

1. 서 론
건설 및 광업 분야에서는 암반 굴착을 위한 발파작업이 빈번하게 수행된다. 발파작업이 수행되면 비석 날림(flyrock), 지반 진동(ground vibration), 대기 소음(air overpressure) 등이 발생하여 주변의 환경과 사람에게 피해를 줄 수 있으므로 각별한 주의가 필요하다(Coursen, 1995, Chen and Huang, 2001, Gad et al., 2005). 특히, 발파작업으로 인해 발생하는 진동은 인접 지역 건축물의 구조적 안정성에 영향을 미칠 수 있으며, 이로 인한 분쟁은 심각한 사회적 갈등을 유발할 수 있다(Lee, 2017). 따라서 발파 설계 시 지반 진동의 발생 규모를 예측하여 피해를 예방하는 것은 건설 및 광업 분야의 재해방지 측면에서 매우 중요하다.
발파진동의 전파 특성을 이론적으로 해석하기 위해 진동을 유발하는 영향 인자와 이격거리에 따른 진동속도(peak particle velocity, PPV)의 상관관계를 분석한 연구가 다수 수행되었다(Morris, 1950, Habberjam and Whetton, 1952, Duvall and Fogelson, 1962, Devine and Duvall, 1963, Attewell et al., 1965, Ambraseys and Hendron, 1968, Dowding, 1971, Gustafsson, 1973, Ghosh and Daemen, 1983, Roy, 1991, Agrawal and Mishra, 2019). 그 결과 기존의 연구들은 지발당 최대장약량과 폭원으로부터의 이격거리를 영향 인자로 설정하여 PPV를 예측할 수 있는 다음과 같은 경험식을 제시하였다.
여기서 V는 PPV(cm/sec), D는 발파원으로부터의 이격거리(m), W는 지발당 최대장약량(kg/delay), K와 n은 암반 및 발파 조건 등에 따르는 상수를 의미한다. 또한, b는 자승근 환산거리(Square Root Scaled Distance, SRSD)를 사용할 경우 1/2, 삼승근 환산거리(Cube Root Scaled Distance, CRSD)를 사용할 경우 1/3을 사용한다. 그러나 이러한 경험식은 암반의 특성, 천공경, 천공장, 최소저항선, 공간격, 화약종류 등 다양한 발파설계 인자들을 고려할 수 없는 한계가 있다(Ghasemi et al., 2013, Hajihassani et al., 2015, Hasanipanh et al., 2015).
이를 극복하기 위해 최근에는 머신러닝 기법을 활용한 PPV를 예측하기 위한 연구가 다수 수행되었다. Monjezi et al.(2012)은 GA(genetic algorithm)을 사용하여 ANN(artificial neural network) 모델을 최적화한 후 PPV를 예측하는 연구를 수행하였고, Armaghani et al.(2018)은 두 가지 방정식(quadratic, power)을 이용하여 진동을 예측할 때 ICA(imperialist competitive algorithm)의 타당성을 평가하는 연구를 수행하였다. Nguyen et al.(2020a)은 발파로 인한 PPV를 진동 센서를 통해 측정하여 입자 군집 최적화 알고리즘(PSO, particle swarm optimization), GA, ICA 및 ABC(artificial bee colony) 알고리즘을 포함한 다양한 진화 알고리즘을 사용하여 최적의 알고리즘을 제안하였다. 그 밖에도 SVM(support vector machine), CART(classification and regression tree), kNN(k-nearest neighbors), XGBoot 등 머신러닝 알고리즘을 사용하여 PPV를 예측하기 위한 다수의 연구가 수행되었다(Zhou et al., 2016, Nguyen et al., 2019b, Xu et al., 2019, Nguyen et al., 2020b, Shang et al., 2020, Zhang et al., 2020, Choi and Lee, 2021). 그러나 머신러닝 기법을 활용해 PPV를 예측한 기존의 연구들은 시험발파를 통해 획득한 매우 적은 수의 데이터를 이용한 한계가 있다. 최근에는 머신러닝 모델을 개발 시 고려하는 발파설계 인자의 수가 점차 증가하고 있는 추세이다(Table 1).
Table 1.
