

1. 서 론
2. 연구 방법
2.1 딥러닝 기반의 스타일 변환(Style Transfer) 기법
2.2 위치정보 기반 스타일 변환 알고리즘
3. 실험 결과 및 분석
3.1 실험용 데이터 설명
3.2 위치정보 기반 스타일 변환 성능 비교
3.3 소결
4. 결 론
1. 서 론
최근 대한민국뿐만 아니라 미국, 유럽, 일본, 중국 등 세계 주요 각국에서 달 자원 확보 및 유인 기지 건설을 위한 달 탐사 연구가 활발히 진행되고 있다(Ju, 2016, Lee et al., 2020). 달 현지에서 유인 기지 건설을 위해서는 실제 현장 정보가 반영된 달 지형정보 구축이 선행이 필수적이다(Hong et al., 2019). 이에 따라 무인 로버에 장착된 영상 센서 기반의 지형정보화 기술이 활발히 개발되는 추세다(Di et al., 2020, Park et al., 2020).
한국건설기술연구원은 무인 이동체 탑재 광학 카메라 기반의 달 지형정보화 기술 개발을 위해 연천 SOC 실증연구센터 부지에 모의 행성 지형을 조성하고, 무인 이동체 영상으로부터 딥러닝 영상처리를 통해 모의 달 표면 내 지형/지물 객체를 자동 검출하는 연구를 진행한 바 있다(Hong and Shin, 2018, Lee et al., 2019). 하지만 모의 달 지형 영상 데이터는 실제 달 표면 배경과 상이하므로, 모의 현장에서의 학습 및 추론 성능이 실제 달 현지에서의 적용성과는 큰 차이가 있을 수 있다. 또한, 학습을 통한 추론 성능은 학습 영상자료에 의해 지배적으로 좌우되므로, 달 환경과 최대한 유사한 영상을 학습에 사용하여나 하나, 지구 상의 환경에서 물리적으로 달 현장을 모사하여 영상을 확보하기엔 한계가 있다. 따라서 현지 조건에서 정확도 높은 객체 인식 성능을 얻기 위해서는 많은 양의 데이터는 물론, 달 현지와 유사한 배경과 조명, 색상 톤이 충분히 유사한 학습 영상데이터 확보가 담보되어야 한다. 하지만 달 표면 영상과 같은 희귀한 데이터는 직접 수집하는데 큰 어려움이 있어, 이를 대체할 유사 영상 데이터를 인위적으로 생성하는 방안을 모색하였다.
본 연구에서는 과거 달 탐사 무인 이동체(Yutu-2) 및 유인 우주선(Apollo-11)으로부터 수집한 영상(Basilevsky et al., 2015, NASA, 2021) 자료를 활용해 딥러닝 기반의 스타일 변환(Style Transfer) 기법을 적용하여 사실적인 이미지 생성 실험을 진행하였다. 스타일 변환 기법은 대상 이미지와 스타일 이미지가 있을 때 대상 이미지 내 객체 및 지형, 지물 형태를 유지시키고, 스타일 이미지의 배경 환경처럼 변화시키는 방법을 의미한다.
최초로 신경망 기반으로 구현된 스타일 변환 알고리즘은 Gatys et al.(2016)에 의해 제안되었다. Gatys et al.(2016) 알고리즘은 특정 이미지를 화가의 화풍을 반영하고자 설계되어 위치 정보를 고려하지 않고 대상 이미지와 스타일 이미지의 특징을 합성하였다. 따라서 대상 이미지의 왜곡이 나타났으며, 스타일 변환 시 잘못된 위치에 반영되는 경우가 발생하였다. 이에 따라 Luan et al.(2017)은 Segmentation Mask 정보를 추가로 반영하여 동일한 객체 영역끼리 스타일 변환 가능한 DPST (Deep Photo Style Transfer) 알고리즘을 제안하였다. 하지만 CNN 네트워크로 특징 추출 시 정보의 손실이 발생하여 대상 이미지 왜곡 문제는 여전히 나타났고 사실적인 이미지 생성에 큰 문제점으로 작용하였다. Yoo et al.(2019)은 웨이블릿 기법을 활용하여 특징 추출 시 정보의 손실을 최소화 하는 기법을 제안하여 대상 이미지의 형태를 보존하는 WCT2 (Wavelet Corrected Transfer Based On Whitening And Coloring Transforms) 알고리즘을 제안하였다.
