

1. 서 론
2. 지반분류와 학습알고리즘
2.1 암반 분류
2.2 지도학습 기반 분류 알고리즘
3. 분류기준 및 데이터세트 구성
3.1 지반 정보 및 암반분류기준
3.2 데이터세트 구성
4. 학습 결과
4.1 평가지표 및 하이퍼파라미터 결정
4.2 분류 학습 결과
4.3 학습 결과를 활용한 암반 특성 분류 예측
5. 결 론
1. 서 론
국내 TBM(Tunnel Boring Machine)의 활용이 증가하면서 TBM의 실내 실험이나 현장 굴진자료 분석을 통한 지반 및 굴진성능 예측과 커터 마모에 대한 연구뿐만 아니라 TBM 장비의 구조, 시뮬레이터에 대한 연구 등 다양한 분야의 연구가 진행되고 있다(Bae et al., 2014, Choi et al., 2020, Kang et al., 2017, Ko et al., 2019). 더불어 최근 국내에서도 머신러닝 기법으로 TBM 데이터를 분석하여 TBM 전방의 지반을 예측하고 디스크커터의 교환주기 예측 및 굴진율을 예측하는 연구가 수행되고 있다(Jung et al., 2019, Kang et al., 2020, Kim et al., 2020a, Kim et al., 2020b, La et al., 2019).
데이터 기반으로 학습을 통해 예측을 수행할 수 있는 머신러닝(machine learning)은 데이터 특징파악, 정량화 및 패턴화, 예측으로 이어지는 과정에서 통계 및 수학적 최적화 문제와 관련이 깊으며, 인공신경네트워크, 서포트 벡터 방법, 뉴로-퍼지방법 , 하이브리드 모델 및 입자군집 최적화방법 등의 알고리즘이 TBM 분야에서 활용된 바 있다(Gholamnejad and Narges, 2010, Grima et al., 2000, Armaghani et al., 2017, Mahdevari et al., 2014, Salimi et al., 2016, Yagiz et al., 2009, Yagiz and Karahan, 2011). 머신러닝 알고리즘의 활용에서 중요한 점은 데이터 특성에 따라 적합한 알고리즘이 존재한다는 점이며, 머신러닝 기법 적용을 위해서는 학습에 적합한 데이터세트(dataset)의 구성과 분석이 필요하다.
Salimi et al.(2019)은 ANN(artificial neural network), fuzzy logic, ANFIS(Adaptive Neuro-Fuzzy Inference System)과 같은 딥러닝(Deep learning)기술이 TBM 성능예측 분야에서 폭 넓게 연구되고 있고 예측과 결과 사이에 높은 수준의 상관관계를 보이지만, 내부의 로직을 알 수 없는 블랙박스(black box)에 의해 결과가 도출되었다는 점과 다른 프로젝트에서 그 결과를 활용하기 어려운 점을 문제점으로 언급하였다. 이것은 대량의 데이터에 대한 분석과 연관된 파라미터(parameters)가 복잡하여 그 관계를 명확하게 알 수 없을 경우에 사용하는 딥러닝(Deep learning)의 인공신경망 알고리즘을 이용한 결과와 그 활용에 대해 주의 깊은 고려가 필요하다는 점을 보여준다.
Kim et al.(2021)은 시추에서 도출된 지반조사 결과를 TBM 운전에 활용하기 위해서는 시추 간격 사이의 불확실성을 해소할 필요가 있음을 언급하였다. TBM터널의 설계 시에 제한적으로 수행된 지반조사 결과를 기반으로 TBM 운전조건들이 설정될 경우, 실제 굴착 중에는 암반 상태가 다르거나 예측하지 못한 암반 이상지대가 출현하여 TBM의 굴진 성능이 저하되고 굴착 현장의 안정성 문제가 발생할 수 있다. TBM 굴진 작업은 굴착면을 이루는 암반의 역학적 특성과 지질학적 조건, TBM의 운전조건 등에 복합적으로 영향을 받기 때문에 굴착 중인 암반조건뿐만 아니라 향후 암반상태의 변화를 예측하는 것이 필요하다.
본 연구에서는 TBM 굴진 시 기계 데이터를 대상으로 전통적 암반에 대한 분류 기법과 최근에 다양한 분야에서 널리 사용되고 있는 머신러닝 기법들을 접목하여 슬러리 쉴드 TBM 현장의 암반 특성에 대한 분류 예측을 하였다. TBM 굴진 현장에 대해서 암반을 분류하는 것은 암반 종류를 비슷한 성질을 보이는 그룹으로 구분하고 공학적 성질의 판단을 통해 성질에 맞게 대응하여 TBM 운영 작업에 도움을 주기 위함이다.