Number of data and factors considered in previous studies for predicting peak particle velocity using machine learning models
| Reference | Chandar et al., 2017 | Nguyen, 2019 | Nguyen et al., 2019b | Fang et al., 2020 | Nguyen et al., 2020a | Nguyen et al., 2020b | Shang et al., 2020 | Zhang et al., 2020 | Bui et al., 2020 | |
| Number of data | 168 | 157 | 68 | 125 | 125 | 185 | 83 | 175 | 83 | |
| Factor | Maximum charge per delay | x | x | x | x | x | x | x | x | x |
| Monitoring distance | x | x | x | x | x | x | x | x | x | |
| Burden | x | x | x | x | x | x | ||||
| Spacing | x | x | x | x | x | x | ||||
| Powder factor | x | x | x | x | ||||||
| Bench height | x | x | ||||||||
| Stemming | x | |||||||||
| Number of holes | x | |||||||||
| Hole length | x | |||||||||
| Ratio of emulsion | ||||||||||
본 연구의 목적은 국내 석산 개발 현장에서 2012년 9월부터 2019년 8월까지 수집된 1048개의 발파진동 데이터를 활용하여 발파시 발생하는 PPV를 예측할 수 있는 머신러닝 모델을 개발하는 것이다. 다양한 발파설계 인자를 고려하여 kNN, CART, SVR (support vector regression), PSO-SVR 알고리즘을 이용한 4종의 머신러닝 모델을 개발하였고, 모델의 예측 성능 비교를 통해 최적의 머신러닝 모델을 제안하였다.
2. 연구지역
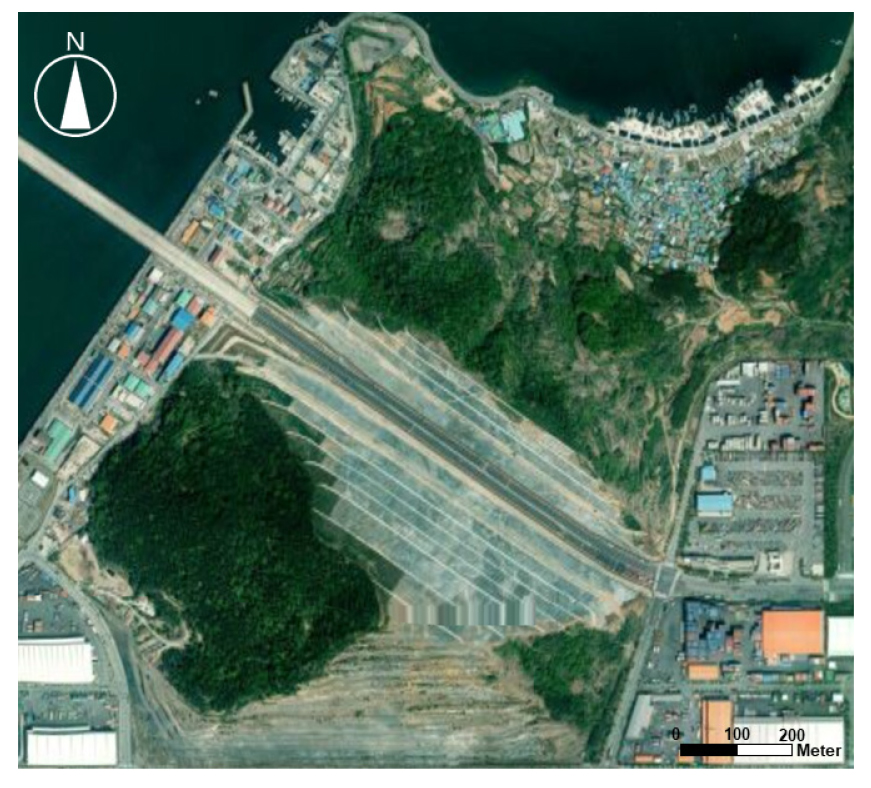
연구지역은 대한민국 경상남도 창원시 진해구에 위치한 욕망산(35°05'12"N 128°47'24"E)으로 선정하였다(Fig. 1). 욕망산은 해발고도 193.8 m이며, 지형의 경사는 산지의 정상부와 연결되는 부분에서는 20~30°로 비교적 완만하지만, 해안선을 따라 형성된 지역은 30~40°의 가파른 지형 경사를 나타낸다. 산지와 능선 부분에 화산암인 안산암과 유문암이 분포하며, 해안을 따라 상부로 관입된 화강암이 산상으로 분포하고 있다(Lee et al., 2001). 현재는 부산 신항 컨테이너터미널과 도로 조성 등을 위해 일부 절취된 상태로 높이는 150 m이다. 연구지역에서는 2022년부터 2033년까지 12년간 부산 신항 북 컨테이너 2단계 항만 배후단지 조성사업이 진행될 예정이다. 연구지역의 석산을 개발을 통해 토사(200만 m2)와 석재(4000만 m2)를 채취해 진해 신항(부산 제2 신항) 공사를 위한 골재로 사용하고, 개발 부지 면적 52만 2565만 m2는 항만 배후단지로 사용될 것이다.