이에 따라 본 논문에서, 우리는 딥러닝 기반의 스타일 변환을 이용하여 달 환경에서 객체 인식률의 검출 대응력을 높이고자 다양한 조건의 달 유사 영상 학습 데이터를 인위적으로 생성하는 방안을 제안한다. 다양한 모델로 실험을 진행하였으며 각 모델 간 알고리즘 비교를 정성적, 정량적 측면에서 평가하였다. 최종적으로 모의 행성지형 영상 정보를 실제 달 표면과 유사하도록 합성 영상을 생성하였다. 향후 인공 데이터의 학습자료 재반영을 통해 실제 달 현지에서의 객체 인식 대응력 향상에 기여할 것이라 예상된다. 다음 장에서는 기존의 스타일 트랜스퍼의 연구에 대한 지식을 제공하며, 3장에서는 실험 결과와 분석을 제공하고 4장에서는 본 논문의 결론을 제시한다.
2. 연구 방법
2.1 딥러닝 기반의 스타일 변환(Style Transfer) 기법
스타일 변환 기법은 전통적인 이미지 합성 기술 중에 하나로 대상 이미지와 스타일 이미지가 주어져 있을 때, 대상객체의 형태는 대상 이미지와 유사하게 유지하면서 배경과 영상의 톤만 스타일 이미지로 변환시키는 방법이다. 합성곱 신경망(CNN)의 발전으로 전통적인 이미지 합성 기술의 성능을 능가하는 합성곱 신경망을 활용한 딥러닝 기반 스타일 변환 연구가 활발하게 진행되었다. 다음 Fig. 1은 딥러닝 기반 스타일 변환 기법의 예시를 도시하였다. Fig. 1(a)은 대상 이미지이며 Fig. 1(b)은 스타일 이미지로 두 이미지로부터 스타일 변환 기법을 통해 Fig. 1(c)과 같은 결과를 생성 가능하다.

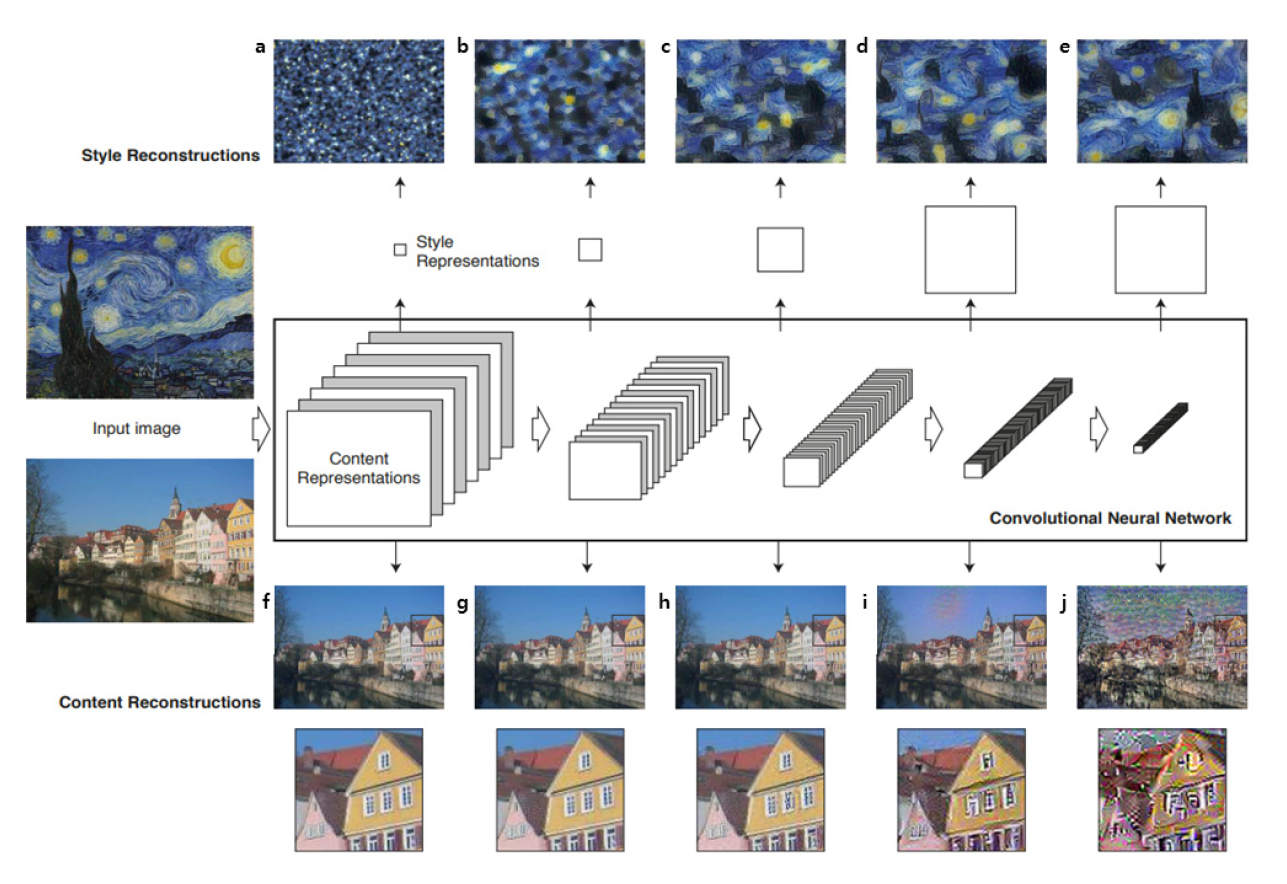
Fig. 2.
Feature extraction results for target and style image according to the CNN process (Gatys et al., 2016)