2. 지반분류와 학습알고리즘
2.1 암반 분류
흙을 분류하는 목적은 비슷한 성질을 보이는 흙을 물리적, 역학적으로 유사한 거동을 보이는 그룹으로 구분하여 공학적인 성질을 파악하기 위함이다. 마찬가지로 암반 분류는 암반을 유사한 거동을 보이는 그룹으로 구분하여 특성을 파악하는 기준을 마련하고자 함이다. 암반 분류는 목적과 특성에 따라 지질학적 분류, 지반조사에 의한 분류, 공학적 분류 등으로 구분되며, 현재 주요 암반분류방법은 암반하중(Terzaghi, 1946), RQD(Rock Quality Designation, Deere et al., 1967), 암석강도(Deere & Miller, 1966), RSR(Rock Structure Rating, Wickham 등, 1972), RMR(Rock Mass Rating, Bieniawski, 1989), Q-system(Barton et al., 1974), 탄성파 속도(Anon, 1979), 지반공학적 분류(ISRM, 1981)등이 사용되고 있다. 암반분류는 암반의 중요한 특성을 쉽고 명확한 용어를 사용하여 간편하고 신속하게 분류가 가능하여야 한다. 암반 분류의 단계는 기반암을 풍화암, 연암, 보통암, 경암으로 구분하여 암종에 대한 분류와 암반 상태에 대한 암질, 색조, 풍화상태, 강도, 분연속면 간격, 절리면 거칠기 등을 구분하는 암질에 대한 분류로 나뉘어져 있다. 이러한 암반을 분류 하는 기준은 지질학적 특성에 따른 분류, 시추 난이도에 중점을 둔 분류, 공학적 특성에 의한 분류 등에 따라 다소 다를 수 있다. 본 연구에서는 암반의 특성에 대한 분류에서 대표적 공학적 특성 기준인 RQD(Table 1), 암석의 일축압축강도(Table 2), 암석의 탄성파 속도(Table 3)을 기계학습의 분류 기준 항목으로 선정하였다.
Table 1.
Rock mass quality classification according to RQD (Deere et al., 1967)
| RQD, % | Rock mass quality |
| < 25 | Very poor |
| 25 – 50 | Poor |
| 50 – 75 | Fair |
| 75 – 90 | Good |
| 90 – 100 | Excellent |
Table 2.
Classification of rocks based on UCS (ISRM, 1979)
| Classification | Uniaxial compressive strength (UCS), MPa |
| Extra weak | 0.25 – 1 |
| Very weak | 1 – 5 |
| Weak | 5 – 25 |
| Medium Strong | 25 – 50 |
| Strong | 50 – 100 |
| Very strong | 100 – 250 |
| Extra strong | > 250 |
Table 3.
P-wave velocity classification (Anon, 1979)
| Description | VP, m/s |
| Very low | < 2,500 |
| Low | 2,500 – 3,500 |
| Moderate | 3,500 – 4,000 |
| High | 4,000 – 5,000 |
| Very high | > 5,000 |
2.2 지도학습 기반 분류 알고리즘
본 연구에서는 목표변수(target)를 레이블(label)하고 훈련 데이터(training dataset)을 이용해 학습을 진행하는 지도학습(supervised learning)기반 알고리즘을 사용하였다. 또한 슬러리 쉴드 TBM 현장의 암반 특성에 대한 분류 예측을 목표로 하고 있으므로 분류 기법을 사용하였다. 분류 기법에는 많은 알고리즘이 있지만, 기본적인 알고리즘인 의사결정트리 방법과 마진(margin) 최대화를 통해 구조적으로 위험을 최소화하는 기법인 서포트벡터머신, 그리고 알고리즘 결합을 통해 결과를 향상시킨 앙상블 방법 중 부스팅(Boosting) 기법을 사용하여 학습을 수행하였다. 각 기법에 대한 간단한 설명은 다음과 같다.
2.2.1 의사결정트리(Decision Tree Analysis)
의사결정트리는 주어진 데이터를 분류하고 규칙을 찾는 방법이다. 트리 기반으로 한 번 분리를 진행해서 변수를 구분하는 영역을 만들어 원하는 클래스 값을 구한다. 의사결정트리 기법은 연속형, 범주형 변수에 모두 사용 가능하고 차원축소나 변수 선택 등 의사결정 생성과정을 통해 많은 변수 중에서 상대적으로 종속변수에 주는 영향을 파악할 수 있다(Breiman et al., 1984). 트리기법은 그룹별로 특징을 발견하거나 어느 집단에 속하는지 여부를 파악하여 세분화하는 데 효율적인 기법이다. 변수의 정규화나 표준화 같은 전처리가 필요하지 않으며, 특정 변수의 값이 누락되어도 사용 가능하나, 학습데이터에 과대 접합되는 특징 때문에 새로운 데이터에 적용하면 예측 성능이 좋지 않아 일반화가 어렵다는 단점이 있다.