3. 연구방법
3.1 모델 설계 및 데이터 전처리
본 연구에서는 머신러닝을 이용하여 PPV를 예측하기 위한 머신러닝 모델의 학습데이터를 8개의 입력변수와 1개의 출력변수(PPV)로 구성하였다(Table 2). 데이터는 연구지역에서 2012년 9월 20일부터 2018년 8월 22일까지 총 4612회 발파가 시행되었을 때 획득한 데이터로, 활용 가능한 발파설계 정보는 천공장, 저항선, 공간격, 최대지발장약량, 비장약량, 총공수, 에멀전비율, 이격거리로 총 8가지 항목이다. 연구지역에서는 발파 시 에멀전과 안포(ANFO)를 혼합한 화약을 사용하였으며, 장약된 화약에서 에멀전이 차지하는 비율을 기록하였다. 수집된 데이터 중 누락되었거나 일부 속성값이 이상치를 보이는 데이터를 제외하면, 머신러닝 모델 개발에 활용 가능한 유효데이터 수는 1048개였다. 연구에 사용된 유효데이터의 기초 통계량은 Table 2와 같다. 학습데이터 세트로 훈련한 머신러닝 모델을 검증하기 위해 전체 데이터를 학습데이터 세트와 테스트 데이터 세트로 나누었으며, 학습데이터는 전체 데이터 세트의 80%로 설정하고 테스트 데이터 세트는 전체 데이터 세트의 20%로 설정하였다.
Table 2.
Description of data set for training machine learning models and basic statistics of data set used in this study
3.2 머신러닝 모델 학습 및 적용
PPV 예측에 가장 적합한 모델을 개발하기 위해 머신러닝 알고리즘 4종류를 학습시킨 후 최적의 모델을 선정하였다. 4종류의 머신러닝 알고리즘은 kNN, CART, SVR, PSO-SVR을 이용하여 비교하였다.
∙kNN : 머신러닝 모델 중 직관적이며 간단한 지도학습 모델 중 하나로 분류 및 회귀 문제에 사용할 수 있는 모델이다(Quiros et al., 2017). kNN은 학습을 미리 하지 않고 새로운 데이터의 작업 요청이 수신되었을 때 학습을 수행한다. 따라서 인스턴스 기반 러닝, 메모리 기반 러닝 혹은 레이지 러닝이라고도 한다. 유사한 점을 가정하여 다른 위치에 대한 예측을 수행하는 모델이다(Elevado et al., 2018). 예측값은 훈련 데이터에서 k(neighbors)개의 표본을 선택한 후 가장 가까운 이웃을 기준으로 정의된다. 따라서 예측 정확도는 이웃 수를 의미하는 k값에 따라 달라지며, k값에 가장 가까운 거리를 계산하는 데 사용되는 거리에 따라 달라진다(Pandya et al., 2013).
∙CART : Decision tree를 기반으로 사용하는 모델이며, 분류와 회귀 문제에 모두 적용이 가능한 머신러닝 모델이다. CART는 변수 간의 관계에 대한 이전 가정을 고려할 필요가 없다. 데이터는 반복적인 절차를 통해 예측 변숫값에 대한 답변(예/아니오)을 기반으로 균일한 레이블로 분할되며 최종적으로 이항 트리가 생성된다. 이 과정을 시각화를 통해 이해 및 해석하기 쉽고, 자료를 가공할 필요가 없다는 장점이 있다. 종속변수가 정성적이면 분류 트리(classification tree)라고 하고, 정량적이면 회귀 트리(regression tree)라고 한다. 전체 데이터 세트를 포함하는 노드를 루트 노드라고 하는데, 루트 노드로부터 시작하여 좌우로 나뉘며 데이터 분류는 종속변수와 관련된 추정오차가 최소화될 때까지 반복된다(Hasanipanah et al., 2017).
∙SVR : SVM은 제한된 샘플의 수를 일반화하기 위해 구조적 위험을 최소화하는 원칙에 기초한 머신러닝 알고리즘이다(Cortes and Vapnik, 1995). SVM은 분류 및 회귀 문제에 사용될 수 있으며 회귀 문제의 경우 SVR(support vector regression), 분류 문제의 경우 SVC(support vector classification)라고 표현한다. SVR은 제한된 범위 안에서 가능한 많은 데이터가 들어가는 회귀선을 찾는 원리로 회귀를 수행한다. 선형 회귀가 아닌 경우에는 커널(kernel) 함수를 이용하여 가상의 차원을 추가하여 계산하며, RBF(radial basis function) 커널을 이용한 SVR은 예측 모델을 최적화하기 위해 조정할 수 있는 매개변수로서 C와 gamma를 조절할 수 있다(Alpaydin E., 2020). 경계를 결정하는 회귀선이 확정되면 학습용 데이터는 불필요하며 예측의 정확도가 높고, 사용이 편리하다는 장점이 있다.