Gatys et al.(2016)은 최초로 합성곱 신경망을 활용하여 스타일 변환 기법을 제안하였다. 다음 Fig. 2는 대상 이미지와 스타일 이미지가 합성곱 신경망을 통과하면서 변화되는 특징 추출 결과를 보여준다. 스타일 변환 기법은 Fig. 2(a)처럼 랜덤한 노이즈를 갖는 초기 이미지를 생성하고 합성곱 신경망을 이용해 대상 이미지와 비교하여 Fig. 2(j)처럼 전체적인 윤곽에 관련된 특징 벡터를 추출한다. 동시에 반영할 스타일 이미지의 스타일 특징 벡터만 추출하여 초기 이미지와 공분산 차이를 줄임으로서 Fig. 2(e)처럼 배경 정보를 추출한다(Li et al., 2017). 최종적으로 Fig. 2(j) 대상 이미지의 윤곽과 Fig. 2(e) 스타일 이미지의 배경 특징 정보를 조합해 스타일 변환된 합성 영상을 생성하도록 설계되어 있다.
이에 따라, 무인 지형정보화 기술 실험부지 영상 정보를 Gatys et al.(2016) 방법을 통해 실험한 결과 Fig. 3(b)처럼 변환 결과를 얻었다. 하지만, Fig. 3(b) 결과를 보면 동일한 영역끼리 스타일이 반영되지 않고 잘못 전이되는 사례를 확인하였다. 또한, 영상 내 지반 정보의 왜곡현상이 발생하여 중요한 정보손실이 발생하였다. 이에 따라 위치정보에 기반을 둔 스타일 변환 기법의 필요성이 대두되었다.

2.2 위치정보 기반 스타일 변환 알고리즘
Luan et al.(2017)은 위치정보를 고려해 스타일 변환이 가능한 DPST (Deep Photo Style Transfer) 알고리즘을 제안하였다. 대상 이미지와 스타일 이미지 외에 Fig. 4(c)와 Fig. 4(d)처럼 추가로 Segmentation Mask 정보를 제공하여 동일한 영역끼리 스타일 변환이 가능하도록 구현하였다. 이로 인해 Gatys et al.(2016) 알고리즘에서 잘못 전이되는 치명적인 문제를 상당히 보완하였다.