2.2.2 서포트벡터머신(Support Vector Machine, SVM)
서포트 벡터 머신은 패턴 인식과 자료 분석 등으로 자주 활용되는 기계학습 모델로써 러시아의 수학자 Vapnik et al.(1996)이 제안하였다. 학습자료 특성이 변수들로 표현된다고 할 때, 학습 샘플 자료들을 n 차원의 데이터 공간에 분포시키고 이를 구분하는 최적의 경계를 찾아내는 알고리즘이다. 서포트 벡터의 원리는 최대 마진(maximum margin)을 갖는 결정경계를 찾는 것에 있다. 마진은 가장 가까운 데이터 포인트로 이루어진 결정경계 사이의 거리를 의미하는데, 서포트 벡터 머신의 분류는 일정한 마진 오류 안에서 데이터 클래스를 구분하는 폭이 가장 최대가 되도록 하는 경계를 찾는 것이 목표이다.
2.2.3 앙상블 기법 : 부스팅(Ensemble Learning Method, Boosting)
더 좋은 예측 성능을 위해 서로 다른 분류 알고리즘 모델을 생성하고 결합하여 최적의 결과를 추출하는 데 활용하는 것을 앙상블 모델이라고 한다. 대표적으로는 Breiman (1996)에 의해 제안된 배깅(Bootstrap Aggregating, Bagging)과 Kearns and Valiant (1994)가 처음으로 분류 알고리즘에 제안한 부스팅이 있다. 중복 샘플을 활용하여 다양하게 학습하는 배깅은 단일 혹은 여러 모델을 병렬적으로 사용하는 모델이고, 이와 다르게, 부스팅은 단일 모델을 활용하여 순차적으로 학습하고 발생하는 오차를 보안하기 위해 다음 분류기에 가중치를 부여하고 다시 학습을 진행하는 방식이다.
3. 분류기준 및 데이터세트 구성
3.1 지반 정보 및 암반분류기준
학습 대상인 슬러리 쉴드 TBM 터널 현장의 기반암은 편마암 류가 주로 분포하고 화강암과 운모편마암이 일부 관입하고 있으며, 상부 구성 토질은 실트질 모래 혹은 모래섞인 자갈로 구성되어 있다. 분석에 사용된 지반정보는 터널 설계 시 작성된 지반조사보고서와 터널 종단면도로부터 수집하였다.
설계 시 시행된 지반조사에서 쉴드 TBM 터널 구간에는 총 36개의 시추가 이루어졌으며, 시추 시료에 대해 수행된 암석 물성 시험 결과, RQD는 8 ~ 100%, 일축압축강도는 21.88 ~ 116 MPa, 탄성파 속도(P wave)는 약 2,000 ~ 5,000 m/s 범위로 나타났다. 쉴드 TBM 터널 구간의 암반 구성은 연암파쇄대가 12%, 연암이 23%, 경암이 65%이고, RQD는 25 이하가 24%, 25~50가 30%, 50 이상이 46%로 대체로 양호한 암질이 분포하고 있었다.
슬러리 쉴드 TBM 굴진 데이터를 이용한 암반 특성 분류 학습을 위해 암반의 특성 분류 기준을 구성하였다. 분류를 위한 기준 항목, 즉 암반 특성은 앞서 2.1절에서 언급한 바와 같이 RQD, 일축압축 강도, 탄성파 속도(P파)를 사용하고 이 3가지 항목에 대해 각 3개의 클래스를 설정하였다. 클래스별 분류는 Table 4와 같이 RQD가 양호(50 이상), 일축압축강도가 강함(50 MPa이상), P파속도가 보통 (3,500 m/s이상)의 경우를 암반 상태가 좋은 클래스 0으로 설정하고, RQD가 매우 나쁜(25이하), 일축압축강도가 약한 (25 MPa이하), P 파의 속도가 매우 낮은(2,500 m/s이하) 경우를 암반 상태가 안 좋은 클래스 2로 설정하였다. 그리고 중간 값들을 보통 상태의 클래스 1로 구분하였다.
Table 4.