∙PSO-SVR : SVR의 매개변수를 최적화하기 위해 입자 군집 최적화(PSO, particle swarm optimization) 알고리즘을 결합한 모델이다. 입자 군집 최적화 알고리즘은 날아가는 새 떼와 같은 입자/사회적 동물의 행동에 기초를 두어 군집의 다양성을 모사한 효율적인 최적화 기법이며, Eberhart and Kennedy(1995)에 의해 개발되었다. 입자 군집 최적화 알고리즘은 군집지능(swarm intelligence)에서 영감을 받은 계산 알고리즘이다. 군집지능은 입자 환경에서의 인구 또는 균질한 협력 때문에 발생하며, 각 입자가 임의의 시작 위치와 특정 크기를 갖는다고 가정한다. PSO-SVR에서는 입자는 SVR의 매개변수인 C와 gamma를 뜻한다. 식 (2)을 이용하여 속도(v)를 계산하고, 계산된 속도를 사용하여 위치(x)를 식 (3)을 이용하여 계산한다. 각 입자가 영역을 돌아다니면서 최적의 매개변수 위치를 공유해서 수렴하는 매개변수를 찾게 된다(Nugraha et al., 2019).
모델의 성능을 평가할 때 전체 데이터 세트의 크기가 작을 경우, 데이터 세트의 일부를 검증 데이터 세트로 사용하여 성능을 평가한다면 검증 데이터 세트에 대한 성능 평가의 신뢰성이 떨어지는 단점이 존재한다. 이러한 단점을 보완하기 위해 k겹 교차 검증(k-fold cross validation)을 활용하여 보완할 수 있다. k겹 교차 검증은 훈련 데이터 세트를 k개로 나누어 k-1개로 학습을 하고 1개의 검증 데이터 세트를 사용하여 학습과 검증 평가를 반복적으로 수행하는 방법이다. k겹 교차 검증을 수행하면 가지고 있는 데이터의 100%를 검증 데이터 세트로 사용할 수 있다는 장점이 있다. 본 연구에서는 5겹 교차 검증(5-fold cross validation)을 활용하여 머신러닝 모델을 학습시킨 후 테스트 데이터를 통해 최종 머신러닝 모델을 선택하였다.
머신러닝 모델의 성능을 평가할 수 있는 성능지표로는 회귀에서 일반적으로 사용되는 MAE(mean absolute error), MSE(mean squared error), RMSE(root mean squared error)를 사용했다. 사용된 지표는 실제값과 예측값의 차이가 작으면 작을수록 예측 성능이 좋은 머신러닝 모델로 평가된다. MAE는 평균 절대 오차로 실제값과 예측값의 차이를 절댓값의 평균값을 사용한 지표로 식(4)을 통해 계산할 수 있다. 는 번째 샘플의 모델의 예측값이고, 는 번째 샘플의 레이블을 의미한다. 절댓값이기 때문에 오차의 방향을 알지 못하지만, 오차의 크기를 비교하는 지표이다. MSE는 평균 제곱 오차로 실제값과 예측값의 차이를 제곱하여 평균값을 사용한 지표로 식 (5)를 통해 계산할 수 있다. RMSE는 MSE의 제곱근으로 오차의 크기를 살펴보는 지표이다. MSE는 오류의 제곱을 구하므로 실제 오류 평균보다 더 커지는 특성이 존재하여 RMSE를 계산한다(식 (6)).
4. 연구결과
본 연구에서는 4종류의 알고리즘을 사용하여 PPV를 예측하기 위한 머신러닝 모델을 개발하였다. 알고리즘별로 최적의 머신러닝 모델 개발을 위해 학습 데이터(전체 데이터의 80%, 838개)를 이용하여 각 모델의 매개변수들을 변화시키면서 5겹 교차 검증을 수행하였다. kNN 모델의 경우 매개변수인 neighbors를 1부터 300까지 1씩 증가시키며 모델의 최적화를 수행하였다. CART 모델은 트리의 복잡도를 조절하는 depth를 0부터 100까지 1씩 증가시키며 모델의 최적화를 수행하였다. SVR 모델의 경우에는 C와 gamma의 값을 0.001부터 1000까지 10배씩 증가시키며 모델의 최적화를 수행하였다. PSO-SVR 모델은 PSO 알고리즘에 따라 최적화가 진행되었으며 C와 gamma의 범위를 최소 0.001, 최대 1000으로 설정하였다.