하지만 Fig. 4(e) 결과를 보면 기존 대상 이미지의 지반 정보가 왜곡되는 문제 또한 완화되었지만 지속적으로 발생하였다.
따라서 Yoo et al.(2019)는 반복적인 모델의 속도 문제와 CNN 모델에서 주로 사용되는 Max-Pooling 단계의 정보 손실이 발생하는 단점을 보완하는 하르 웨이블릿 풀링 기법(Harr Wavelet Pooling)을 적용한 WCT2 (Wavelet Corrected Transfer based on Whitening and Coloring Transform) 알고리즘을 제안하였다.
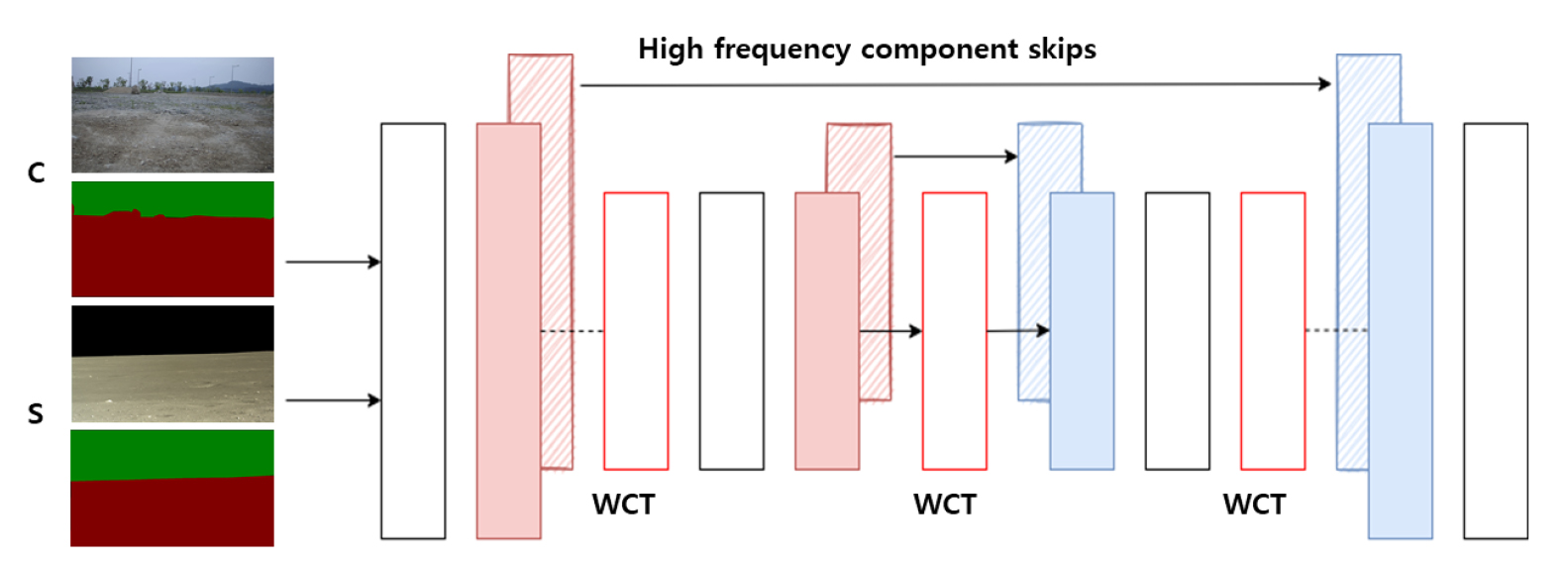
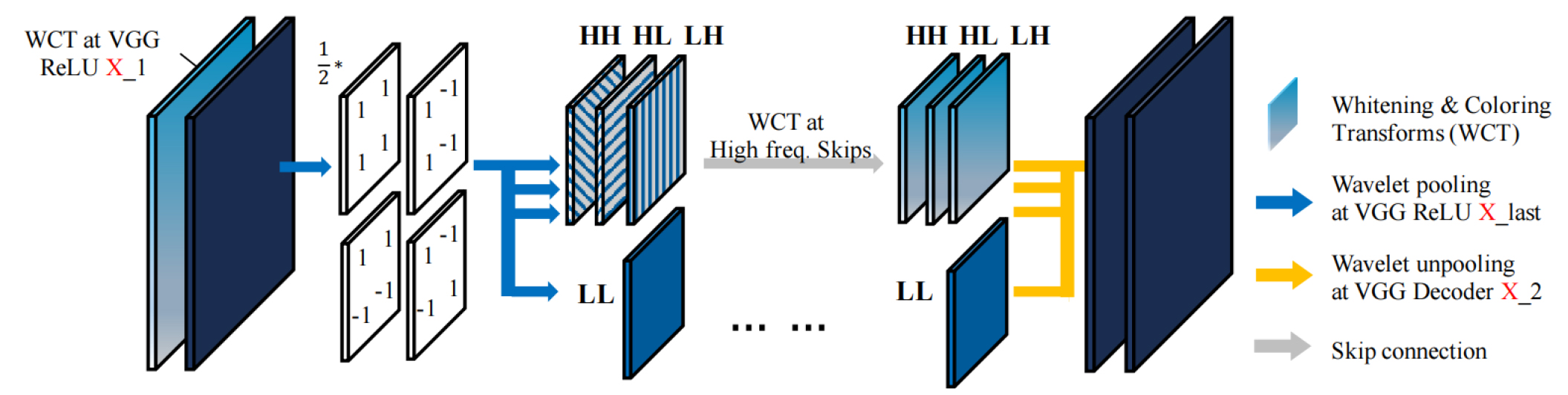
다음 Fig. 5는 WCT2 모델의 구조이며 전체적인 네트워크는 Encoder-Decoder 구조(Bengio, 2009)로 구성된다. Encoder는 이미지를 압축하면서 특징을 추출하고 Decoder는 이미지를 복원하는 기능을 갖는다. 입력은 총 4개(대상 영상, 대상 마스크, 스타일 영상, 스타일 마스크)의 데이터가 들어가며, 제공된 마스크 정보로 동일한 클래스 영역끼리 스타일 변환을 진행하도록 설계된다. 입력 이미지는 Encoder 과정으로 압축되는데 ImageNet (Deng et al., 2009)데이터로 사전에 학습된 VGG-19 네트워크(Simonyan and Zisserman, 2014)를 사용한다. 