Criteria for classification of rock mass quality
| Class range | Description | ||
| RQD | UCS (MPa) | VP (m/s) | |
| 0 | RQD ≥ 50 | UCS ≥ 50 | VP ≥ 3,500 |
| 1 | 25 < RQD ≤ 50 | 25 < UCS ≤ 50 | 2,500 < VP ≤ 3,500 |
| 2 | RQD < 25 | UCS < 25 | VP < 2,500 |
3.2 데이터세트 구성
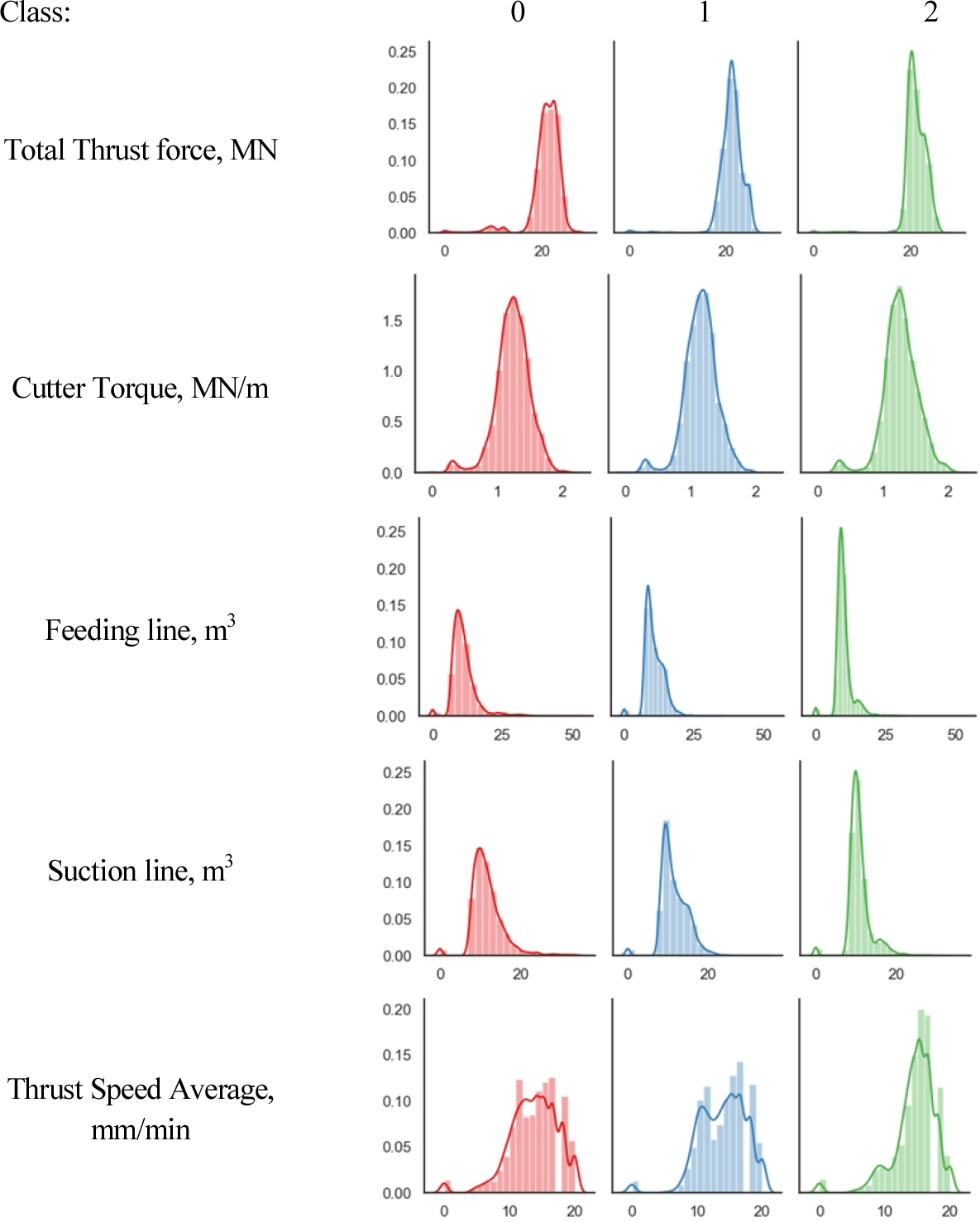
굴진 데이터를 얻은 슬러리 쉴드 TBM 장비의 주요 제원은 Table 5와 같다. 장비의 직경은 7.3 m이고, 최대추력은 56 MN, 최대토크는 13.12 MN・m, 최대 RPM은 1.4이다. 굴진 데이터 분석 결과, 사용된 추력의 평균은 장비 최대 성능의 약 45.2%이고, 커터헤드 토크의 평균은 장비제원 최대 토크의 24.6% 범위에서 주로 사용된 것을 확인할 수 있었다. Table 4에서 분류한 암반 특성 분류 기준에 따라 지반조건에 상응하는 TBM 굴진 데이터를 매칭한 결과에서 Fig. 1과 같이 각 주요 굴진 데이터 항목의 분포 특성이 암반 특성에 따라 변하는 것을 확인할 수 있었다.
Table 5.
Summary of TBM specification
쉴드 TBM 굴진 현장에서는 압력 관련 변수, 속도 관련 변수, 온도 관련 변수, 위치/방향 관련 변수, 굴진 시간이력 관련 변수 등 광범위한 기계 데이터 수천개가 생성될 수 있으며, 학습 대상 현장에서는 약 600여개가 기록되었다. TBM의 굴진 데이터를 기반으로 정확하고 효과적인 분류 예측을 수행하기 위해서는 목표에 맞는 특성변수 항목의 선택과 선택된 데이터의 선처리가 무엇보다 중요하다.
