

1. 서 론
2. 딥러닝 기반의 컴퓨터 비전 프로세스
2.1 컴퓨터 비전 프로세스
2.2 앵커 박스
3. 실험 방법
3.1 실험 데이터 현황
3.2 학습 데이터 분할 기준
3.3 통합 데이터셋 및 분할 학습 데이터셋 추론 결과 비교
3.4 소결
4. 결 론
1. 서 론
건설 현장의 사고사망자 비율이 전체 산업에서 가장 높은 비율을 차지하고 있다(Ministry of Government Legislation, 2023). 이러한 현안에 대응하기 위해 정부는 법 제도를 개정하거나 다양한 스마트 건설 솔루션을 도입하고 있다. 또한 최근에는 딥러닝 기반의 컴퓨터비전 기술을 안전관리 목적으로 건설 현장과 연계하여 안전성 향상을 위한 많은 연구가 수행되고 있다. 컴퓨터비전 기술은 크게 객체 인식(Object Detection)과 영역 분할(Instance Segmentation)로 구분된다(Zhao et al., 2019, Minaee et al., 2021). 객체 인식은 입력 영상 내 존재하는 대상 객체를 경계 상자(Bounding Box) 형태로 검출하는 기술이고, 영역 분할의 경우에는 대상 객체의 형상에 맞춰 영역을 구획하는 기술이다. 영상 내 객체를 감지하기 위해서는 학습 과정에서 사용되는 앵커 박스(Anchor Box) 파라미터가 중요하다. 앵커 박스는 경계 상자의 초기 위치를 추측하기 위한 파라미터로 너비와 높이의 비율로 크기를 제공한다(Lin et al., 2017). 앵커 박스는 영상 내 존재하는 많은 수의 객체 종류와 크기에 따라 민감하게 작동하여 검출 정확도에 매우 큰 영향을 준다. 이러한 앵커 박스 파라미터는 대부분 학습 과정에서 작업자의 경험적인 휴리스틱 방법으로 파라미터의 변수를 설정하게 된다(Zhong et al., 2020). 앵커 변수가 결정되면 훈련 중에 크기가 고정되므로, 앵커 파라미터를 잘못 설계하면 특정 영역에서 성능이 감소하는 결과를 초래할 수 있다. 다음 Fig. 1은 사전 연구로 공사현장에 설치한 CCTV 영상 정보를 활용하여 건설 현장에 고정된 앵커 변수를 학습하고 추론했을 때 발생한 한계점을 보여준다.

Fig. 1의 좌측은 학습을 위해 생성한 라벨링 영상이며, 우측은 해당 데이터에 영역 분할 기법을 적용하여 추론한 결과다. 라벨링 이미지에는 다양한 객체 종류와 크기가 존재하는데 고정된 앵커 변수로는 모든 객체의 특성을 고른 가중치로 학습하는데 한계가 있어 우측 그림과 같이 작은 객체의 경우 미탐지되는 현상이 빈번하게 발생한다. 이러한 소형 크기의 객체를 검출하기 위해 앵커 파라미터를 작은 객체 위주로 변경한다면 다른 객체들이 검출 정확도에 부정적인 영향을 미치는 Trade-off 현상에 직면하게 된다.
본 연구에서는 고정된 앵커 변수로 학습 결과에 따른 추론 성능의 한계를 극복하기 위한 분할 학습 기법을 제안한다. 실험에 사용된 영상 데이터는 한국건설기술연구원에서 섭외한 택지개발 공사현장에서 구축한 CCTV 기반 영상 수집 시스템의 1년 기간의 현장 영상 데이터를 활용하였다(Na et al., 2023). 일반적인 객체 인식 기술을 전체 데이터로 통합하여 학습을 수행하지만, 본 연구에서는 데이터의 특성을 분석하여 데이터 분할 기준을 정립하고 데이터 분할을 수행하였다. 그리고 단일 모델과 분할 모델의 학습을 독립적으로 수행하고 추론 결과를 비교하여 분할 학습의 효과를 정량적으로 분석하였다. 다음 장에서는 컴퓨터 비전 기술의 배경적 이론을 제공하며, 3장에서는 학습 데이터의 현황, 데이터 분할의 기준 그리고 실험 결과와 분석을 제공하고 4장에서는 본 논문의 결론을 제시한다.
2. 딥러닝 기반의 컴퓨터 비전 프로세스
2.1 컴퓨터 비전 프로세스
객체인식이나 영역분할 모델은 일반적으로 합성곱 신경망(Convolution Neural Network, CNN)을 이용하여 영상 분석을 수행한다. Fig. 2는 영역 분할의 대표적인 모델인 Mask R-CNN 모델 구조를 보여준다(He et al., 2017). 영역 분할 모델은 입력 영상으로부터 CNN를 사용하여 특징맵을 추출한다. 특징맵 정보를 기반으로 객체 검출과 영역 분할을 위해 두 단계 프로세스를 수행한다. 첫 번째 단계로 앵커 박스 파라미터 기반의 Localization 단계를 수행하여 특징맵에서 객체가 존재할 만한 후보 영역을 검출한다(Girshick, 2015). 다음 단계는 객체가 존재할 확률이 높은 영역의 특징맵을 크롭(crop)하고 후보 영역들에 대해 해당 객체의 클래스와 위치를 판단하고 추가로 영역화를 수행하는 프로세스이다.