또한 네트워크를 통과하면서 Fig. 6와 같이 하르 웨이블릿 풀링 모듈(Stanković and Falkowskie, 2003, Williams and Li, 2018)이 사용되는데, 기존 CNN에서 사용하는 Max-Pooling 대신 Wavelet Corrected Transfer를 사용하고 각 층마다 Whitening and Coloring Transforms (Yijun et al., 2017) 을 이용하여 특징 변환을 수행한다. 하르 웨이블릿 풀링 모듈은 총 4개의 필터(LL, LH, HL, HH)가 적용되며 식 (1)과 같이 L은 저역필터(Low-pass filter), H는 고역 필터(High-pass filter)를 의미한다. 저역 필터(LL)는 매끄러운 표면과 질감 정보를 포함하는 반면 고역 필터는 수직(LH), 수평(HL) 및 대각선(HH) 그리고 가장자리와 같은 정보를 추출한다.
다시 말하자면, 고역 필터(LH, HL, HH)가 포함된 경우는 CNN 과정에서 대상 이미지의 윤곽정보의 정보 손실을 최소화하도록 조정 없이 통과시켜 대상 이미지의 형태를 최대한 유지시킨다. 이렇게 대상 이미지 형태와 스타일 이미지의 스타일을 추출한 후 Decoder 과정에서 Unpooling 기법을 통해 정보를 복원하면서 스타일 변환이 완료된 결과를 도출하게 된다. WCT2는 DPST에 비해 연산속도가 매우 빠르며, 메모리 사양도 대폭 감소시켰다.