본 연구에서는 굴진 데이터에서 분류 예측에 기여하지 않는 다양한 전압 측정값, 계측 온도, 위치 및 자세 정보와 같은 매개변수를 분석에서 제외하고, 매개변수 간 상관도를 확인하여 TBM 굴진에서 중요한 기계데이터인 굴진속도(thrust speed average), 총 추력(total thrust force), 커터토크(cutter torque), 커터헤드 회전속도(cutterhead rotation speed), 송니압(feeding line pressure), 송니유량(feeding line discharge), 배니유량(suction line discharge)을 특성변수로 선정하였다. 그리고 수집된 전체 굴진 데이터(약 118,000 여개) 중에서 시추 기반 지반조사가 이루어진 위치와 매칭이 되는 기계데이터(약 20,000 개)를 데이터세트(dataset)로 구성하였다. 시추데이터는 TBM 통과(직경 7.3 m) 위치(level)의 시추데이터만을 사용하였으며, TBM 노선과 대응되는 시추공 위치(중심)기준으로 앞과 뒤 10 m위치의 굴진데이터를 사용하여 데이터세트를 구성하였다.
4. 학습 결과
4.1 평가지표 및 하이퍼파라미터 결정
앞서 2.2절에서 언급한 지도학습 기반 분류 알고리즘들 중에서 본 연구에서 사용된 분류 알고리즘은 단일 기법으로는 의사결정트리 기법과 서포트벡터 기법이 있고 앙상블 기법(Ensemble Learning Method: Boosting)으로는 약학습기(weak learner)를 활용하는 대표적인 에이다 부스팅(Ada Boosting), 그레디언트 부스팅(Gradient Boosting)과 그레디언트 부스팅의 느린 학습 속도와 과접합 문제를 보안한 XG 부스팅(eXtreme Gradient Boosting,XG boosting), Light GBM(Light Gradient Boosting Machine)가 있다. 기계학습 알고리즘의 적합성을 평가하기 위해서 학습 데이터(training data)와 테스트 데이터(test data)를 8:2 비율로 분할하였다. 학습된 기계학습 분류 모델의 예측성능을 평가하는 방법으로는 Table 6과 같이 분류 모델의 정답과 오답을 보여주는 혼돈행렬(confusion matrix)을 이용한 분류 모델 평가 지표인 정확도(accuracy), 정밀도(precision), 재현율(recall), F1-스코어(score)를 사용하였다(Table 7).
Table 6.
Confusion matrix of classification
| class | Positive (1) | Negative (0) |
| Positive (1) | True Positive | False Positive |
| Negative (0) | False Negative | True Negative |
Table 7.
Classification performance measures
데이터 전처리(Preprocessing)과정으로 표준화(Standardization)를 적용하고, 데이터세트에서 TBM 장비 제원과 굴진 데이터를 확인하여 결측치와 이상치를 제거하였다. 본 연구에서 기계학습에 사용한 데이터세트의 유의확률(P-value)은 통계적 가설 검증 기준인 0.05이하로 계산되어 통계적으로 유의함을 확인하였으며, 각 알고리즘에 대해서 교차검증(Cross Validation, CV)을 수행하였고 성능비교를 통해 가장 좋은 성능을 내는 하이퍼파라미터(hyperparameter) 조합을 찾기 위해 GridSearchCV 튜닝 기법을 적용하여 각 분류 모델에 적합한 하이퍼파라미터를 결정하였다(Table 8).
Table 8.
Summary of hyperparameters for classification models
4.2 분류 학습 결과
3개 클래스의 암반 특성 분류 기준과 슬러리 쉴드 TBM 굴진 데이터, 그리고 지반정보를 기반으로 6개의 분류 알고리즘을 이용하여 학습을 수행하였다. 일반적으로 모델의 적합성을 나타내는 정확도는 1.0에 가까울수록 분류 성능이 우수하고 결과의 정확도가 높은 것을 나타내지만, 클래스에 대한 예측결과의 불균형이 발생할 수 있으므로 정밀도(precision), 재현율(recall), f-스코어를 종합적으로 보고 모델성능을 판단한다(Table 7). 각 모델의 학습 결과는 Table 9와 같다.
학습 결과, RQD 항목의 분류 기준에 대한 의사결정트리의 정확도(0.631)와 에이다 부스팅의 정확도(0.580)가 낮게 평가되었으며, 정밀도와 재현율의 평균값이 각각 0.62,0.56과 0.61, 0.56으로 유사하게 나타났다. 앙상블 부스팅 모델인 그레디언트 부스팅과 XG부스팅, LightGBM, 서포트벡터 모델의 분류 성능은 정확도가 0.904~0.912로 비슷한 경향을 보였으며, 정밀도와 재현율, f-스코어의 평균값도 0.90 이상으로 높은 성능지표를 보였다.