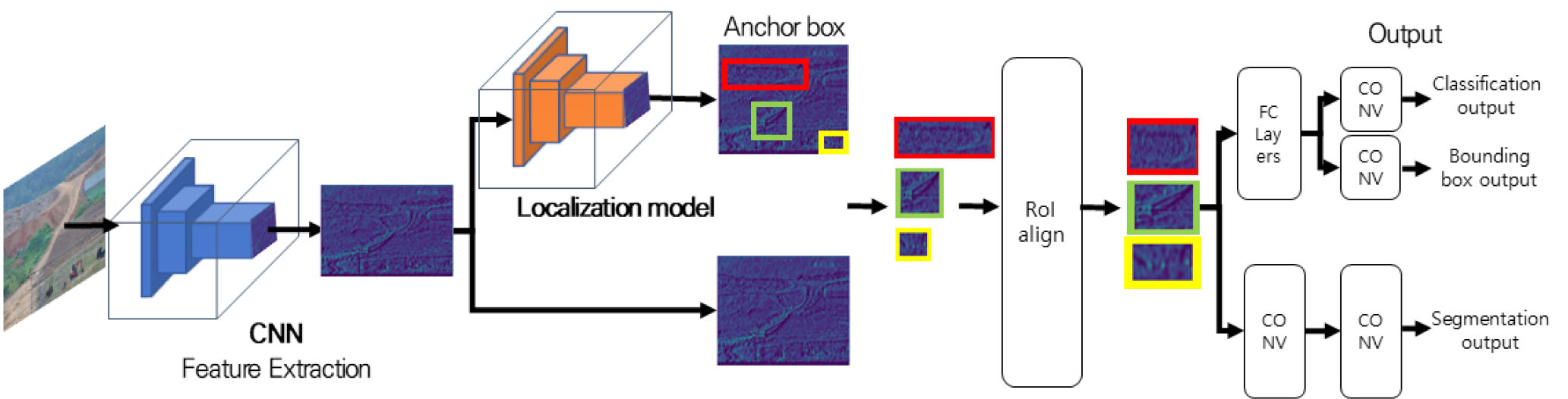
2.2 앵커 박스
영역 분할 모델에서 Localization 단계를 수행할 때 앵커박스와 종횡비(Aspect ratio)의 개념이 적용된다(Redmon and Farhadi, 2017). 딥러닝 기반의 객체 검출을 효율적으로 수행하기 위해 객체의 위치 값을 직접 예측하지 않고 앵커 박스를 초기 값으로 활용하여 객체가 위치할 후보군을 예측한다. 고정된 크기의 경계 상자를 사용할 때 다양한 크기의 객체를 검출하지 못하는 한계가 있다. 따라서 Fig. 3처럼 사전에 정의한 서로 다른 크기(scale)와 종횡비를 갖는 앵커 박스를 적용하여 크기가 다른 객체를 검출하는데 용이하도록 구성한다. 앵커박스의 비율은 종횡비(1:1, 1:2, 2:1)를 고정해서 이용하며 크기의 경우 이미지 해상도에 비례하여 적용하게 된다(Lempitsky et al., 2009). 예를 들어 학습 이미지의 해상도가 1024×1024인 경우 종횡비를 반영하여 최대 512 앵커 크기를 사용하게 된다.
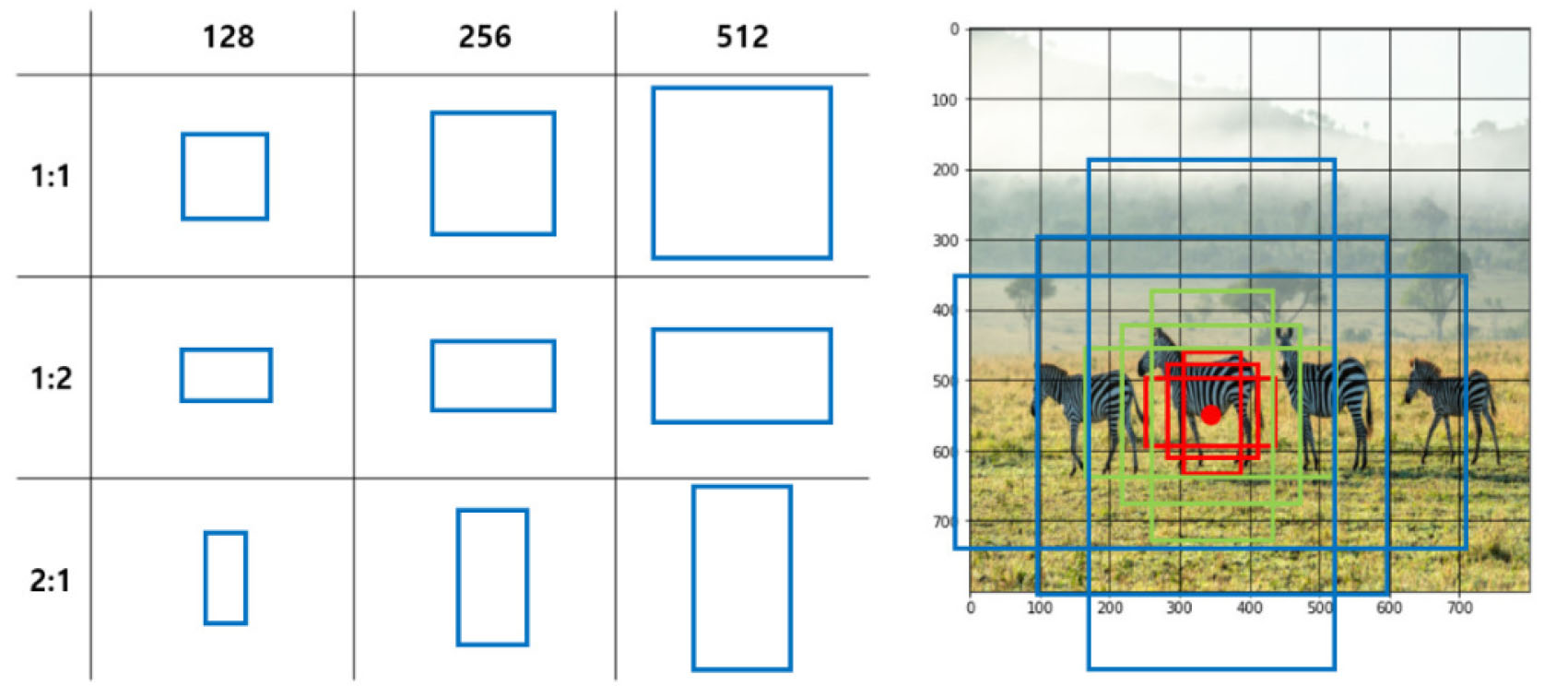
하지만, 종횡비와 스케일을 통해 다수 앵커 박스 적용으로 영상 내 객체들의 검출력을 높이는데 한층 보완되었지만 Fig. 1처럼 영상 내 수많은 객체와 다양한 크기의 객체가 동시에 존재하면 단일 파라미터로 모든 객체의 범위에 대응하기에는 한계점이 있다. 예를 들어 앵커 박스의 모양을 3가지 스케일()와 3가지 종횡비(1:1, 1:2, 2:1)를 갖도록 설계되는데 이런 경우 영상 내 9가지 앵커 박스의 경우의 수를 포함하여 매우 큰 객체나 매우 작은 객체를 검출하는 데 어려움을 겪는 것이다.