3. 실험 결과 및 분석
3.1 실험용 데이터 설명
본 연구에서 사용된 대상 이미지는 한국건설기술연구원 연천 SOC 실증연구센터 내 무인 지형정보화 기술 실험부지에서 로버를 활용해 촬영한 영상을 사용하였으며 그 전경은 다음 Fig. 7과 같다(Hong et al., 2021). Fig. 7(a)은 모의 달 지형 시험부지의 전체 현장을 보여주는 항공 영상이며, Fig. 7(b)는 데이터 수집에 이용된 로버이다. 그리고 Fig. 7(c)은 로버 측면에서 수집한 영상의 샘플을 보여준다.
Fig. 8은 실험에 사용된 영상과 그에 맞는 위치 정보 데이터를 순서대로 도식화하였다. Fig. 8(a) 와 Fig. 8(b)는 실험에 사용된 현장 대표 이미지이며, Fig. 8(c)과 Fig. 8(d)은 스타일 변환에 사용된 스타일 영상으로 과거 중국의 달 탐사 무인 이동체 Yutu-2에서 촬영된 영상과 미국의 유인 착륙선 Apollo-11에서 촬영한 달 표면 영상이다. Fig. 8(e)에서 Fig. 8(h) 영상은 동일한 영역끼리 스타일 전이가 가능하도록 추가적인 위치정보를 나타내는 Segmentation Mask 정보다. 여기서, Mask 정보를 생성하기 위해 ‘Labelme’ 오픈소스 레이블링 툴(Labelme, 2021)을 이용하였다. 녹색은 하늘영역을 나타내며, 적색은 지반영역을 나타낸다.


3.2 위치정보 기반 스타일 변환 성능 비교
3.2.1 실험 조건 및 환경
실험에 사용된 학습 환경은 Ubuntu 18.04에서 Python 3.8로 스타일 변환 모델을 실행하였으며, Torch 0.4 버전의 딥러닝 프레임 워크를 이용한다. 하드웨어의 경우 CPU는 6코어 6스레드인 INTEL i5-8500, RAM 용량은 32GB, GPU는 NVIDIA GTX 2080 Super로 이미지 생성에 활용하였으며, 딥러닝 코드의 구조상 CPU 및 RAM을 활용하므로 딥러닝 모델 및 계산 용량에 맞추어 CPU 및 RAM을 설정하였다.
3.2.2 변환 소요시간 성능 비교
DPST 알고리즘은 다층 구조로 모델이 구현되어 있어 동일한 네트워크를 재귀적으로 반복해 수행한다. 따라서 상당한 시간이 필요한 반면 WCT2 알고리즘은 단방향 및 전방향 네트워크만 거치기 때문에 매우 빠른 속도로 스타일 변환이 가능하다. Table 1은 이미지 해상도에 따른 스타일 변환 소요시간을 측정한 결과이며, 스타일 변환 횟수 총 30번 수행한 결과의 평균값을 사용하였다. 해상도 1024×1024 기준으로 WCT2 알고리즘은 DPST 알고리즘보다 최대 800배 정도 빠른 결과를 보여준다.
Table 1.
Style transfer time corresponding to image size
| Image Size | DPST | WCT2 |
| 256 × 256 | 480.9 sec | 5.4 sec |
| 512 × 512 | 1512.3 sec | 6.2 sec |
| 1024 × 1024 | 6322.7 sec | 8.1 sec |
3.2.3 정량적 측면 성능 비교
두 알고리즘의 정량 성능 평가는 이미지 간의 특징 거리 측정에 가장 널리 사용되는 Frechet Inception Distance (FID) (Heusel et al., 2017)지표를 이용하였다. FID는 네트워크를 통해 각 이미지의 특징 벡터를 추출하고 가우시안 분포로 변환하여 두 영상 간의 평균과 공분산행렬을 각각 추정하여 두 분포의 차이를 계산한다. 앞서 언급한 것처럼 스타일 변환이란 스타일 변환된 결과 이미지가 대상 이미지의 형태를 보존하면서 스타일 이미지의 분포를 동일하게 만드는 과정으로 진행된다. 따라서 스타일 변환 된 이미지가 대상 이미지와의 FID 값이 작으면 대상 이미지를 스타일 변환시키는 과정에서의 왜곡 발생률이 적은 것을 의미하며, 스타일 이미지와의 FID가 작다면 스타일 이미지와 비슷한 스타일을 갖는 것을 의미한다. 즉, 두 FID 값이 작다면 매우 사실적이며 정밀하게 스타일을 반영된 것이라 평가할 수 있다.