일축압축강도(UCS) 항목의 분류 기준에 대한 의사결정트리의 정확도는 0.702이고, 에이다 부스팅의 정확도가 0.802로 분류 성능이 보통 정도로 나타났다. 정밀도의 평균값은 각각 0.76, 0.77로 보통 정도였으나, 재현율의 평균값은 0.47과 0.69로 성능이 낮은 것으로 계산되었다. 그레디언트 부스팅과 XG부스팅, LightGBM, 서포트벡터 모델에 대한 분류 성능은 정확도가 0.956~0.965로 높은 성능을 보였으며, 정밀도와 재현율, f-스코어의 평균값도 0.94 이상으로 높게 나타났다.
Table 9.
Evaluating the performance of the classification for Shield TBM Datasets
탄성파속도(VP) 항목의 분류 기준에서도 의사결정트리의 정확도(0.784)와 에이다 부스팅의 정확도(0.712)는 보통 정도로 나타났다. 또한 정밀도와 재현율의 평균값도 각각 0.69,0.66과 0.71,0.65로 다소 낮은 경향을 보였다. 반면, 그레디언트 부스팅과 XG부스팅, LightGBM, 서포트벡터 모델에 대한 분류 성능은 정확도가 0.962~0.970으로 높고, 정밀도와 재현율, f-스코어의 평균값도 0.95 이상으로 높은 성능을 보였다.
본 연구에서 사용한 슬러리 TBM 굴진데이터에 대한 암반 특성 분류 성능을 보면 앙상블 모델인 그레디언트 부스팅과 XG부스팅, LightGBM, 서포트벡터 모델이 모두 좋은 결과를 보였다. 성능 측면에서만 보면 의사결정트리와 에이다 부스팅을 제외하고 모두 비슷한 성능을 보였다. 그러나 각 모델의 전산자원 소모량과 학습속도 측정 측면을 고려할 때, 조정해야 할 하이퍼파라미터 숫자와 모델별 특성에 따라 차이가 있지만 동일한 컴퓨터에서 모델 학습이 진행된다고 가정한다면, LigthtGBM, XG부스팅,그레디언트 부스팅, 서포트벡터 모델 순으로 학습 진행 속도가 빠른 것으로 판단된다.
학습속도가 빠른 LightGBM 결과를 기반으로 3개 클래스의 분류 기준에 대한 정확도를 비교해 보면 탄성파 속도(VP)에 의한 분류(0.970), 일축압축강도(UCS)에 의한 분류(0.965), RQD(0.912)에 의한 분류 순이지만 모델 간 성능 차이는 크지 않은 것으로 판단된다.