3. 실험 방법
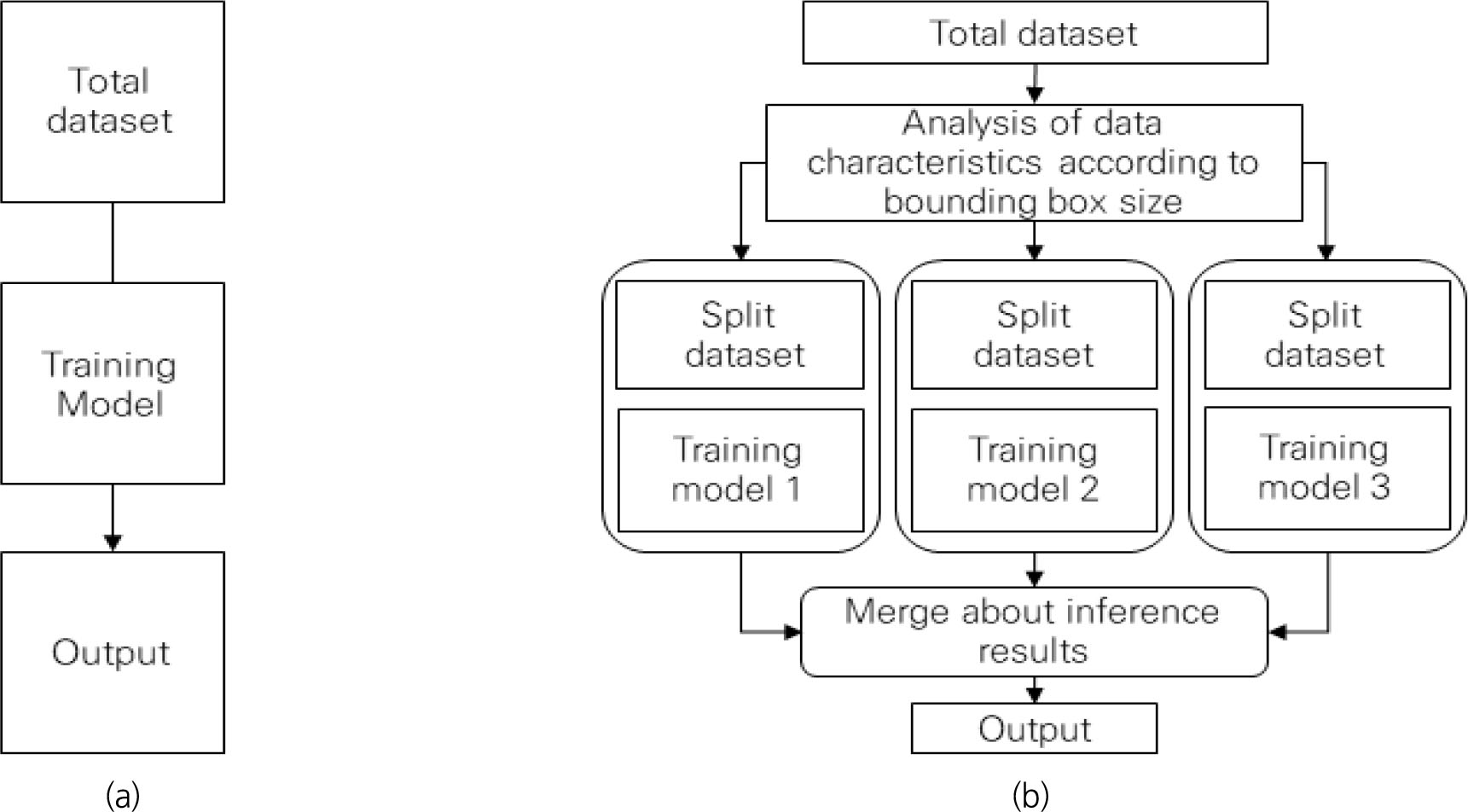
다음 Fig. 4는 통합 학습과 분할 학습의 프로세스를 보여준다. 통합 학습은 일반적으로 인공지능에서 적용하는 프로세스이며 전체 데이터셋에 파라미터를 부여하여 학습을 수행한다. 하지만 학습 데이터의 규모가 커지면, 일반적인 단일 파라미터 방법은 모든 특성을 반영하기에는 한계가 있어 최적의 학습모델을 생성하는데 어려움이 발생한다. 따라서 본 연구에서는 분할 학습을 통해 전체 데이터로부터 특성을 분석하여 그룹화하고 분할하여 모듈별 최적화 학습을 수행하는 프로세스를 제안한다. 먼저 데이터 분할의 가설을 설정하여 학습 데이터 분할을 수행하고 최종적으로 통합 학습과 분할 학습의 검출 성능 비교를 통해 분할 학습의 효과를 검증한다.
3.1 실험 데이터 현황
실험에 사용된 데이터는 한국건설기술연구원에서 섭외한 토목 공사현장 대상으로 영상 수집 시스템을 구축하여 가공한 영상 데이터를 사용하였다(Na et al., 2023). 다음 Fig. 5는 섭외 현장의 전체 도면을 나타내며 영상 수집 장비의 설치 위치와 영상 취득을 위한 주요한 위치를 나타낸다. 영상 수집 장비는 20 m 높이의 야적장 상부에 설치하였으며, Fig. 6처럼 공사가 활발하게 수행되는 주요한 8개 지점을 선정하여 데이터 취득 계획을 수립하였다. 영상 취득은 1년 기간 동안 수행하였으며 영상 수집 장비의 Pan, Tilt, Zoom (PTZ) 기능을 이용하여 30초 단위로 지점 1에서 지점 8까지 반복적으로 자동 취득하도록 시스템을 설계하였다.