Fig. 2는 머신러닝 모델 최적화 결과를 보여준다. 최적화 수행 결과 kNN 모델은 neighbors가 1부터 52일 때까지 MSE가 감소하지만 53일 때부터 증가하였다. 따라서 neighbors = 52일 때 MAE의 값이 0.046(cm/s)로 가장 작았다. CART 모델을 depth가 6까지는 MSE가 감소한 것을 확인할 수 있으며, depth = 6일 때 가장 성능 좋은 CART 훈련 결과(MAE = 0.044 cm/s)를 도출하였다. SVR 모델의 경우 gamma가 작을수록 모델의 정확도가 향상되었으며 C가 100일 때 전체적으로 높은 정확도를 보였다. C = 100, gamma = 0.001일 때 가장 좋은 훈련 결과를 도출하였다(MAE = 0.042 cm/s). PSO 알고리즘을 통해 최적화된 PSO-SVR 모델은 C = 824.2174, gamma = 22.85305일 때 가장 좋은 훈련 결과를 보였다(MAE = 0.040 cm/s).

최적화 결과를 통해 결정한 매개변수를 머신러닝 모델에 적용하여, 테스트 데이터(전체 데이터의 20%, 210개)를 이용하여 모델의 성능을 비교하였다. 성능을 비교하기 위해서 실제 데이터와 예측 데이터 간의 오차를 이용하여 전체적인 추세와 성능지표(MAE, MSE, RMSE)를 비교하였다. 4가지 모델 모두 한 값에 집중되어 있지 않고 편향되지 않은 것을 확인할 수 있다(Fig. 3).