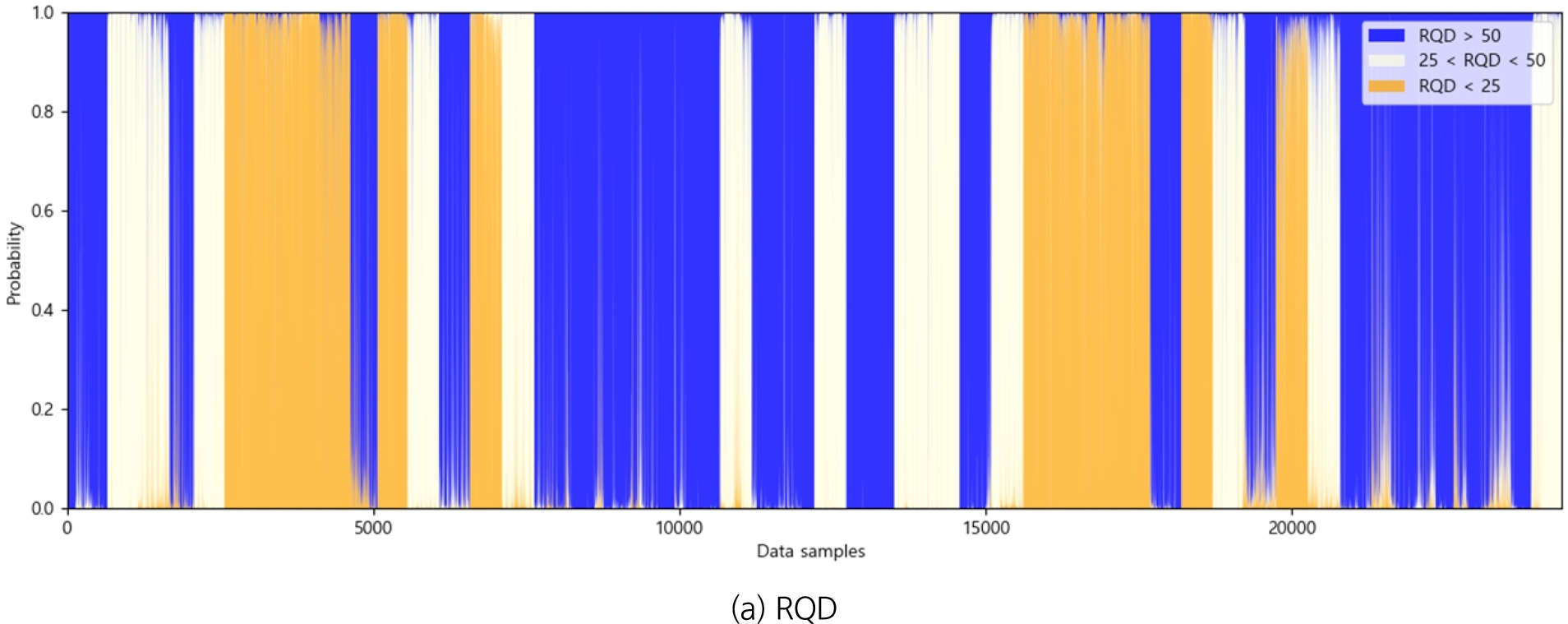
학습 결과에서 성능이 가장 좋고 학습 속도가 우수한 LightGBM 모델을 이용하여 학습에 사용된 전체 데이터 세트를 대상으로 암반 특성 분류 예측을 수행하였다(Fig. 2). 이때 대상 데이터 세트는 지질 정보가 존재하는 구간만으로 한정하여 구성하였다. 분류 예측에서 3가지 분류 클래스에 대해 예측한 확률의 합은 1이 최대이며, 각 데이터 위치에서 높은 확률을 보인 클래스를 확인할 수 있다. 구성된 데이터세트에 대한 암반 특성 분류 모델의 예측한 결과를 보면 RQD, 일축압축강도, 탄성파 속도(VP) 기준에 따른 암반 품질에 대한 예측이 다름을 확인할 수 있다.
4.3 학습 결과를 활용한 암반 특성 분류 예측
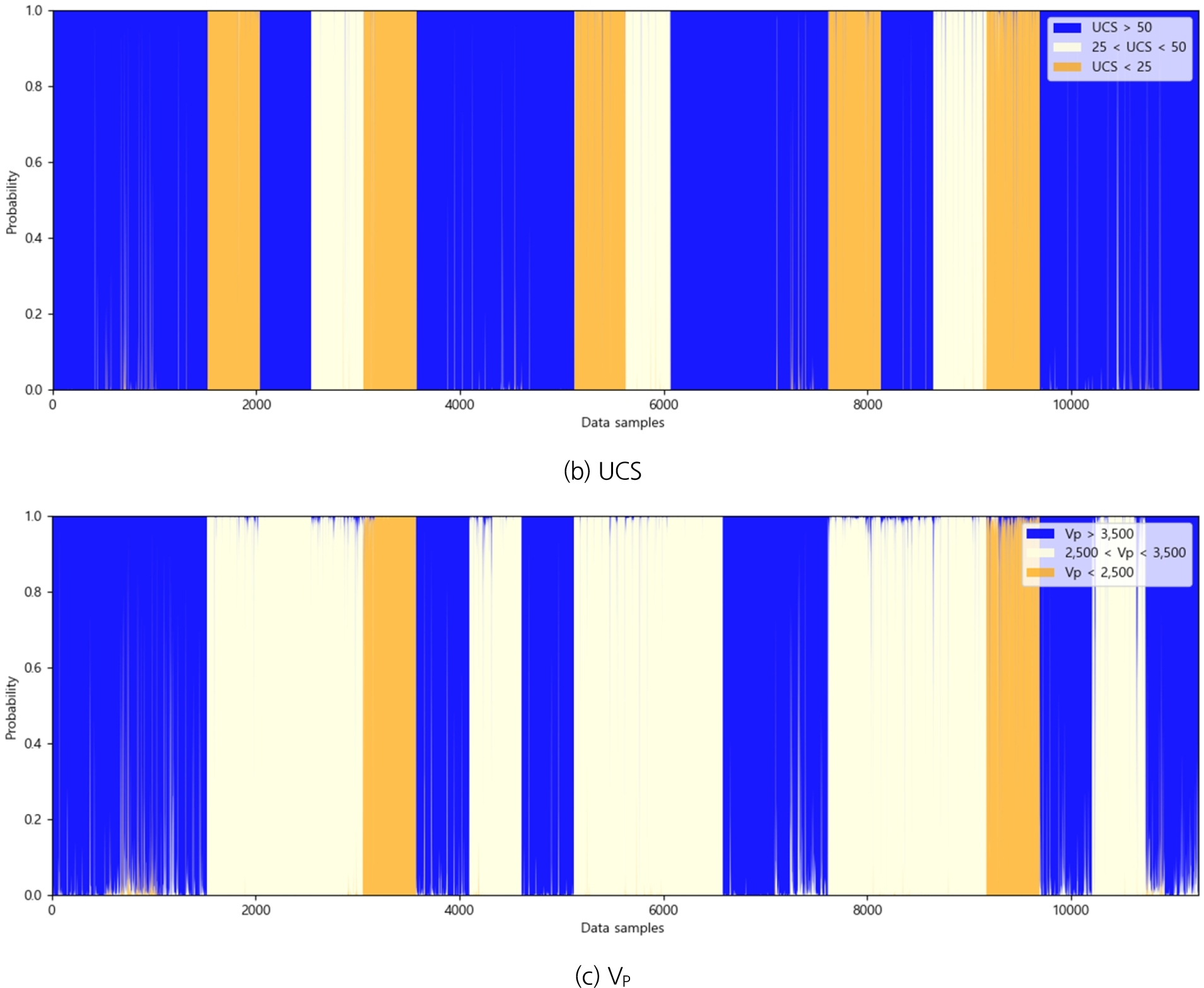
일반적으로 터널설계를 위해 기본물성 시험, 수리특성 시험, 연약지반특성 시험이나, 탄성파 탐사 등의 다양한 지반조사가 수행되지만, 기본적인 시험을 제외하고는 대부분의 시험이 이뤄지는 대상이 일부지역에 국한되어 있고 실제 굴진 시 활용 가능한 지반정보가 터널의 일부구간으로 제한되어 있다. 앞서 4.2절에서는 설계 시 조사한 지반조사 결과와 매칭이 되는 굴진 데이터를 활용하여 3가지 분류 기준에 대한 암반 특성 분류 예측을 수행하였다. 학습 결과로 도출된 3가지 분류 기준별 암반 특성 예측 분류 모델을 사용하여 전체 TBM 굴진 데이터를 대상으로 암반 특성을 분류하였다. Fig. 3(a)는 RQD 분류 기준에 의한 분류 모델의 결과이고, Fig. 3(b)는 일축압축강도(UCS)에 의한 분류 모델의 결과이며, Fig. 3(c)는 탄성파속도(VP) 에 의한 분류 모델의 결과로 전체 TBM 터널 굴진구간에 대해 암반 특성을 예측한 결과를 제시하였다. 이러한 분류 모델을 토대로 지반정보가 없는 구간에서도 암반의 특성 분포와 전체 구간의 암반상태를 확인할 수 있다.
5. 결 론