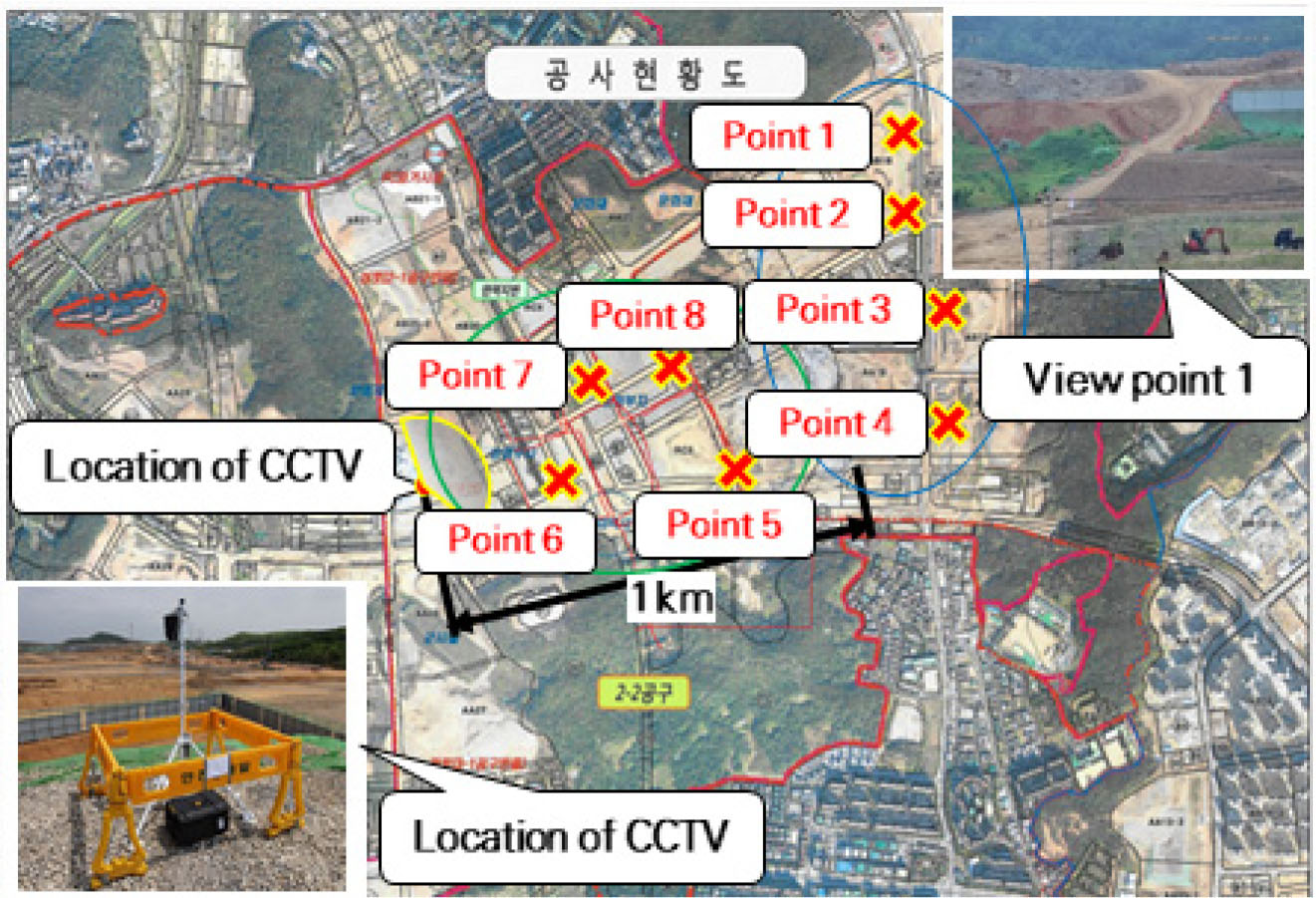

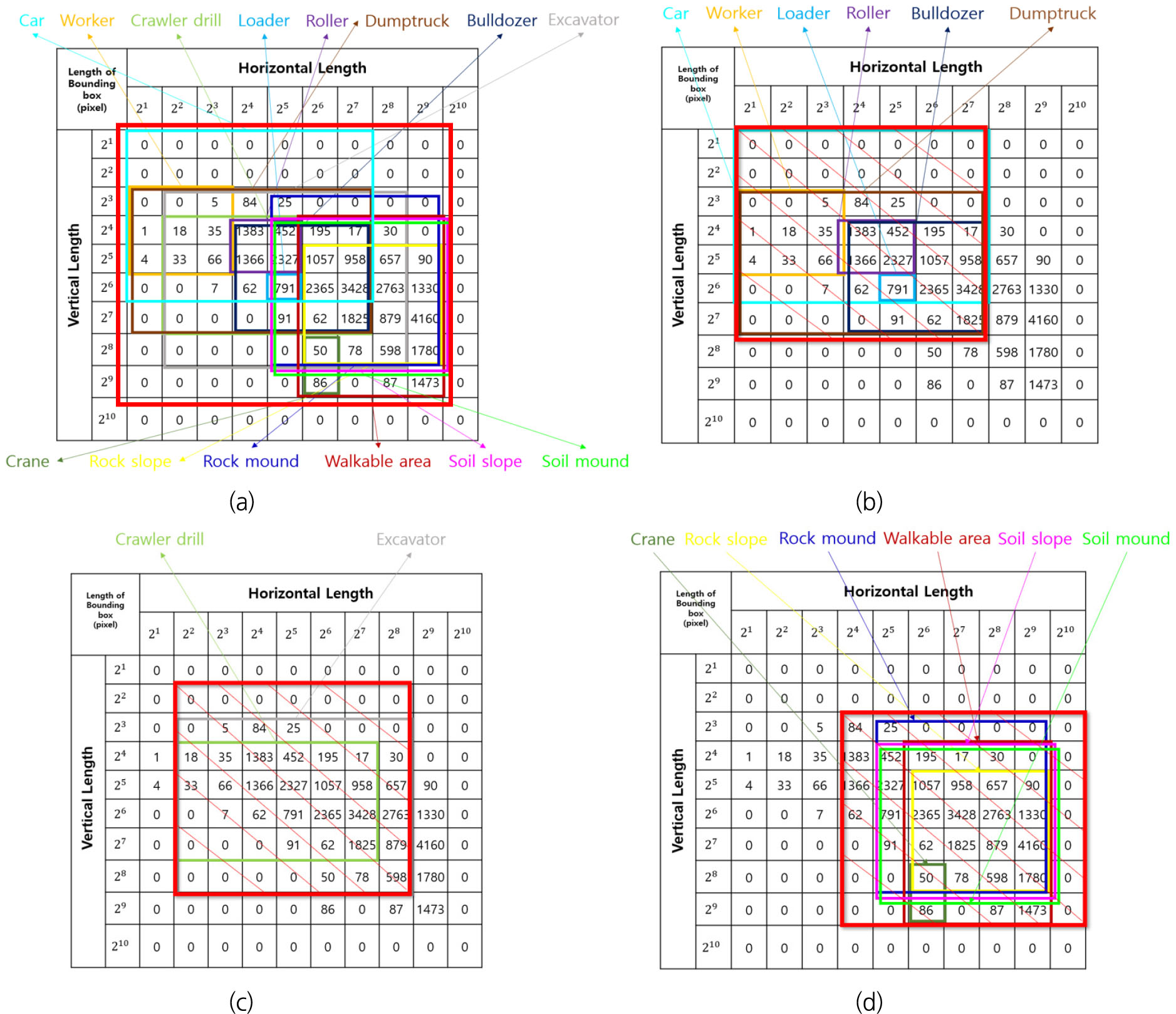
Fig. 6처럼 대표적인 화각 8개 대상으로 1년간의 영상 데이터로 다양한 배경 조건, 조도 조건, 기간을 고려하여 영상을 샘플링하였다. 토목 현장에서 주로 발생하는 관련 공사 종류에 따라 총 17개의 객체를 선정하였으며, 최종적으로 데이터를 가공하여 학습 데이터를 생산하였다. 최종 학습 데이터에 사용된 정지 영상의 수는 7,560장으로 구성되며, Table 1은 학습 데이터의 객체 종류에 따른 현황을 보여준다. 또한, 객체 특성을 분석하여 객체 수가 많은 소형 크기, 객체 수가 적은 소형 크기, 중형 크기, 대형 크기 객체 데이터셋 그리고 통합 데이터셋으로 5 종류의 데이터셋을 구분하였다. 데이터셋 구분 기준은 다음 절에서 자세히 설명하도록 한다.