Table 2.
Quantitative evaluation of different networks in terms of FID (Frechet Inception Distance)
| Experiment Image | FID between Target and Results | FID between Style and Results | |||
| Style Image | Target Image | DPST FID | WCT2 FID | DPST FID | WCT2 FID |
| Yutu-2 Fig. 8(c) | Fig. 8(a) | 86.7 | 54.3 | 113.2 | 87.9 |
| Fig. 8(b) | 98.2 | 61.8 | 143.8 | 101.6 | |
| Apollo-11 Fig. 8(d) | Fig. 8(a) | 78.1 | 44.8 | 97.6 | 71.5 |
| Fig. 8(b) | 104.9 | 70.1 | 166.3 | 125.9 | |
알고리즘의 정량 성능 평가에 사용된 스타일 이미지는 Yutu-2와 Apollo-11 영상을 사용하였으며 2개의 스타일 이미지와 각 대상 이미지를 교차로 실험을 진행하였다. 스타일 변환된 이미지와 스타일 이미지, 대상 이미지 간의 FID 지표를 비교하였다. Fig. 8(a) 대상 이미지와 Yutu-2 Fig. 8(c) 스타일 이미지를 이용하여 DPST 및 WCT2 모델을 통해 Fig. 9(a)와 Fig. 9(b) 출력 결과를 얻었다. 그리고 Fig. 9(a) DPST 결과 이미지와 대상 이미지의 FID 값을 구하고 스타일 이미지와의 FID 값을 계산하였다. 동일하게 Fig. 9(b) WCT2 결과 이미지와 대상 이미지의 FID 값 및 스타일 이미지 FID 값을 도출하였다. Table 2 결과를 보면 전체적으로 동일한 조건에서 DPST 모델에 비해 WCT2 모델의 FID 지표가 낮은 경향을 나타내었다. 또한, 출력 이미지와 대상 이미지의 FID 값이 스타일 이미지와의 FID 값보다 전체적으로 낮은 경향을 보이는데, 이러한 이유는 스타일 이미지에 비해 대상 이미지의 전체적인 윤곽 정보가 더 많이 내포되어 있기 때문이라 추정된다. 결과적으로 DPST에 비해 WCT2 모델이 사실적으로 스타일을 반영하는 결과를 보였다.
3.2.4 정성적 측면 성능 비교
Fig. 9부터 Fig. 12까지는 Fig. 8의 데이터를 활용해 얻은 DPST 및 WCT2의 스타일 변환 결과다. DPST 결과는 Fig. 9부터 Fig. 12까지의 (a) 그림들이며, WCT2로부터의 결과는 Fig. 9부터 Fig. 12까지의 (b)에 도시하였다. 실험 결과를 보면 DPST 알고리즘은 스타일 반영 시 대상 이미지의 원본 형태가 왜곡되고 뭉개지는 현상이 발생하였다. 이러한 이유는 Pooling 과정에서 입력 영상의 압축 시 일부 정보가 손실되기 때문이다. 그에 반해 WCT2 알고리즘은 Max-Pooling을 Wavelet Pooling으로 변환하여 대상 이미지의 형태 정보를 최대한 보존하면서, 스타일 이미지의 스타일 정보만 효과적으로 반영되는 결과를 볼 수 있다. 따라서 매우 사실적인 스타일 변환이 수행되었다고 판단할 수 있다.




3.3 소결
본 실험에서는 스타일 변환 기법을 통해 취득하기 어려운 환경의 배경 정보를 대상 이미지에 반영하고자 진행하였다. 이에 따라, 지형정보화 기술 실험부지에서 취득된 영상을 실제 달 지형 영상처럼 스타일 변환하는 실험을 수행하였다. 2 종류의 스타일 변환 알고리즘을 통해 생성된 인공데이터와 스타일 이미지 간의 FID 평가지표로 이미지 간의 특징 거리를 측정하였다. 인공데이터와 스타일이미지 간 FID 값이 낮으면 효과적으로 스타일이 반영된 것을 의미하며, 인공데이터와 대상이미지 간 FID 값이 낮으면 원본 영상의 형태 보존이 높은 것을 의미한다. 평가 지표를 통해 윤곽 정보의 왜곡 최소화와 효과적인 스타일 반영 실험 결과를 얻을 수 있었다.
