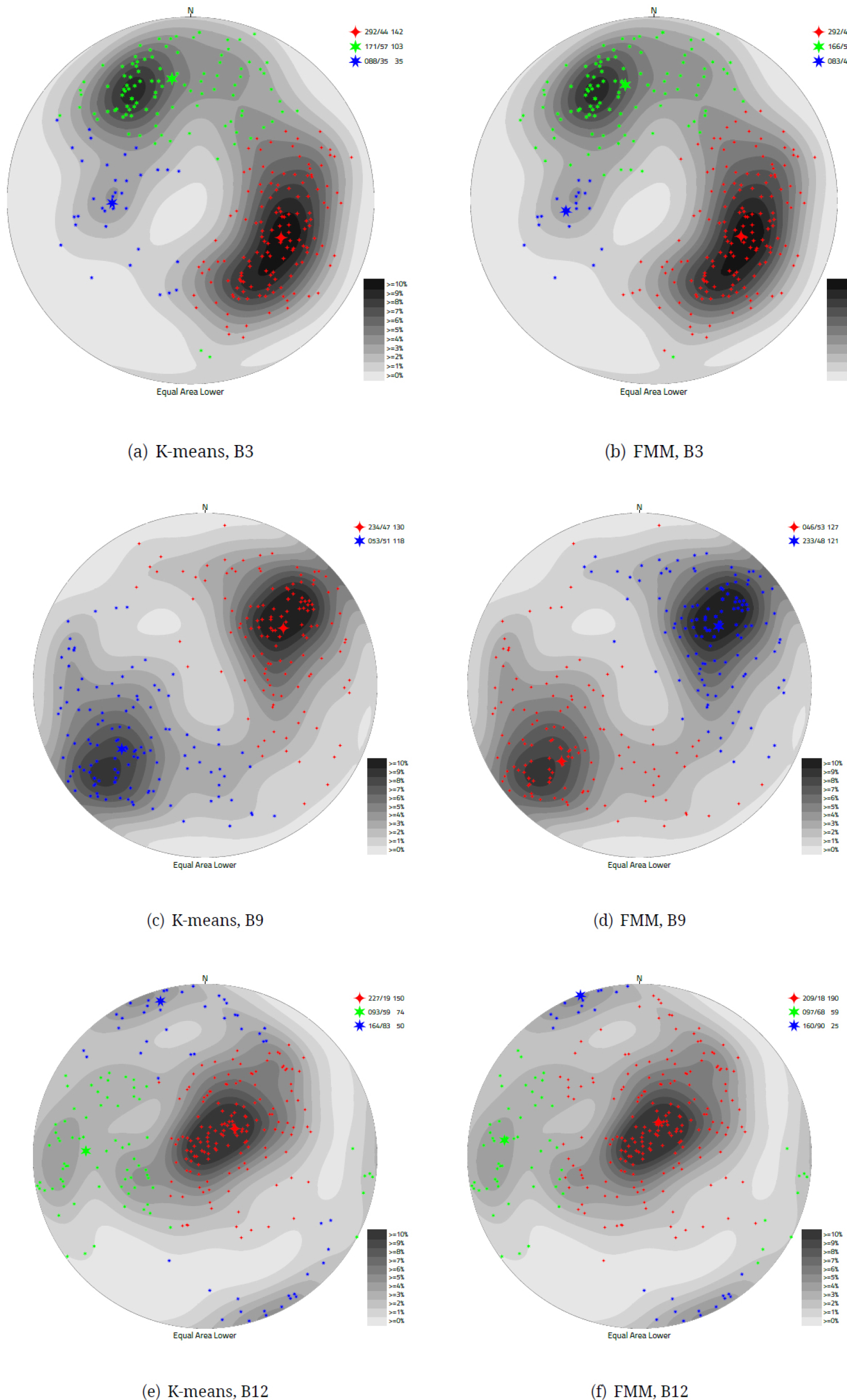
Fig. 11에 K-평균과 피셔혼합모델의 비교를 위하여 몇 가지 대표적 군집화 결과를 나타내었다. B3 자료군은 균열 방향성 표본 수가 가장 많은 자료군으로 밀도 첨둣값 방법에서 제시된 군집의 수는 3개이다. 반구 투영도에 나타난 밀도 분포는 두 개의 큰 집단 균열군이 대칭을 이루고 있으며, 표본의 크기가 작은 균열군을 나타내고 있으며, 자동 군집화 시행 결과 두 가지 방법의 결과, 각 균열군 중심의 위치는 큰 차이를 보이지 않았다(Fig. 11(a), 11(b)). 다만, K-평균 방법 보다 피셔혼합모델의 결과에서 큰 군집으로의 표본들의 쏠림 현상이 강하게 일어난 것을 알 수 있다. 즉, K-평균 방법의 결과에서는 가장 작은 크기의 균열군에 속했던 표본들이 큰 크기의 두 균열군에 속하는 것을 확인할 수 있다. B9 자료군의 경우 밀도 분포가 거의 명확하게 2개의 균열군을 나타내고 있으며, 자동 군집화 결과 역시 2개의 균열군으로 군집화가 이루어진 것을 볼 수 있다(Fig. 11(c), 11(d)). B9 자료군 역시 두 방법에서 각 균열군의 중심은 큰 차이가 없었으나, 균열군에 포함된 표본의 크기가 역전되어 나타난 결과를 보여주고 있다. 마지막으로, B12 자료군은 수평 균열들이 큰 집단을 이루고 있으며, 표본의 크기가 작은 경사 균열들과 수직 균열들이 분포하고 있음을 알 수 있다(Fig. 11(e), 11(f)). 이 자료군은 임계 계수를 높게 설정하면 표본의 크기 차이 때문에 하나의 균열군만 제시되는 결과를 나타낼 수 있다(Table 4 참조). 3개의 균열군으로 군집화된 결과, 다른 자료군과 비교할 때, 두 가지 방법에서 계산한 각 균열군의 중심의 위치가 차이가 다소 크게 나타난 것을 볼 수 있다. 이 자료군에 포함된 수직 균열군은 서로 대척점에 위치한 균열들을 동일한 군집으로 분류된 것을 확인할 수 있다.