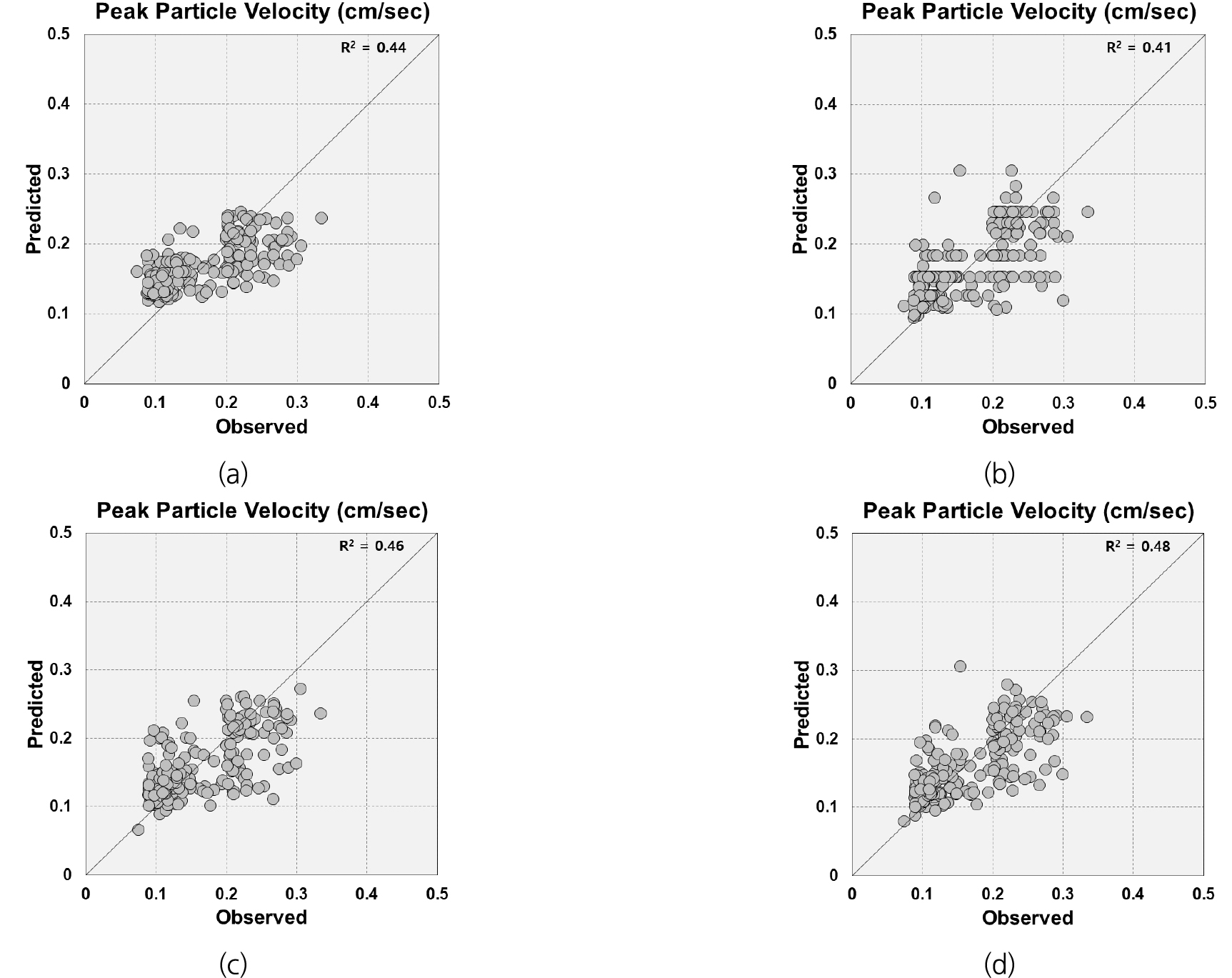
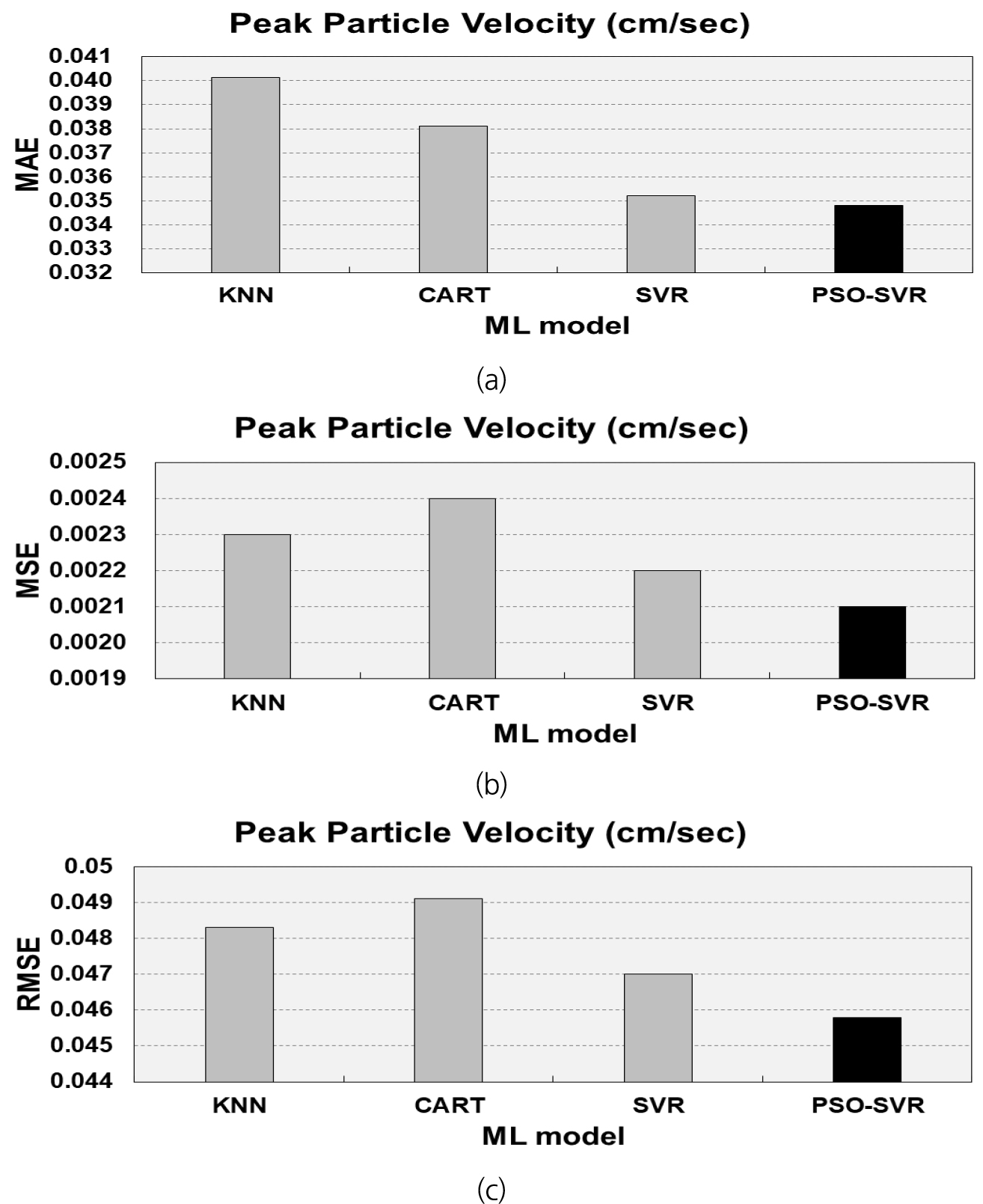
Fig. 4는 4종의 알고리즘으로 훈련된 머신러닝 모델의 성능지표를 비교한 결과이다. kNN 모델의 성능지표는 MAE가 0.0401(cm/s), MSE가 0.0023(cm/s), RMSE가 0.0483(cm/s)으로 나타났다. CART 모델은 MAE가 0.0381(cm/s), MSE가 0.0024(cm/s), RMSE가 0.0491(cm/s)을 보였다. SVR 모델의 성능지표는 MAE가 0.0352(cm/s), MSE가 0.0022(cm/s), RMSE가 0.0470(cm/s)였다. 마지막으로 PSO-SVR 모델은 MAE가 0.0348(cm/s), MSE가 0.0021(cm/s), RMSE가 0.0458(cm/s)로 나타났다. 실제값과 예측값의 추세가 PSO-SVR 모델이 가장 잘 따르는 것을 확인하였으며, 3가지 성능지표 모두 PSO-SVR 모델이 가장 우수한 것으로 나타났다.