생성된 합성 영상은 실제 달 표면 이미지로 대표하기에는 힘드나, 실제 달 표면 영상과 매우 유사하게 생성되었음을 정량적, 정성적 평가지표를 통해 확인하였다. 향후 실제 달 표면에서 영상 센서 기반 무인 로버 지형정보화 연구를 위해서는 실제 현장에서의 주요 객체(크레이터, 암석, 더미)의 인식 정확도가 중요하다. 이에 따라, 본 연구의 최종 목표는 실제 달 표면에서의 로버 운영 시 객체 인식 초기 대응력을 최대로 높이기 위한 연구로써 인공 데이터의 생산 및 반영으로 보다 성능이 좋은 인공지능 모델 구현을 위한 추가 학습영상 확보 방안으로 활용될 수 있을 것이라 예상한다.
4. 결 론
본 연구에서는 인공지능 영상처리 분야 중에 하나인 객체 인식 및 영역 분류 기법 사용 시 발생하는 데이터 부족 및 불균형에 따른 객체 인식 정확도 저하의 한계를 극복하기 위해 스타일 변환 기법을 활용하여 데이터 생성 기법의 적용성 검토 연구를 진행하였다. 효과적인 합성 영상 생성을 위해 Mask 위치정보를 제공하는 스타일 변환 알고리즘을 이용하였다. 또한, 기존 CNN 과정에서 정보 손실이 크게 발생하는 pooling 단계의 단점을 보완하기 위해 웨이블릿 풀링 기법인 4채널(LL, LH, HL, HH)으로 세분화한 정보 반영으로 대상 이미지 형태의 훼손을 최소화하였으며, 스타일 이미지의 스타일을 효과적으로 반영해 매우 사실적인 이미지 생성 결과를 얻을 수 있었다. 그 결과, 스타일 변환 기법을 통해 달 표면과 같이 수집하기 힘든 데이터를 매우 사실적으로 생성해내어 현장 확보 한계 등으로 충분한 대상객체와 가능한 다양한 배경 환경이 내포된 실제 학습 영상을 구성하는데 당면하게 되는 한계를 해결할 수 있는 가능성 또한 확인할 수 있었다.
사실상, 달 현장과 같이 접근하기 힘든 대상 현장에서도 인공지능 객체인식을 위해서는 대상객체와 다양한 환경(배경) 영상으로 잘 조합된 실제 영상을 확보하고 학습에 반영하는 것이 최선책이다. 하지만, 빈번히 당면하게 되는 상황이지만 완벽한 학습용 영상을 확보하기 어려울 때, 필요로 하는 영상을 인위적으로 생산하여 학습에 반영하는 방법은 인공지능 객체인식 성능 발현에 효과적인 차선책이 될 수 있을 것으로 사료된다.
일반적으로 인공지능으로 현장의 암반객체들을 자동 인식하는데 있어서, 대상 객체와 다양한 환경(배경)이 잘 조합되어 있는 풍부한 학습영상의 확보 여부가 인공지능 객체인식 성능을 좌우한다. 이에, 본 논문에서 고찰된 영상처리기법들이 인공지능 학습을 위한 영상 확보를 위해 효과적으로 대응할 수 있는 방법으로 활용될 수 있을 것으로 기대한다. 특히, 접근하기 힘든 달 현장뿐만 아니라, 일반적인 암반구조물 현장에서도 악천후 조건(눈, 비, 안개)과 같은 다양한 환경에서 목표 암반객체를 포함한 영상 확보에는 시간과 비용이 많이 소요된다. 이러한 경우에 매우 경제적으로 영상 확보 문제에 대응할 수 있는 방법으로 활용될 수 있다.