Table 1.
Dataset structure
3.2 학습 데이터 분할 기준
본 연구의 주요 목표는 통합 데이터셋을 학습하는 것이 아닌 데이터를 분할하고 분할된 데이터셋에 최적화된 학습 파라미터를 모델마다 제공하는 것이다. 이에 따라 학습 데이터 특성을 반영하기 위한 데이터 분할 기준 3가지를 다음과 같이 제안한다.
첫 번째로는 영상 내 유사 형상 객체는 동일한 학습 데이터셋에 포함되어야 한다. Fig. 7은 초기 소형 데이터셋과 가설을 반영하여 수정된 데이터셋의 추론 결과를 보여준다. 초기 소형 데이터셋은 자동차 객체만 포함되어 있고 수정된 소형 데이터셋은 덤프트럭과 자동차 객체를 동일 그룹으로 구성하였다. Fig. 7의 (a) 추론 결과를 보면 덤프트럭 객체를 자동차 객체로 오탐지 현상을 확인할 수 있다. 반면에 Fig. 7의 (b)를 보면 덤프트럭 객체와 자동차 객체를 동일 그룹에 포함하여 학습을 수행하고 추론한 결과 초기 소형 데이터셋과 다르게 덤프트럭과 자동차를 정탐지하는 결과를 확인할 수 있다. 이러한 오탐지가 발생하는 이유는 자동차 전면부와 덤프트럭 전면부의 형상이 매우 유사하여 학습모델이 혼란을 일으키기 때문이다. 따라서 영상 내 유사한 형상을 가지는 객체는 동일 학습 데이터셋에 포함되어야 하는 실험 결과를 얻었다. Table 1을 보면 이러한 특성을 반영하여 자동차와 덤프트럭을 같은 그룹에 속하도록 소형 데이터셋을 구분하였으며, 굴삭기와 크롤러 드릴도 동일한 이유로 중형 데이터셋으로 그룹화하였다.

두 번째로는 객체의 크기에 따른 분포도 분석을 통해 데이터 세분화를 수행해야 한다. 학습에 사용된 이미지 크기는 전처리 과정으로 1024x1024 픽셀로 재구성하였다. 일반적으로 학습 데이터 가공을 위해 라벨링 수행 시 경계 상자를 영상 내 표시하게 된다. 다음 Fig. 8은 경계 상자의 가로길이 및 세로길이에 따라 객체 수 기반으로 통계화한 결과다. Fig. 8의 (a)는 통합 데이터셋에 포함된 총 17개 객체를 색상에 따라 표시한 결과이며 표시된 사각형은 해당 객체의 전체 범위를 나타낸다. 통합 데이터셋의 모든 객체 앵커 크기를 반영하기 위해서는 적색 사각형 범위의 파라미터를 부여하여 학습을 수행해야 한다. 적색 범위는 Fig. 8의 (b), (c), (d)와 다르게 가장 큰 범위를 차지하고 있다. Fig. 8의 (b), (c), (d)는 객체 크기에 따라 소형 크기 데이터셋, 중형 크기 데이터셋, 대형 크기 데이터셋으로 구분하기 위해 앵커 파라미터의 범위를 설정한 결과를 보여준다. 통합 데이터셋과는 다르게 적색 사각형의 범위는 축소되었으며 이것은 객체 크기의 범위에 맞게 파라미터를 최적화한 의미로 해석할 수 있다.
세 번째로는 학습 데이터에 포함된 객체 수를 고려해야 한다. Table 1의 자동차와 덤프트럭의 객체 수는 1,000개 단위 이상이지만 작업자, 롤러, 불도저, 로더의 경우는 100개 미만으로 구성되어 있다. 딥러닝 기반의 컴퓨터 비전 기술은 모델 학습 시 일정 주기마다 가중치 업데이트를 수행하는데 객체의 수가 차이가 나면 업데이트 빈도수 차이로 인해 학습이 원활하게 진행되지 않는다. 이러한 현상은 불균형 데이터에 따른 치중 학습 문제다. 따라서 이러한 문제를 해결하고자 Table 1에서 객체 수가 적은 소형 데이터셋과 일반적인 소형 데이터셋을 추가적으로 구분하였다. 총 3가지 데이터 분할 기준을 통해 통합 데이터셋을 소형 크기, 객체 수가 적은 소형 크기, 중형 크기, 대형 크기 데이터셋으로 4종류의 데이터셋을 구분하였고 통합 데이터셋을 포함하여 총 5종류의 학습 데이터를 구성하였다.
3.3 통합 데이터셋 및 분할 학습 데이터셋 추론 결과 비교
앞선 데이터셋 분할 기준에 따라 분할된 5 종류의 데이터셋을 Instance Segmentation 모델을 통해 개별 학습을 수행하고 모델을 독립적으로 생산하였다. 그리고 통합 학습모델과 분할 학습모델마다 객체별 검출 정확도인 AP (Average Precision)을 계산하였다(Powers, 2010). 최종적으로 학습 데이터에 포함된 객체별 비교를 통해 분할 학습의 효과를 분석하였다.