본 연구에서는 슬러리 쉴드TBM 터널 현장의 지반정보와 굴진정보를 기반으로 기계학습을 사용하여 암반 특성에 대한 분류예측을 하였다. 암반 특성에 관한 분류 기준은 암석의 RQD, 일축압축강도, 탄성파 속도(VP)를 사용하였고 TBM 터널의 데이터를 대상으로 6개의 기계학습 분류 알고리즘을 적용한 학습을 통해 각 모델에 적합한 하이퍼파라미터를 선정하였으며, 분류 모델 결과를 토대로 최적 모델을 도출하는 연구를 수행하였다.
암반 특성 분류 기준 항목에 따라 암반상태를 클래스 0(양호), 1(보통), 2(불량)의 3개 클래스로 구분하였고 클래스에 따라 추력, 토크 등과 같은 주요 굴진데이터의 분포특성을 도시해본 결과, 암반 특성에 따라 변하는 것을 확인할 수 있었다.
각 분류 모델에 대한 학습결과의 평가는 정확도, 정밀도, 재현율, f-스코어를 사용하여 종합적으로 성능을 판단하였다. 혼동행렬을 사용하여 분류 모델에 대한 평가를 수행한 결과, 의사결정트리와 에이다 부스팅은 3개의 암반 특성 분류 기준 항목에 따라 0.580~0.802 정도의 정확도를 보여주었으나 정밀도 재현율이 0.5~0.7로 나타나 보통 이하의 성능으로 나타났다. 반면에, 그레디언트 부스팅과 XG 부스팅, LightGBM, 서포트벡터 모델은 정확도, 정밀도, 재현율이 모두 0.90이상의 우수한 성능을 보여주었다.
성능측면에서 앙상블 모델의 대부분이 좋은 결과를 보여주었으나, 위의 4가지 평가지표 외에도 기계학습 모델의 적용에 중요한 요소인 전산자원 소모량과 학습속도 측면을 고려할 필요가 있기 때문에 동일 조건에서 학습이 진행된다는 가정에서 LigthtGBM, XG부스팅,그레디언트 부스팅, 서포트벡터 모델 순으로 학습 진행 속도가 빠른 것으로 예상되었다.
현재까지의 결과를 종합적으로 살펴보면, 학습 성능과 속도에서 모두 우수한 LightGBM이 이번 연구의 대상인 슬러리 쉴드 TBM 현장의 굴진정보를 기반한 암반 특성 분류 예측에 적합한 모델이다. 본 연구에서 설정한 3가지 암반 특성에 대한 분류 모델을 활용하면 지반정보가 제공되지 않은 구간에 대한 암반 상태를 제공하여 굴착작업 시 도움을 줄 수 있을 것으로 판단된다. 하지만, 본 연구의 결과는 단일 현장의 데이터를 기반으로 도출된 것으로 추후 다양한 현장의 데이터에 대한 검증이 필요하다.