5. 토 의
본 연구에서 개발한 PSO-SVR 모델의 예측 성능지표 값을 기존 연구들의 결과와 비교해보았다(Table 3). 연구지역, 사용된 데이터의 수, 고려한 발파설계 인자의 종류 등에서 차이는 있으나 본 연구에서 제시한 모델의 예측 성능은 기존의 연구들과 유사한 수준을 보임을 확인할 수 있었다.
Table 3.
Comparison of prediction performance with existing studies
| Chandar et al., 2017 | Nguyen,2019 | Nguyen et al., 2019a | Nguyen et al., 2019b | Fang et al., 2020 | Nguyen et al., 2020a | Nguyen et al., 2020b | Shang et al., 2020 | Zhang et al., 2020 | Bui et al., 2020 | this study | |
|
Machine learning algorithm | ANN | SVR | XGBoost | ANN |
ICA- M5Rules |
ICA- SVR |
HKM- ANN |
FFA- ANN |
PSO- XGBoost |
FCM- QRNN |
PSO- SVR |
| MAE | 0.0405 | 0.0135 | - | 0.0405 | 0.0175 | 0.0580 | - | 0.0356 | 0.0346 | 0.0237 | 0.0348 |
| MSE | 0.0508 | 0.0396 | 0.1742 | 0.0508 | 0.0258 | 0.1045 | 0.0554 | 0.0464 | 0.0583 | 0.0348 | 0.0458 |
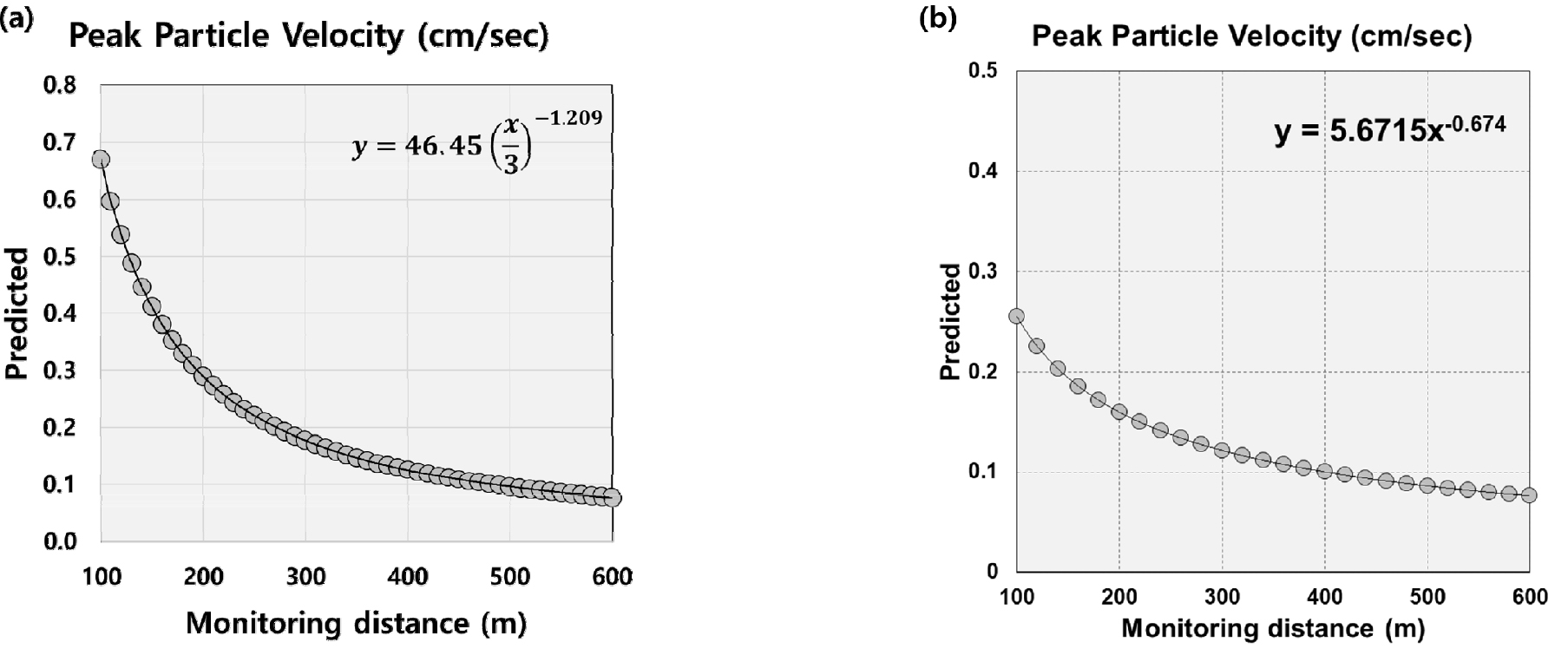
기존의 연구들은 개발된 머신러닝 모델의 활용방안을 제시하지 않았다. 본 연구에서는 개발된 PPV 예측 머신러닝 모델의 활용방안을 제시하기 위해 Table 4와 같은 발파 시나리오를 고려하였다. 먼저 기존 연구에서 사용되었던 경험식 (1)에 따라 Table 4의 지발당 최대장약량과 폭원으로부터의 이격거리를 영향 인자로 설정하여 PPV를 예측한 결과는 Fig. 5(a)와 같다. Table 4의 발파설계 인자 값을 PSO-SVR 모델에 입력한 후 이격거리를 100 m부터 600 m까지 20 m 간격으로 설정하여 PPV를 예측한 결과는 Fig. 5(b)와 같다. 그 결과 이격거리가 300 m 이상 될 때는 PPV 예측값에 큰 차이를 보이지 않았다. 이격거리 300 m 이하에서는 PSO-SVR 모델의 예측결과가 경험식 (1)의 예측결과보다 PPV가 다소 작게 나타났다.