3.3.1 통합 모델 및 소형 객체 모델 추론 결과 비교
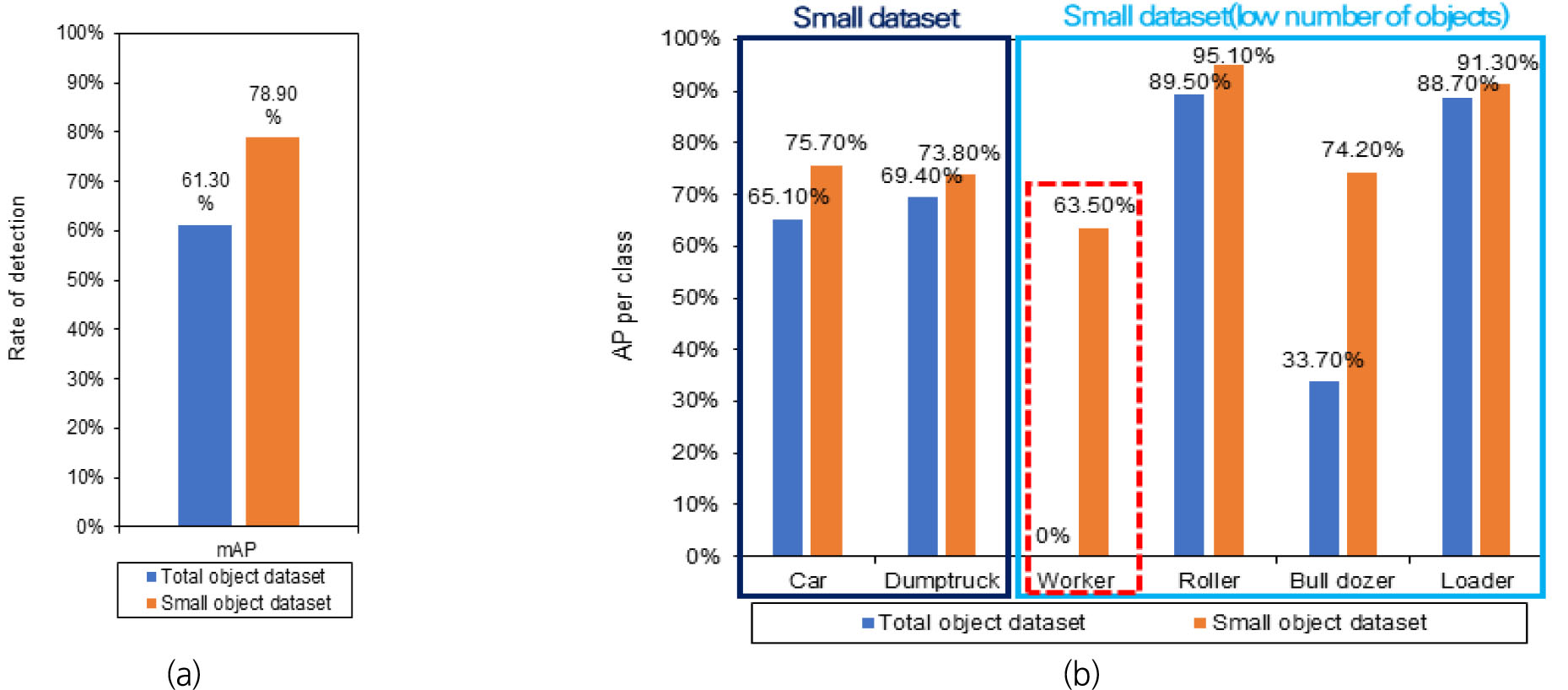
다음 Fig. 9는 통합 데이터셋과 소형 데이터셋으로 학습한 모델의 평가 결과를 보여준다. Fig. 9의 (a)를 보면 통합 모델에 비해 분할 학습 모델은 17.6% 상승된 결과가 확인 가능하다. 또한, Fig. 9의 (b)는 객체 별 AP 결과를 보여주는데 전체적으로 통합 모델에 비해 분할 모델의 성능이 높은 것이 확인 가능하다. 주요한 점은 소형 객체 중 작업자 객체의 AP 결과를 보면 통합 모델의 경우 검출하지 못한 문제를 분할 모델에서는 63.5%로 검출 성능이 대폭 상승하였다. Fig. 10은 통합 모델과 분할 모델의 추론 결과를 시각적으로 보여준다. Fig. 10의 (a)는 통합 모델로 작업자를 검출하지 못하였으나 Fig. 10의 (b)는 검출한 결과를 나타낸다.