이 결과들로부터 두 가지 방법의 군집화의 결과는 큰 틀에서는 차이가 없다고 판단할 수 있다. 다만, 자료군의 특성에 따라, 각 균열군의 중심의 위치는 각 방법에서 제시하는 값이 차이가 날 수 있음을 보았다. 특히, 각 자료군에 속한 표본의 크기가 많이 차이가 나는 경우, 결과의 차이가 좀 더 두드러질 수 있음이 확인된다. 균열 자료의 군집화는 정해진 답을 찾아가는 과정이 아니므로, 각 군집화 방법의 추론에 따라 다른 결과가 나타나는 것은 자연스러운 현상이다. 따라서, 군집화 방법의 특성을 이해한 바탕에서 군집화 방법을 선택하고, 그 결과를 해석해야 할 것이다. 본 연구를 통해 구현된 두 가지 군집화 알고리즘은 초기값 설정 방법을 사용하여 초기값 설정을 위한 비용과 주관적 요소를 배제하였으며, 군집화 결과 차이는 미미하게 나타났다. 다만, 확률분포함수를 기반으로 한 피셔혼합모델의 경우, 표본의 크기 차이가 큰 자료군의 군집화와 군집화 결과를 개별균열망(DFN) 생성 등에 활용하는데에 좀 더 유리하다는 장점이 있다고 볼 수 있다.
6. 결 론
본 연구에서는 암반의 특성과 거동에 지대한 영향을 미치는 암반 균열의 방향성을 합리적이고, 효율적으로 분석하기 위하여 균열 방향성 밀도 분석 및 시각화 방법과 자동 군집화 알고리즘의 초기 매개변수의 설정 방법에 대하여 연구하였으며, 그 결과 군집의 수 결정 문제와 초기 중심 설정 문제에 합리적 대안을 제시하였다. 또한, 측정한 균열 방향성들이 여러 개의 피셔 분포를 이루고 있다는 가정에 기반한 피셔혼합모델 균열 방향성 자동 군집화 알고리즘을 개발하였다. 본 연구를 통하여 제시된 방법론과 알고리즘들은 균열군 분석과 시각화의 기능을 수행하는 전산 프로그램 알네트를 통하여 구현되었으며, 이 프로그램을 실제 시추공 영상에서 얻어진 균열 방향성 자료에 적용하여, 이 방법론과 알고리즘들의 적용성 및 타당성을 검증하였다. 이상 본 연구 핵심 성과의 의미를 요약하면 다음과 같다.
- 첫째, 피셔 확률분포에 기반한 피셔혼합모델 방향성 군집화 알고리즘을 개발하므로써 확률분포에 기반한 균열 방향성 군집화 결과의 응용이 가능하도록 하였다.
- 둘째, 군집의 수와 초기 군집 중심들을 결정하기 위하여, 방향성 밀도 첨둣값 위치를 이용하고, 임계 계수와 허용 거리를 도입하여 적절한 밀도 첨둣값 위치들을 초기 군집 중심 위치들로 할당하므로써, 하위-최적화를 방지하고 군집화 결과의 안정성과 신뢰도를 제고하는 동시에 이러한 초매개 변수들의 설정에 주관을 최대한 배제할 수 있는 안내 지침을 제공하였다.
향후 과제로 더 많은 현장 자료의 적용을 통한 추가적인 검증과 보완 및 연구 성과를 암반 균열의 영향 및 역할을 반영하기 위한 개별 균열망 등 응용 분야에 적용하는 방안에 대한 연구도 필요하다.