Table 4.
Example of blast design for predicting peak particle velocity using the PSO-SVR model.
|
Hole length (m) |
Burden (m) |
Spacing (m) |
Maximum
charge per delay (kg) |
Powder factor (kg/m3) |
Number of holes |
Ratio of emulsion | |
| Scenario | 6.8 | 2.2 | 3.1 | 9 | 0.22 | 20 | 1 |
국내 발파작업표준안전작업지침 제2장 제1절 제5조에 따르면 발파구간 인접 구조물에 대한 피해 및 손상을 예방하기 위하여 PPV를 기준을 실정에 따라 허용범위를 하향 조정해야 한다(Table 5). 연구지역에서 시나리오와 같이 설계 인자를 결정하게 된다면 주변에 문화재가 있는 경우 문화재까지의 거리가 약 150m 이상 되어야 발파를 진행할 수 있다고 판단된다.
6. 결 론
본 연구에서는 욕망산을 연구지역으로 설정하여 천공장, 저항선, 공간격, 최대지발장약량, 비장약량, 총공수, 에멀전비율, 이격거리를 고려하여 PPV를 예측할수 있는 머신러닝 모델을 개발하였다. 최적의 머신러닝 모델을 선정하기 위해 4종의 머신러닝 모델을 학습시킨 후 성능을 비교하였다. 전체 데이터의 80%를 이용하여 모델들을 학습시키고 나머지 20% 데이터를 이용하여 성능을 검증한 결과, kNN, CART, SVR, PSO-SVR 모델 중 PSO-SVR이 MAE = 0.0348(cm/s), MSE = 0.0021(cm/s), RMSE = 0.0458 (cm/s)로 가장 좋은 성능을 보였다. PSO-SVR 모델의 예측 성능은 기존 연구들과 비교할 때 유사한 수준으로 나타났다.
머신러닝 기법을 활용해 PPV를 예측한 기존의 연구들은 시험발파를 통해 획득한 매우 적은 수의 데이터(최대 185개)를 이용했으나 본 연구에서는 실제 석산 개발 현장에서 약 6년간 수집된 1048개의 데이터를 이용하여 머신러닝 모델을 개발하였다. 또한, 머신러닝 모델이 다양한 발파설계 인자들을 고려할 수 있도록 하였으며, 기존 연구에서는 제시되지 않았던 모델의 활용방안을 제시했다는 점에서 가치가 있다고 판단된다. 그러나 연구지역이 아닌 다른 지역에서도 사용할 수 있는 범용적인 PPV 예측 모델을 개발하기 위해서는 다른 지역의 데이터를 추가로 확보하고 머신러닝 모델의 예측 성능을 개선하기 위한 지속적인 연구가 필요할 것이다.