3.3.2 통합 모델 및 중형 객체 모델 추론 결과 비교
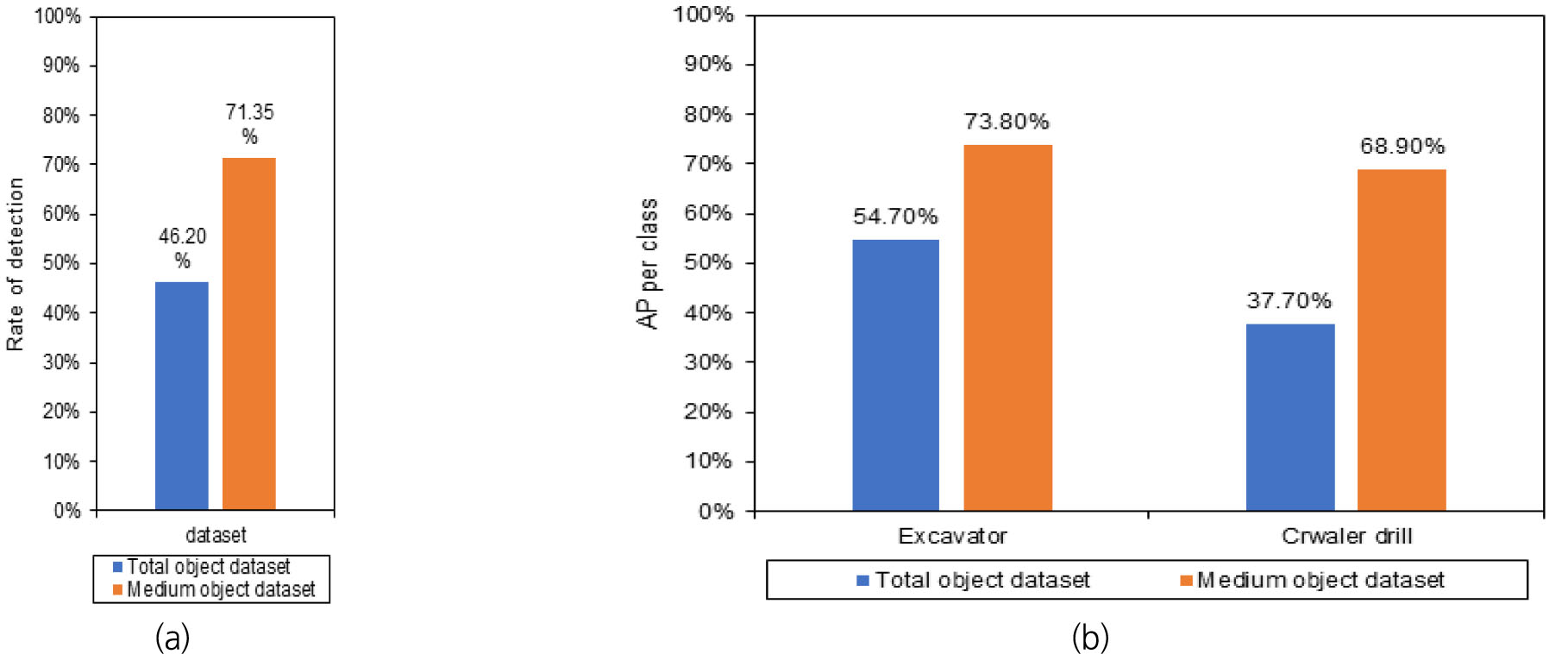
다음 Fig. 11은 통합 데이터셋과 중형 데이터셋으로 학습한 모델의 평가 결과를 보여준다. Fig. 11의 (a)를 보면 통합 모델에 비해 분할 학습 모델은 25.15% 상승된 결과가 확인 가능하다. 또한, Fig. 11의 (b)는 객체 별 AP 결과를 보여주는데 전체적으로 통합 모델에 비해 분할 모델의 성능이 높은 것이 확인 가능하다. Fig. 12는 통합 모델과 중형 객체의 추론 결과를 보여준다. Fig. 12의 (a)의 좌측 적색 표시를 보면 굴삭기를 검출하지 못하였지만 분할 모델에서는 검출한 것이 확인 가능하다. 또한, Fig. 12의 (b)를 보면 통합 모델에서는 크롤러 드릴을 굴삭기로 오검출하였으나 분할 모델에서는 크롤러 드릴로 정검출한 결과를 보였다.

3.3.3 통합 모델 및 대형 객체 모델 추론 결과 비교
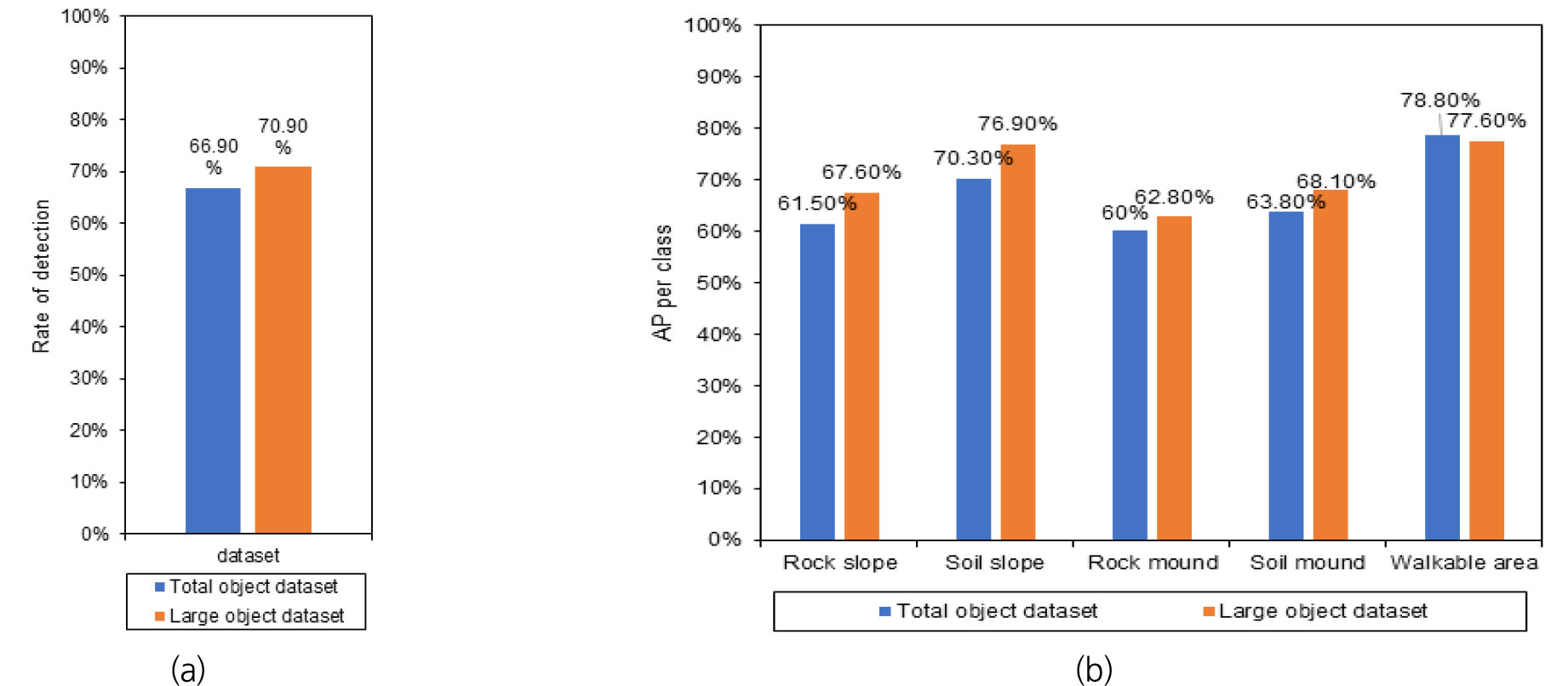
다음 Fig. 13은 통합 데이터셋과 대형 데이터셋으로 학습한 모델의 평가 결과를 보여준다. Fig. 13의 (a)를 보면 통합 모델에 비해 분할 학습모델은 4% 향상된 결과가 확인할 수 있다. 또한, Fig. 13의 (b)는 객체별 AP 결과를 보여주는 데 전체적으로 통합 모델에 비해 분할 모델의 성능이 높다. Fig. 14는 통합 모델과 중형 객체의 추론 결과를 보여준다. Fig 14의 (a)를 보면 통합 모델에서는 토사 더미를 미검출하였으나 분할 모델에서는 검출한 결과를 보인다.

3.4 소결
본 실험은 단일 모델에서 학습에 사용되는 파라미터가 모든 데이터의 특성을 반영하는데 한계가 있는 문제를 확인하고 해결 방안을 제안하기 위해 진행하였다. 컴퓨터 비전 모델은 앵커 파라미터를 대부분 사용하는데 매우 민감한 특성이 있어 파라미터를 최적화하는 것이 매우 중요하다. 객체 수와 객체 종류가 증가함에 따라 앵커 파라미터는 모든 데이터를 고르게 학습하지 못한다. 따라서 데이터를 일정 구간으로 분할하여 분할 학습을 수행하는 방안을 제안하였고 통합 학습과 분할 학습의 실험 결과를 비교하였다. 실험 결과 전체적으로 성능이 향상됨을 보였으며, 특히 소형 객체의 경우 작업자를 검출하지 못하는 문제를 분할 학습을 통해 64%나 검출하는 성능을 확인하였다. Fig. 15는 학습 데이터셋 종류(통합, 소형, 중형, 대형)에 따른 앵커 파라미터의 적용 과정을 도식화하였다. 앞서 설명한 앵커 파라미터는 앵커 박스와 스케일이 있으며 스케일에 따라 종횡비로 9종류의 앵커 박스를 영상에 적용시킨다. 앵커 박스가 적용되면 Fig 15의 (a)처럼 영상 전체로부터 객체가 존재할 만한 위치의 후보 영역들에 앵커가 발생하게 된다. 그리고 색상, 무늬, 크기, 형태를 고려하여 앵커 간 유사도를 계산한다. 유사도가 높은 앵커들의 영역을 합쳐 불필요한 앵커를 제거하거나 최적화한다. Fig 15의 (b)는 앵커 최적화 과정의 초기 결과이고 Fig 15의 (c)는 반복된 수행으로 인한 앵커 파라미터 최적화 중간 결과이다. 최종적으로 Fig. 15의 (d)와 같이 영상 내 객체를 검출하게 된다. 여기서 앵커 파라미터를 데이터 분할 기준에 따라 최적화를 수행하니, 통합 모델에 비해 객체 크기나 형상에 따라 집중적으로 객체의 후보군 검출하고 위치를 파악하기 때문에 성능이 향상된 것으로 판단된다.

4. 결 론
본 논문은 딥러닝 기반 컴퓨터 비전 모델의 학습 단계에서 일반적으로 사용하는 단일 파라미터 한계점을 보완하기 위해 분할 학습 방법을 제안한다. 분할 학습을 수행하기 위해서는 데이터 분할이 우선으로 수행되어야 하며, 데이터를 휴리스틱하게 분할하는 것이 아닌 데이터 특성을 분석하여 나누는 기준을 정립하였다. 데이터 분할의 기준은 다음과 같다.
1.학습되는 객체 종류가 다양하게 존재하는 경우 유사한 형상을 가진 객체는 같은 학습 데이터셋으로 포함되어야 한다. 학습 데이터의 객체인 덤프트럭과 자동차, 굴삭기와 크롤러 드릴은 형상이 매우 유사하여 분리하는 경우 오탐지의 비율이 높게 발생하였다. 따라서 같은 학습 데이터셋으로 구성하여 실험한 결과 오탐지 비율이 현저히 감소하는 결과를 얻었다.
2.객체 별 크기에 따른 분포도를 분석하여 크기를 고려한 데이터 세분화를 수행해야 한다. 경계 상자의 가로세로 길이에 따라 객체 수를 수치화한다. 통합 학습은 분할 학습에 비해 앵커 파라미터의 범위가 상대적으로 넓었으며 이에 따라 매우 작은 객체인 자동차 객체를 검출하지 못하였다. 하지만 분할 학습의 경우 통합 학습에 비해 크기에 따라 최적화한 파라미터를 적용하기 때문에 소형 객체에 속하는 작업자 객체를 검출하는 결과를 얻었다.
3.학습 데이터의 객체마다 객체 수를 고려하여 수행해야 한다. 일반적인 컴퓨터 비전 모델의 경우 데이터 불균형 문제에 따른 치중 학습을 고려해야 한다. 모델 학습 수행 시 가중치를 업데이트하는데 객체 수가 많은 경우 업데이트 빈도수가 높아서 적은 객체 수를 가진 객체는 학습이 미비하다. 따라서 분할학습을 수행한 결과 안정적인 추론 결과를 얻었다.
데이터 분할 기준에 따라 학습 데이터셋을 구분하고 통합 모델과 분할 모델의 객체별 검출 정확도를 비교하였다. 비교 결과 전체적으로 분할 학습의 mAP값은 15.6% 향상됨을 보였으며 실험 목적인 분할 학습의 효과를 검증하였다.
본 실험에서는 학습자의 경험적인 판단이 아닌 데이터 특성을 분석하여 데이터 분할 기준의 고려사항을 제안하였다. 그러나 모든 데이터를 자동화하기에는 한계점이 존재하며 데이터로부터 분할을 자동화하는 프로세스를 추가적으로 개발할 필요성이 있다. 현재까지 실험은 단일 모델과 분할 학습의 검출 성능 비교를 진행하였지만 학습 시간 측면에서 분할 학습은 복수개의 모델이 필요하다. 즉 모델 수만큼 시간이 요구된다. 복수개의 모델을 병렬적으로 운영이 가능하도록 시스템을 설계한다면 학습 시간에서는 동일하게 많이 소요되지만 추론 단계에서는 단일 모델과 유사하게 연산 시간을 확보하리라 판단된다. 마지막으로 분할 학습의 경우 다수의 모델을 병렬로 수행하기 때문에 병렬 모델에서 출력된 결과 값을 통합하는 중간 모듈이 필요하다. 향후 최적화된 병렬 모델 구조를 개발하고 출력 값들을 통합하는 중간 모듈을 개발한다면 단일 모델과 유사한 연산 시간을 확보되리라 판단되며 모델마다 최적의 파라미터를 제공하고 개별적으로 모델을 관리하는 효율적인 프로세스를 생성할 것이라 예상된다.
